
流水的運維,鐵打的鍋

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-06-08 21:24:551459瀏覽

在6 月5 號,唯品會發布了23 年3 月29 號的故障報告,因為南沙IDC 冷凍系統故障導致唯品會線上商城停止服務,造成了數以億計的損失(作為小運維的我,瑟瑟發抖)。
對於唯品會來說,線上商城是其核心業務入口,故障不可避免,但是故障如此之長卻不能容忍,為什麼會造成這種事情發生呢?在我們這種小運維的眼裡,這種事故不應該發生在這種量級的公司中,我們都是在模仿、學習他們的 PPT 中尋找運維之路。
但是,PPT 的高大上,無法壓住故障不發生,這是為什麼呢?
我個人鬥膽說幾個猜測:
- PPT≠ 現實
- 故障演練=走過場?
- 多活,說說而已?
- 巧婦難為無米之炊
PPT≠ 現實
現在國內各種技術大會,然後邀請一些知名企業的CTO、技術負責人等到場演講,從演講來看,每家公司都很強(至少PPT 上是這樣展示的),每次我聽完都會豁然開朗,大受裨益,打心底佩服這些公司,佩服他們超強的思維、超高的能力以及超酷的團隊。
但是,PPT 畢竟只是一個輔助工具,它不能取代現狀。
漂亮的 PPT 只是給想看的人看的,不漂亮的事情是要獨自去承受的。
之前有看多唯品會在GOPS 上的分享,PPT 上呈現的確實很棒,如果拿著這個向上匯報,老闆也會覺得我們公司的技術真厲害,做的真好,給了老闆一切都很好的假象。
出了問題,不辦你辦誰?
從自己嘴裡吹出去的牛逼,也會回到自己嘴裡。
故障演練=走過場?
在《SRE:Google 維運解密》這本書中,故障演練佔了很大的篇幅。透過故障演練,可以提高系統的可靠性和容錯性,可以讓團隊更好的了解系統的架構和工作原理,可以更好的理解各模組的相互影響,可以更快的發現系統架構中的漏洞和故障。
可以說,故障演練是整個穩定性保障的核心環節,因為它可以幫助團隊最大限度的減少實際故障的同時,也能更有效率的應對可能出現的問題。
但是,實際上是這樣的麼?
在實際進行故障演練的時候,要預定故障點,要整理輸出具體的應對措施,要指定全面的計劃,要準確描述每個人的工作職責和任務。
光這些前置工作就需要耗費很大的人力物力,很多團隊、很多人就會精簡步驟、精簡措施,抱著做了就行的心態看待故障演練,抱著僥倖心態看待故障本身,把希望寄託在別人不出問題的情況下。
例如把希望寄託於公有云,公有云不出問題,整個系統就是穩定的,但是公有云≠ 完全可靠,谷歌雲、阿里雲、騰訊雲等都發生過重大事故,然而買單的還是使用者自己。
所以,對於維運團隊或SRE 團隊,需要認真對待故障演練,不僅要做好演練的前置準備工作,在演練中也要密切關注計劃,發現問題及時採取措施並進行修正。
不要讓演練成為走過場,不要讓演練成為 KPI,不然你就是下一個最佳化物件。
多活,說說而已?
3 月 29 日唯品會的問題,可以從側面反映:多活,也許真是說說而已。
隨著業務的發展,系統架構會不斷演變,因為我們對高可用的要求越來越高。
例如,從單機架構在同一機房升級到主備架構,再升級到同城多機房架構,最後到達兩地三中心架構等級。
如果唯品會做了同城多機房,就算最簡單的同城主備,也不至於宕機 12 小時。
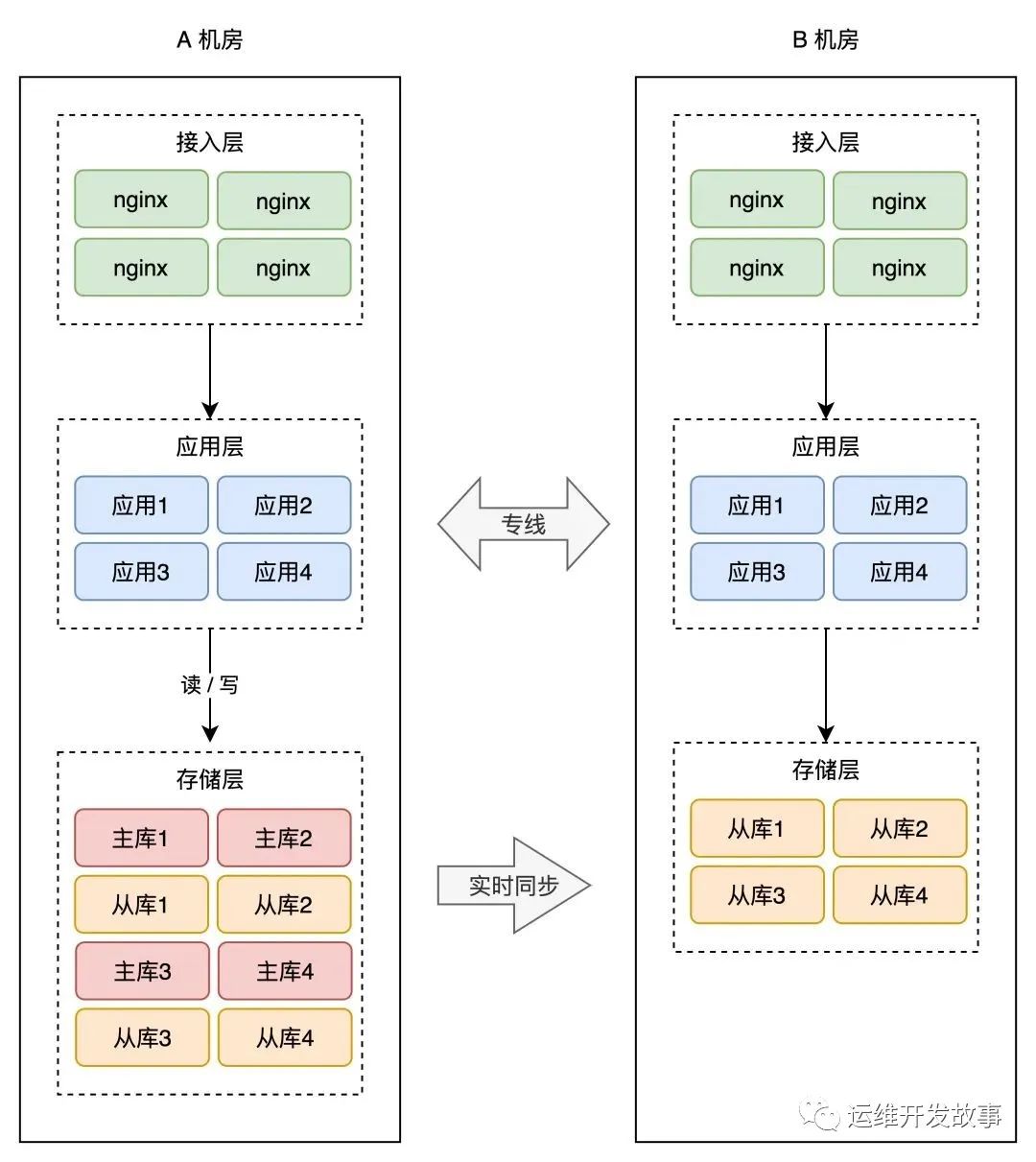
更別說如果做了同城雙活。
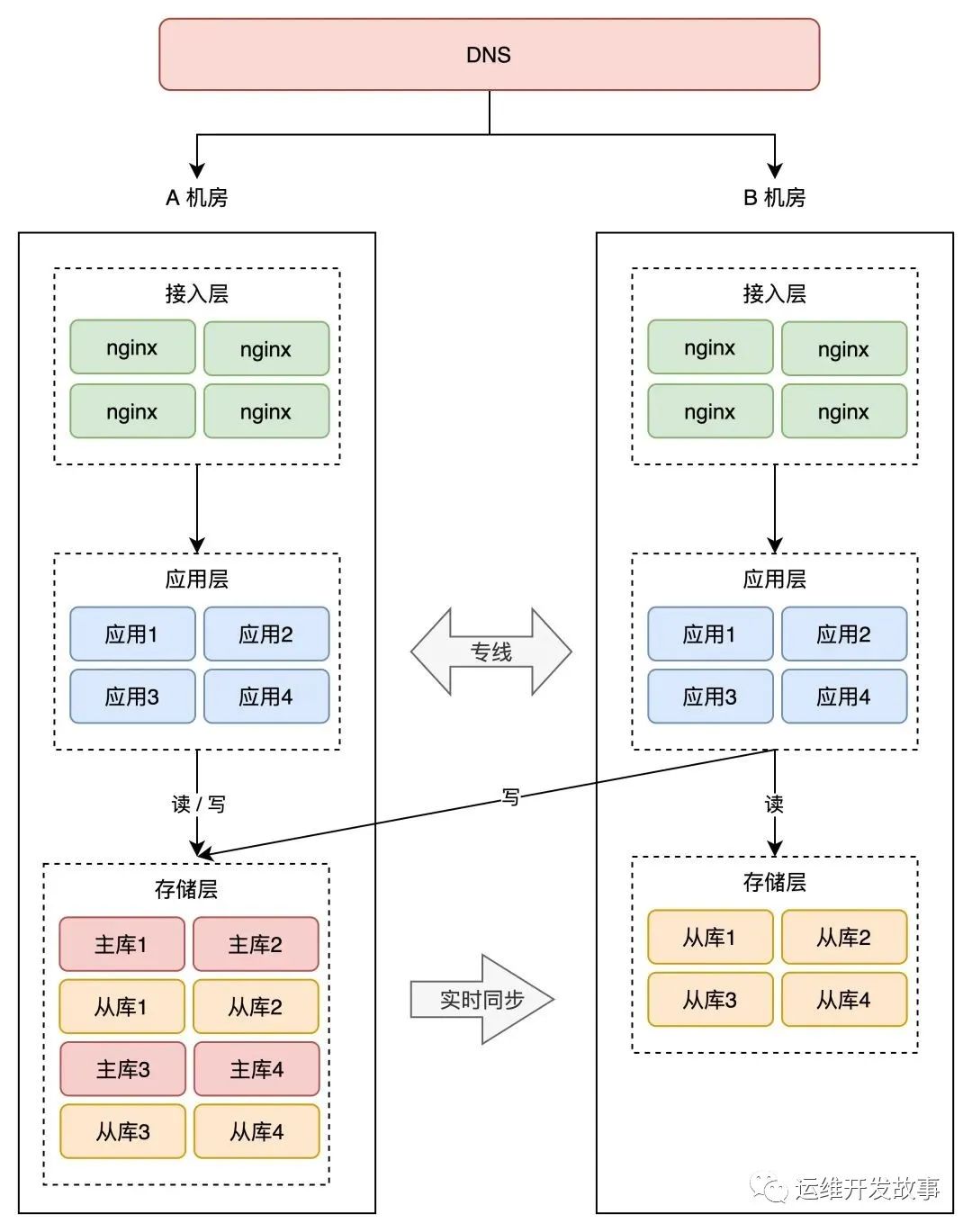
但是,我只是站在上帝視角猜測。也許他們也做了多活,只是假多活罷了。
巧婦難為無米之炊
上面總總,到頭來都會走到財力、人力、物力上來,就拿多活來說,搞一個同城災備,投入的成本就不是dubbo 那麼簡單,每當SRE 負責人向上報告申請資金的時候,如果上面的領導不予支持(錢,錢沒掙,還要花這麼多),什麼都是白搭。
領導要壓成本,下面要錢做事,成本不足導致入不敷出,也就會出現 PPT 漂亮,實際很爛的局面。
縱有一腔抱負,乃無用武之地。
出了問題,還要用你祭天。
最後
上面所說純屬虛構,如有雷同,請按讚~
在許多公司,維運的話語權很低,低到離譜,這就導致維運在做事或推進事情的時候寸步難行。
但是,一旦出現問題,維運卻是被第一個推出來的,所以「背鍋俠」一直被扣在維運頭上。
那當作運維該怎麼做呢?
- 走出去-不要侷限於維運團隊內部,要走出去,讓業務部門知道維運的價值。
- 走進去-維運知識體系複雜多變,要走進知識內部,深度理解背後的原理,用你的專業來為團隊服務。
- 走上去-要提升維運影響力,透過專業的能力和積極的態度爭取更多的信任和支持,改變現狀,提升地位。
最後,說歸說,鬧歸鬧,別拿生產開玩笑。
以上是流水的運維,鐵打的鍋的詳細內容。更多資訊請關注PHP中文網其他相關文章!