
Mysql Innodb儲存引擎之索引與演算法的範例分析

- 王林轉載
- 2023-06-03 12:44:13922瀏覽
一、概述
索引太少,查詢效率低;索引太多程式效能受到影響,索引的使用應該貼合實際情況。
Innodb 支援的索引包括:
全文檢索,使用倒排索引
哈希索引,自適應,不能人為幹預,依據緩衝池中的聚集索引頁創建,並不會將整張表進行哈希索引,所以建立索引非常快。
B 樹索引,傳統意義上的索引,目前關係型資料庫中最有效且最常用的索引。
B 樹並不能定位到表上具體的行記錄,而是返回該行記錄所在的頁;最後在內存中根據slot槽信息,以及行記錄頭中的next record 資訊進行精確定位。
二、資料結構與演算法
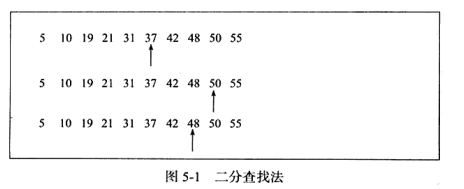
1、二分查找
二分查找只能用來對一組有序的線性資料進行查找,每次取中位數,小往前,大往後。在有序數組中找出數字48的時間複雜度為log N,如下圖所示。
2、二元尋找樹與平衡二元樹
1)二元尋找樹
二元找出樹指的是,一個二元樹中,都滿足:任意節點左子節點比自身小,任意節點右子節點大於自身的二元樹,即為二元尋找樹。
普通的二元樹無法保證 O(logN) 的存取時間,因為當極端情況下,它甚至可以退化成鍊錶。
當把一組有順序的資料依序建構一個二元樹,那麼就得到了一個鍊錶,此時時間複雜度變成:O(N)
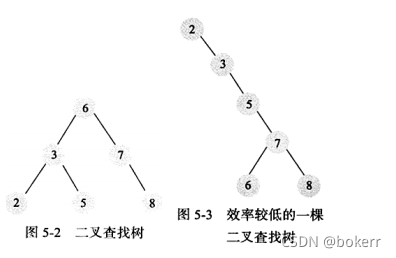
2)平衡二元樹
平衡二元樹與二元搜尋樹相似,但加入了一個限制條件:每個節點的左右子樹高度最多相差1。在建構二元樹的過程中,如果破壞了這個條件,可以透過適當的旋轉來解決。
平衡二元樹保證了時間複雜度為:O(logN)
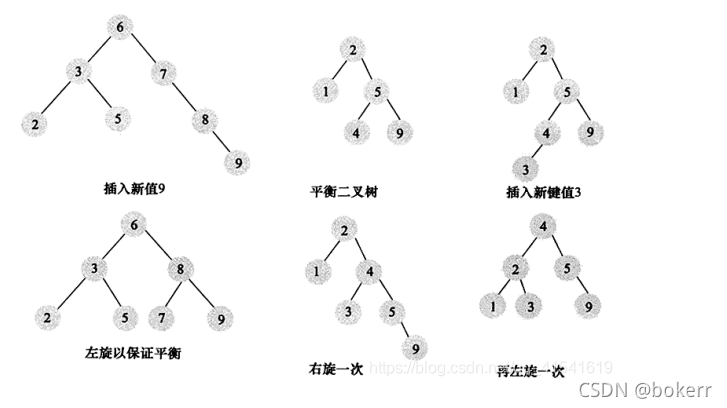
雖然能保證O(logN) 的存取時間,但它並不適合用來做資料庫索引:
當資料量非常大時,二元樹的高度會迅速增加(例如,1024等於2的10次方),因此log(N)也非常顯著。
多次進行磁碟IO是由於二元樹的葉子節點只能容納一個數據,這是它最不利的特點。然而實際應用中相較於CPU的執行指令的時間,頻繁讀取磁碟將是災難性的。所以,二元樹並不適合用來做資料庫的索引。
對於機械硬碟,其存取時間取決於磁碟轉速和磁頭移動時間,這都是由機械結構完成的,對比cpu 中執行的電信號指令,速度必定天差地別。
1000萬數據,如果使用平衡二元樹(最壞時間界限為1.44 * logN ),即便不取最壞時間界,按log(N) 計算最終約為24,那麼說明需要進行24 次磁碟IO,這顯然不行。
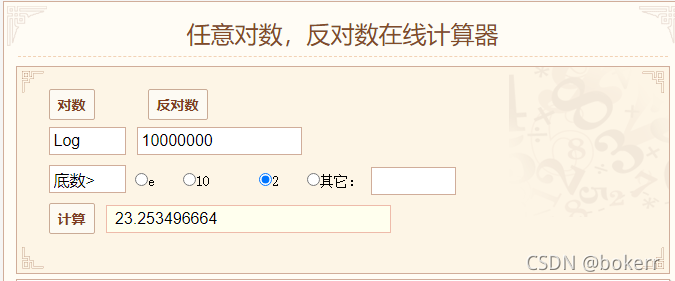
【樹高為對數值向上取整,例如:log3 = 1.58,樹高為2;】
三、B 樹
由於平衡二元樹的限制,所以需要引進B 樹。
B 樹是專為磁碟或其它直接存取輔助設備設計的一種平衡查找樹,B 樹中,所有記錄節點都是按鍵值大小, 順序存放在同一層的葉子節點上,由各葉節點指標進行連結。
1、B 樹完整定義
一顆M階的B 樹需要滿足如下的性質:
下列所有定義中的關於兩數相除,不能整除時往上取整,而不是丟棄小數位。 (案例中推演不等式除外)
1)資料項必須存在葉子節點上
2)非葉節點存貯M-1個關鍵字以指示搜尋方向;關鍵字i 代表非葉節點的第i 1 棵子樹中最小的關鍵字;假設5階B 樹,那麼它有5 - 1 = 4 個關鍵字。
3)B 樹要麼只有一個樹葉節點作為根節點(沒有任何兒子節點);如果它有兒子節點,它的節點數必須屬於集合:{2~M};
4)除根外,所有非葉節點的兒子節點數必須滿足屬於集合: { M/2 ,M } ;
5)所有樹葉都在相同深度上,且樹葉節點的資料項個數字必須屬於集合:{ L/2 ,L } ;
2、關於M 和L的選定案例
假定所有字段總長不超過500字節,以50字節主鍵為例,模擬推導B 樹,包括行記錄本身所佔用的空間
已知所有行記錄都會消耗一些位元組記錄行資訊:例如變長字段,行記錄頭,事務ID,回滾指標等等。
create table context( id varchar(50) primary key, name varchar(50) not null, description varchar(360) );
一個葉子節點代表的是一個資料頁,M 和L 值的選擇跟他息息相關,假設資料頁大小為:P/位元組(以本文討論的MySQL為例,一個資料頁大小為16K 也就是16384 個位元組。)
非葉節點上:B 樹的關鍵字是主鍵,本例假設主鍵為50 個位元組,M階B 樹的關鍵字為M -1個,佔用:50 * (M - 1)個位元組的空間;
再加上它指向M 個子節點的分支指針,假定每個分支指針佔用4個位元組儲存;那麼一個非葉節點中,所有空間消耗共計:50 * (M - 1) 4 * M = 54M - 50位元組。
當使用MySQL,且假設主鍵50個位元組,成立不等式: 54M - 50
葉子節點上,已知表中定義的每個行的容量的最大為: 500 字節,這時成立如下表達式:L * 500
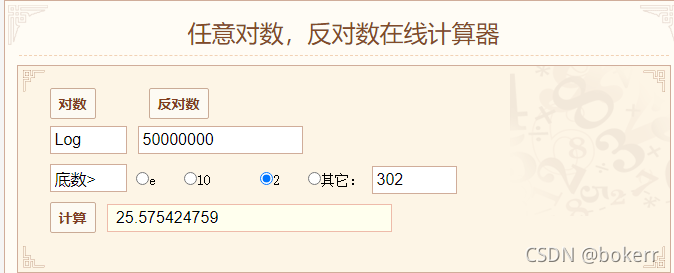
如下圖,此時5000W數據,樹高大於3,表示我們只需要最多4次磁碟IO就能查到數據。
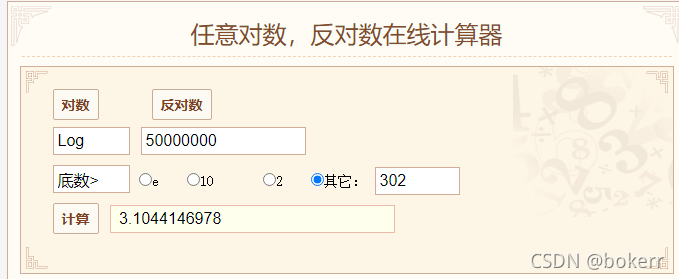
參考下圖,平衡二元樹最壞時間界為:1.44 * logN = 25.58 * 1.44 = 36.83;也就是說5000W 資料若使用平衡二元,樹最壞情況下會超過36 次磁碟IO,最少26次磁碟IO。
如圖為一顆5 階普通B 樹(M = 5),此處每個節點最多5個值(L = 5); M和L不一定相等,就如上述分析而言: M 和L視實際情況而定。
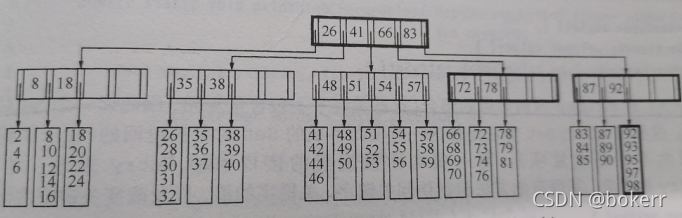
哈哈哈畫圖太麻煩了,我從資料結構與演算法分析這本書上拍的照片,機智如我。
這裡只講B 樹定義以及參數選取詳情,B 樹的插入、B 樹的刪除部分類容不在贅述。
四、B 樹索引
一般B 樹樹高為2~4 層,也就是查找行記錄時一般只需要2 ~ 4 次磁碟IO就能找到行記錄所在的頁。不論聚集索引或非聚集索引,內部都是高度平衡的,索引的資料都存放於葉子節點,區別是聚集索引的葉子節點存放了整個行記錄資料。
1、聚集索引
聚集索引的葉子節點存放整行數據,每張表只能擁有一個聚集索引。
2、輔助索引
輔助索引的葉子節點儲存了鍵值和一個書籤,該書籤告訴Innodb 儲存引擎從哪裡可以找到於索引對應的行記錄完整資料。
每張表可以有多個輔助索引
輔助索引的一個缺點是必須透過離散的聚集索引獲取完整的行數據,即使已經找到了輔助索引存儲的書籤。
五、關於 Cardinality 值
對於Cardinality的討論都是基於非聚集索引的,每個非聚集索引都會有一個Cardinality值。
1、Cardinality定義
須知並不是所有查詢條件中的列都需要加索引;例如:性別、年紀、科目等取值範圍小、密集分佈的字典量,就不需要建立索引。
Cardinality 表示索引中不重複記錄數量的 預估值 ,一般: Cardinality / 表中記錄行數 應盡量接近 1;如果非常小,則需要考慮該索引是否應該去掉。 (聚集索引中該值必定接近1,沒有討論價值)。
2、Cardinality的更新
MySQL中由於各儲存引擎對於B 樹索引的實作各不相同,所以Cardinality 的統計是在儲存引擎層實現的。
當表中資料量非常巨大時,對Cardinality 進行統計是非常耗時的,它的統計一般使用採樣的方法來進行。
Cardinality 的存在,可以幫助我們很好的分析索引是否有存在的意義。
六、B 樹索引的使用
【 本部分討論的索引多指輔助索引,對聚集索引的查詢一般稱為全表掃描。 】
1、聯合索引
聯合索引是在表格上的多個欄位上建立索引,它也是B 樹結構,與單一索引的差異僅是它存在多個欄位。
create table t ( a int, b int, primary key (a), key idx_ab (a, b) )engine=innodb;
上表中,設定聯合主鍵idx_ab,其儲存結構如下所述:
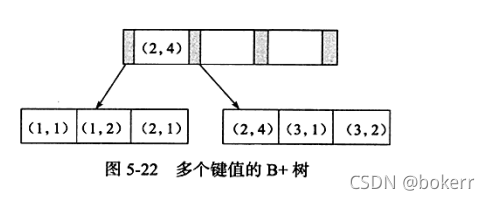
如上图所述,键值有序,需要注意的是,如下SQL可以使用该索引:
select * from t where a = ? and b = ? select * from t where a = ?
如下sql 不能使用该索引;查看示例图中联合索引叶子节点存放的数据我们可以发现:两个叶子节点上,关于字段b的存放显然不是有序的。
select * from t where b = ?
联合索引本身还有一个好处,辅助索引本身已经对第二个键值进行了排序,如下语句可以避免多一次的排序。
select b from t where a = ? order by b desc
辅助索引中已经对 b 列进行了排序,所以此时使用辅助索引更高效。
2、覆盖索引
Innodb 支持覆盖索引(covering index,或称为索引覆盖),即从辅助索引中就可以得到结果,而不需要查询聚集索引中的记录。由于辅助索引不包含完整的行记录,从而比聚集索引小很多,可以极大地减少IO操作。
再形如:select count(*) from table name where b = ? 的sql,如果有满足条件的辅助索引,它会优先使用辅助索引因为辅助索引体积远远小于聚集索引。
3、优化器选择不使用索引的情况
某些情况下,通过EXPLAIN指令会发现一些SQL,并没有选择使用满足条件的辅助索引去查数据,而是直接选择了全表扫描(聚集索引),这种情况一般发生于 范围查找、join链接操作等情况下。
当发生此类查找时,一般是查找一个较大范围内的数据,当范围较大时同样意味着大量的数据需要再进行一次书签访问去获取完整数据,已知顺序读取速度大于离散读取速度,所以此时不会使用辅助索引,而是直接查聚集索引(整表扫描)。一般情况下,当访问数据超过表中数据总数的20%时,索引覆盖不再适用,而需要进行全表扫描。)
create table t ( a int, b int, primary key (a,b), key idx_a (a) )engine=innodb;
如上定义表,a和b两列构成联合索引,列a上有独立的辅助索引,对于语句:
select * from t where a >= 3 and a<= 1000000;
按理说,该语句是可以选择使用辅助索引 idx_a 进行查找的,但是通过执行 explain 发现该语句发生了全表扫描(聚集索引),而不是使用辅助索引: idx_a。
4、索引提示
索引提示指MySQL支持在SQL中显式的告诉优化器使用哪个索引。
当优化器选择索引错误,可以手动指定索引。[极小概率事件]
当索引太多时,优化器选择索引的操作时间开销大,此时可以手动指定索引。
使用索引提示的前提是我们自己要对sql的执行非常了解,非常明确该操作能带来更好的效率。
5、Multi-Range Read 优化 (MRR)
MySQL5.6版本开始支持Multi-Range Read (MRR) 优化,它的目的是减少磁盘的离散读,将离散的访问优化为相对有序的访问,它使用于 range ref eq_ref 类型的查询。
1).MRR优化有如下好处:
它使得数据访问变得较为顺序,当根据辅助索引查询时,会将查询结果按照主键排序后,再去聚集索引进行书签查询。
减少缓冲池中页被替换的次数;
批量处理对键值的查询操作;
2).对于 JOIN 和 范围查询,Innodb 中MRR的工作方式为:
将通过辅助索引查询到的数据放到一个缓存中,此时这些数据是按照辅助索引键值排序的;
将缓存中的数据按照主键顺序排序;
根据主键顺序访问实际数据文件;
想象一下,在缓冲池不够大的情况下进行大范围数据查询,会导致数据页频繁被从LRU列表中移除。如果被查询的辅助索引不是按主键排序的,可能会多次发生如下的情况:一个页在同一次查询中被剔出LRU列表后又再次被加载出来。
配置项:read_rnd_buffer_size 用来配置上述描述的键值缓冲区大小,默认为256K;当发生溢出时,执行器只对已经缓存的数据进行排序。
3).对于范围查询:MMR还支持对键值的拆分,将范围查询拆分为键值对进行批量的数据查询.
create table t ( a integer, b integer, primary key (a), key idx_ab (a, b) )engine=innodb;
select * from t where a = 50 and b>= 100 and b<= 20000
由于存在辅助索引 idx_ab,上述sql语句的条件可以拆分为键值对集合:{( 50 , 100 ),( 50 , 101 ),......,( 50 , 20000 )},这样就将范围查询优化为对键值对的查询;否则会进行范围查询,将 b ∈ {100,20000} 的所有数据都取出。
Multi-Range Read 是否启用,由如下参数中的,mrr 和 mrr_cost_based 标记进行控制,mrr标记是 MRR优化的开关。若前者设置为on,后者设置为off表示当满足条件时总是使用MRR优化;若前者设置为 on,后者也设置 on 表示通过 cost base 方式判断是否需要 MRR优化。

6、Index Condition Pushdown 優化(ICP)
ICP優化也從MySQL 5.6 開始支持,它是一種根據索引進行查詢的優化方式,它支持對:range、ref、eq_ref、ref_or_null 類型的查詢進行最佳化。
停用ICP時,儲存引擎層會透過遍歷索引,定位完整的行記錄;然後傳回給資料庫層(Server層),再去為這些資料行進行where條件的過濾。
啟用ICP時,如果where條件可以使用索引,MySQL會把這部分過濾操作放到儲存引擎層,儲存引擎透過索引過濾,把滿足where 條件的資料取出整行數據並返回。使用ICP可以減少儲存引擎層存取行記錄的頻率,同時減少資料庫層(Server層)必須存取儲存引擎的次數。
【使用這個篩選的前提是:這個篩選條件需要是,索引可以覆寫的範圍】
Index Condition Pushdown運作原理如下:
1)不使用ICP時
(1)當儲存引擎讀取下一行時,從輔助索引的葉子節點讀到相關的行記錄,然後使用該記錄的書籤中的主鍵引用,以查詢完整的行記錄傳回給資料庫層(Server層)。
(2) 資料庫層對完整的行記錄進行where條件過濾,如果該行資料符合where條件則使用,否則丟棄。
(3)執行第1步,直到讀完所有符合條件的資料。
2)使用ICP時,如何進行索引掃描
(1)儲存引擎從索引中逐條讀取資料......
(2)存儲引擎從索引讀取資料時,根據索引的key使用where條件過濾,如果該行記錄不符合條件,儲存引擎將會處理下一資料(回到上一個步驟)。只有在滿足查詢條件的時候,才會繼續去聚集索引中讀取完整資料。
(3)最後儲存引擎層會將所有符合查詢條件資料的完整行記錄傳回資料庫層。
(4)資料庫層再繼續使用,沒有被索引覆寫到的where後的查詢條件進行過濾。
以上是Mysql Innodb儲存引擎之索引與演算法的範例分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!