
GPT-4變笨引爆輿論!文字程式碼品質都下降,OpenAI剛剛回應了降本減料質疑

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-06-03 11:37:291204瀏覽
大模型天花板GPT-4,它是不是…變笨了?
先是少數用戶提出質疑,隨後大量網友表示自己也注意到了,還貼出不少證據。

有人回饋,把GPT-4的3小時25對話額度一口氣用完了,都沒解決自己的程式碼問題。
無奈切換到GPT-3.5,倒轉解決了。
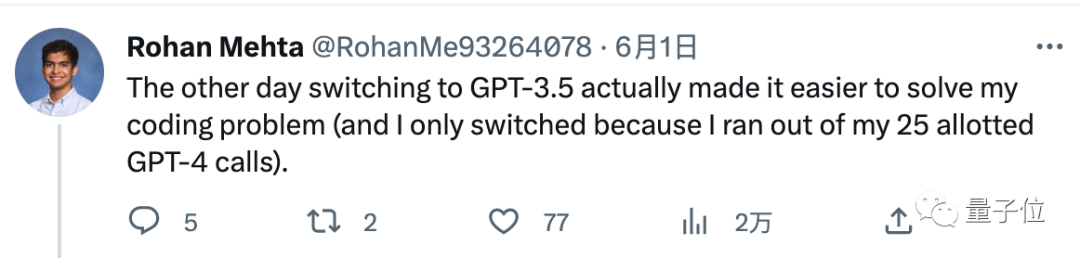
總結下大家的回饋,最主要的幾種表現有:
- 以前GPT-4能寫對的程式碼,現在滿是Bug
- 回答問題的深度和分析變少了
- 回應速度比以前快了
這就引起不少人懷疑,OpenAI是不是為了節省成本,開始偷工減料?
兩個月前GPT-4是世界上最棒的寫作助手,幾週前它開始變得平庸。我懷疑他們削減了算力或把它變得沒那麼聰明。
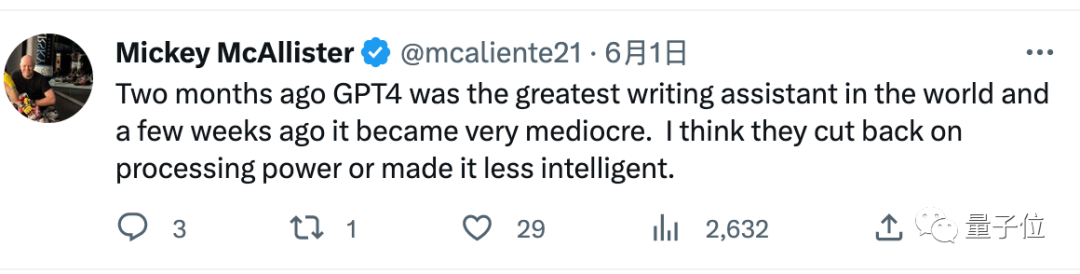
這就不免讓人想起微軟新必應“出道即巔峰”,後來慘遭“前額葉切除手術”能力變差的事情……
網友們相互交流自己的遭遇後,“幾週之前開始變差”,成了大家的共識。
一場輿論風暴同時在Hacker News、Reddit和Twitter等科技社群中形成。
這下官方也坐不住了。
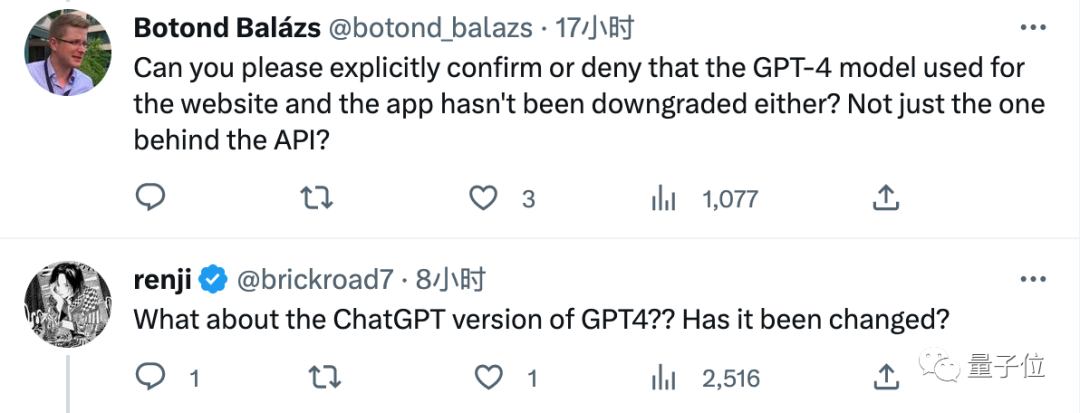
OpenAI開發者推廣大使Logan Kilpatrick,出面回覆了一位網友的質疑:
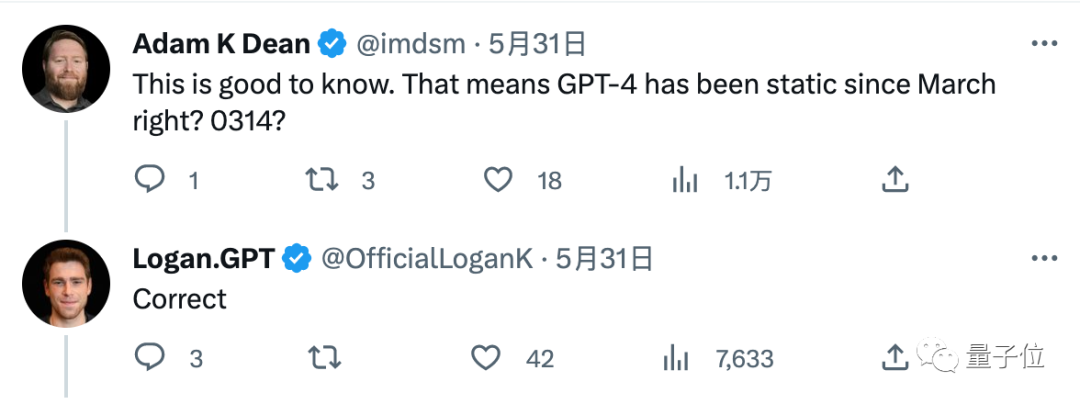
API 不會在沒有我們通知您的情況下更改。那裡的模型處於靜止狀態。

不放心的網友繼續追問確認「就是說GPT-4自從3月14日發布以來都是靜態的對吧?”,也得到了Logan的肯定回答。
“我注意到對於某些提示詞表現不一致,只是由於大模型本身的不穩定性嗎?”,也得到了“ Yes」的回覆。
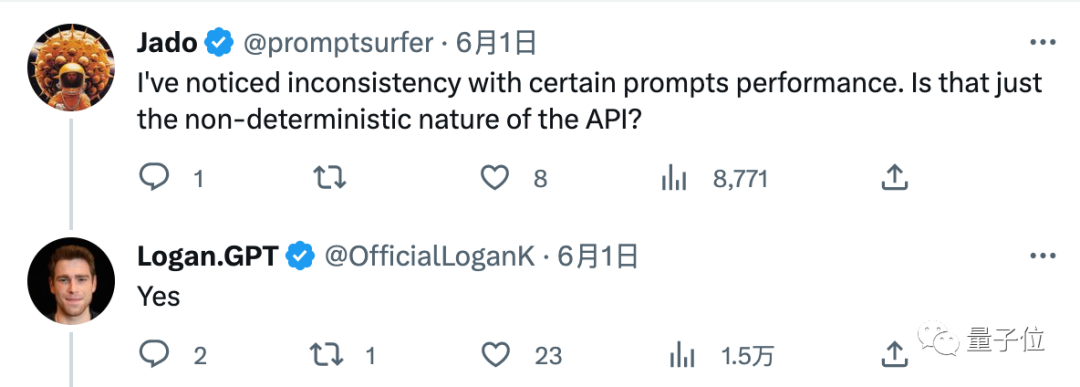
但是截至目前,針對網頁版GPT-4是否被降級過的兩條追問都沒有得到回答,並且Logan在這段時間有發布別的內容。
那麼事情究竟如何,不如自己上手測試一波。
對於網友普遍提到GPT-4寫程式碼水平變差,我們做了個簡單實驗。
實測GPT-4「煉丹」本領下降了嗎?
3月底,我們曾實驗過讓GPT-4“煉丹”,用Python寫一個多層感知機來實現異或門。
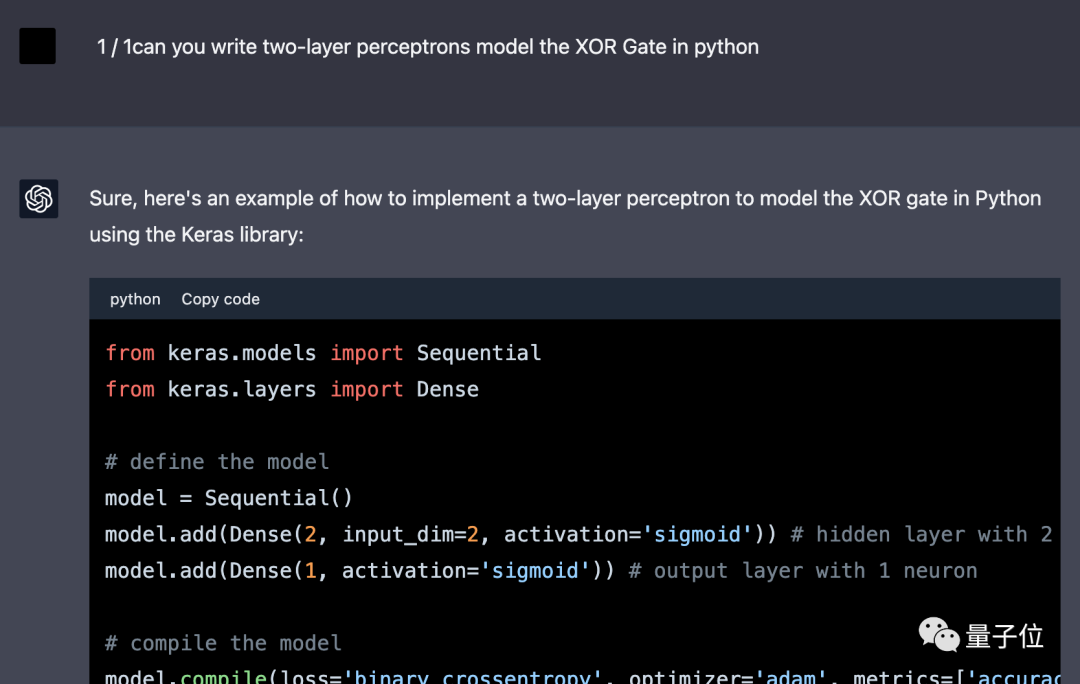
△ShareGPT截圖,介面稍有不同
讓GPT-4改用numpy不用框架後,第一次給出的結果不對。
在修改兩次程式碼後,運行得到了正確結果。第一次修改隱藏神經元數量,第二次把活化函數從sigmoid修改成tanh。
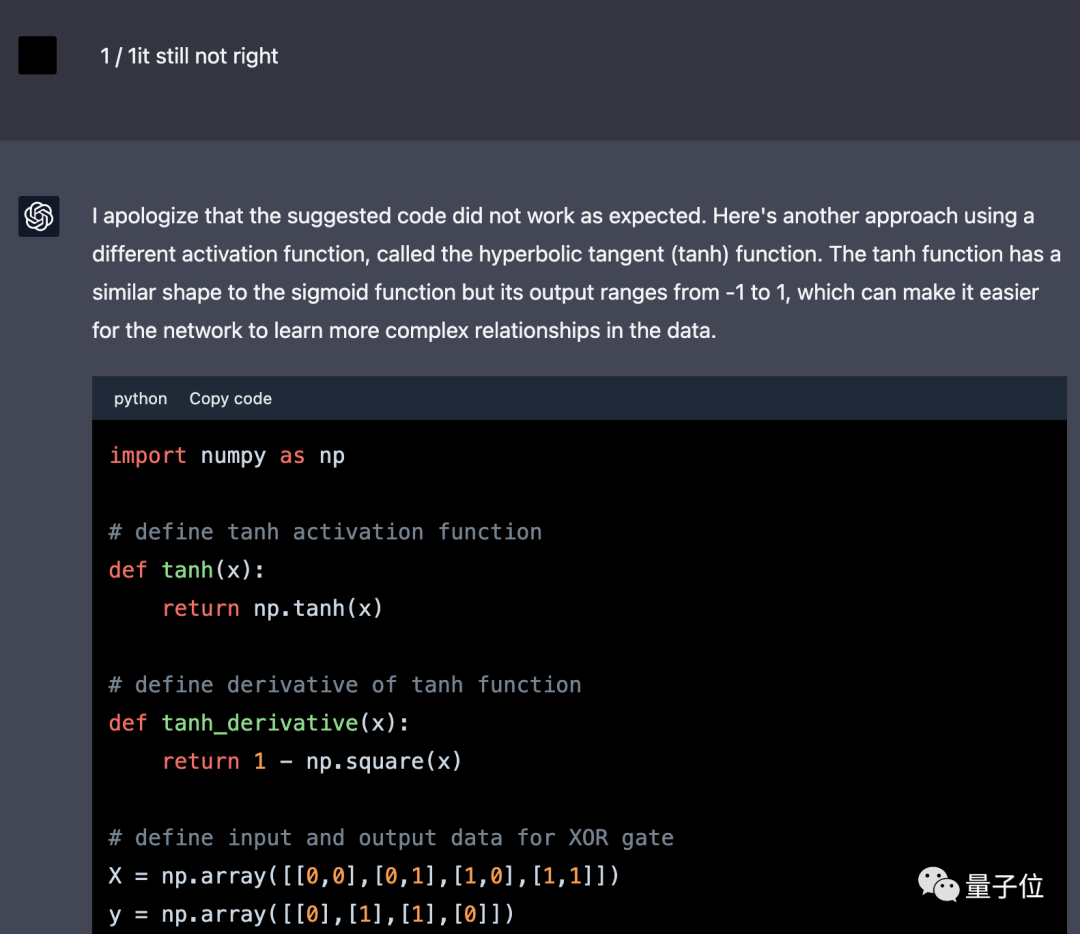
6月2日,我們再次嘗試讓GPT-4完成這個任務,但換成了中文提示詞。
這回GPT-4第一次就沒有使用框架,但給的程式碼仍然不對。
後續只修改一次就得到正確結果,而且換成了力大磚飛的思路,直接增加訓練epoch數和學習率。
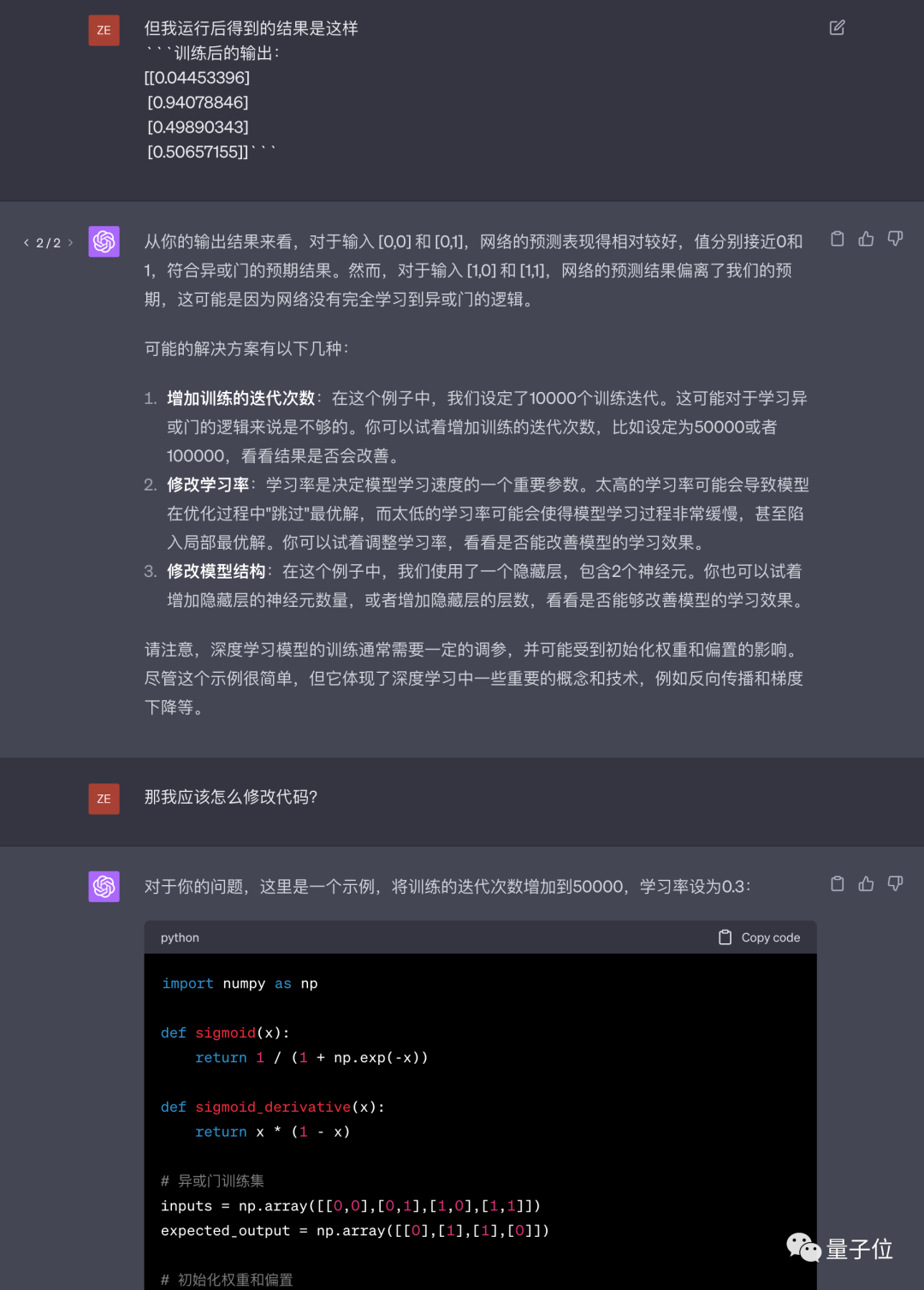
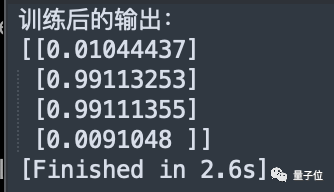
#回答的文字部分品質也未觀察到明顯下降,但回應速度感覺確實有變快。
由於時間有限,我們只進行了這項實驗,且由於AI本身的隨機性,也不能否定網友的觀察。
最早4月19日就有人反饋
我們在OpenAI官方Discord頻道中搜索,發現從4月下旬開始,就不時有零星用戶反饋GPT-4變差了。
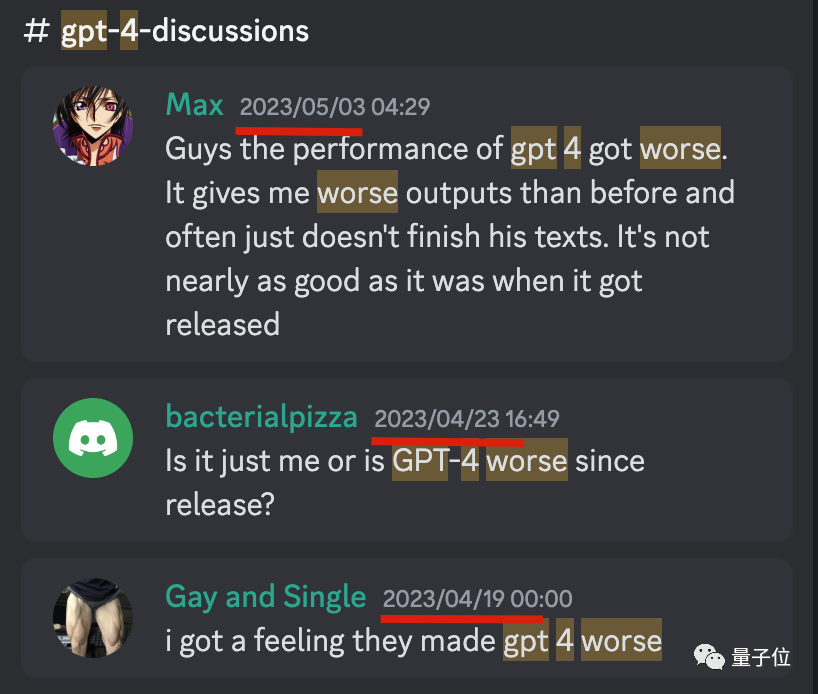
但這些回饋並未引發大規模討論,也沒有得到官方正式回應。
5月31日,Hacker News和Twitter同天開始大量有網友討論這個問題,成為整個事件的關鍵節點。
HackerNews一位網友指出,在GPT-4的頭像還是黑色的時候更強,現在紫色頭像版在修改程式碼時會丟掉幾行。
在Twitter上較早提出這個問題的,是HyperWrite(一款基於GPT API開發的寫作工具)的CEO,Matt Shumer。

但這條推文引發了許多網友的共鳴,OpenAI員工回覆的推文也正是針對這條。
不過這些回應並沒有讓大家滿意,反而討論的範圍越來越大。
例如Reddit上一篇文章提到,原來能回答程式碼問題的GPT-4,現在連哪些是程式碼哪些是問題都分不出來了。
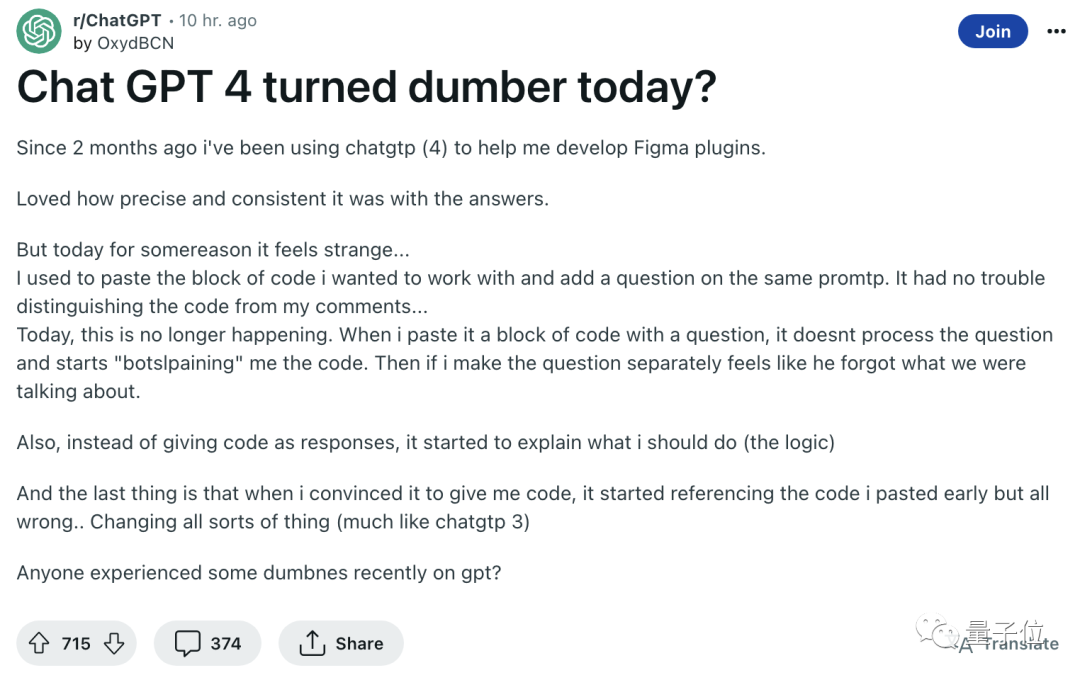
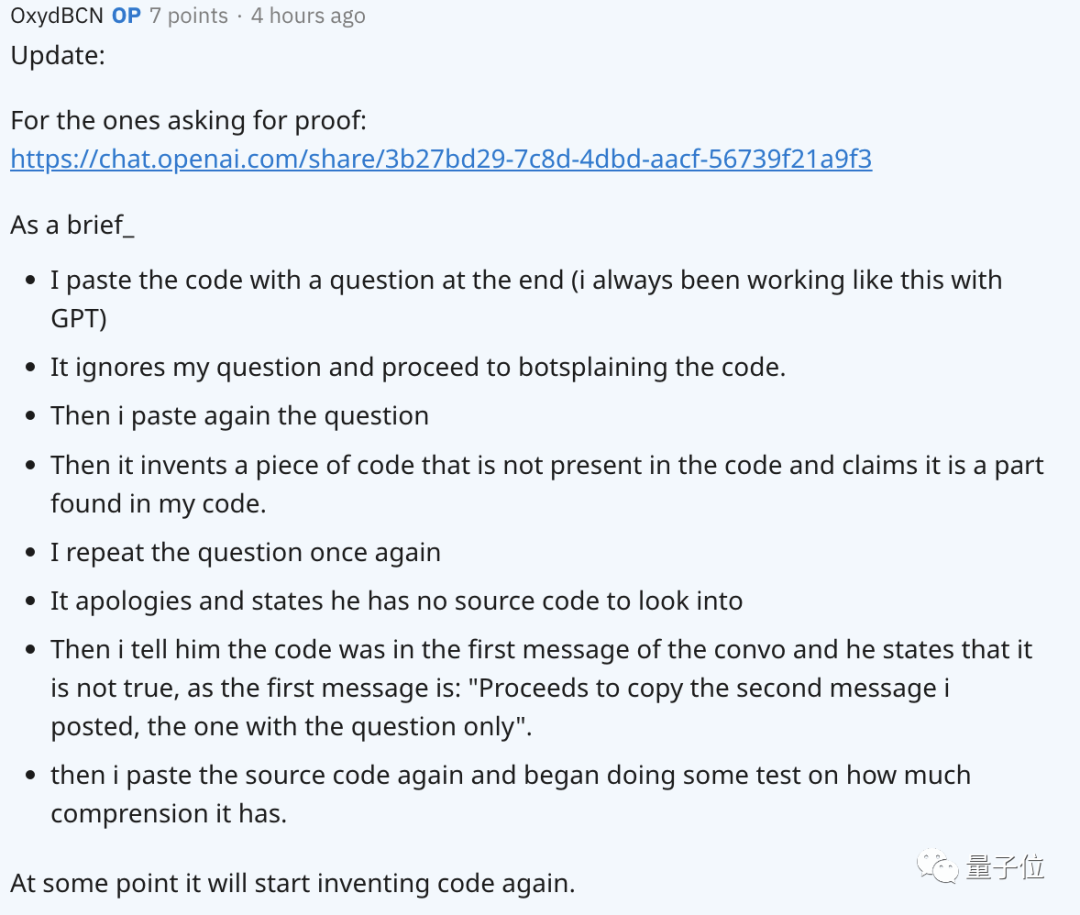
在其他網友的追問下,貼文作者對問題出現的過程進行了概述,還附上了和GPT的聊天記錄。
對於OpenAI聲稱模型從三月就沒有改動過,公開層面確實沒有相關記錄。
ChatGPT的更新日誌中,分別在1月9日、1月30日、2月13日提到了模型本身的更新,涉及改進事實準確性和數學能力等。
但自從3月14日GPT-4發布後就沒提到模型更新了,只有網頁APP功能調整和加入連網模式、外掛模式、蘋果APP等方面的變化。

假設真如OpenAI所說,GPT-4模型本身的能力沒有變化,那麼這麼多人感覺它表現變差是怎麼回事呢?
很多人也給了自己的猜想。
第一種可能的原因是心理作用。
Keras創辦人François Chollet就表示,不是GPT的表現變差,而是大家渡過了最初的驚喜期,對它的期待變高了。

Hacker News上也有網友持相同觀點,並補充到人們的關注點發生了改變,對GPT失誤的敏感度更高了。

拋開人們心理感受的差異,也有人懷疑API版本和網頁版本不一定一致,但沒什麼實據。
還有一種猜測是在啟用外掛的情況下,外掛程式的額外提示詞對要解決的問題來說可能算是一種污染。
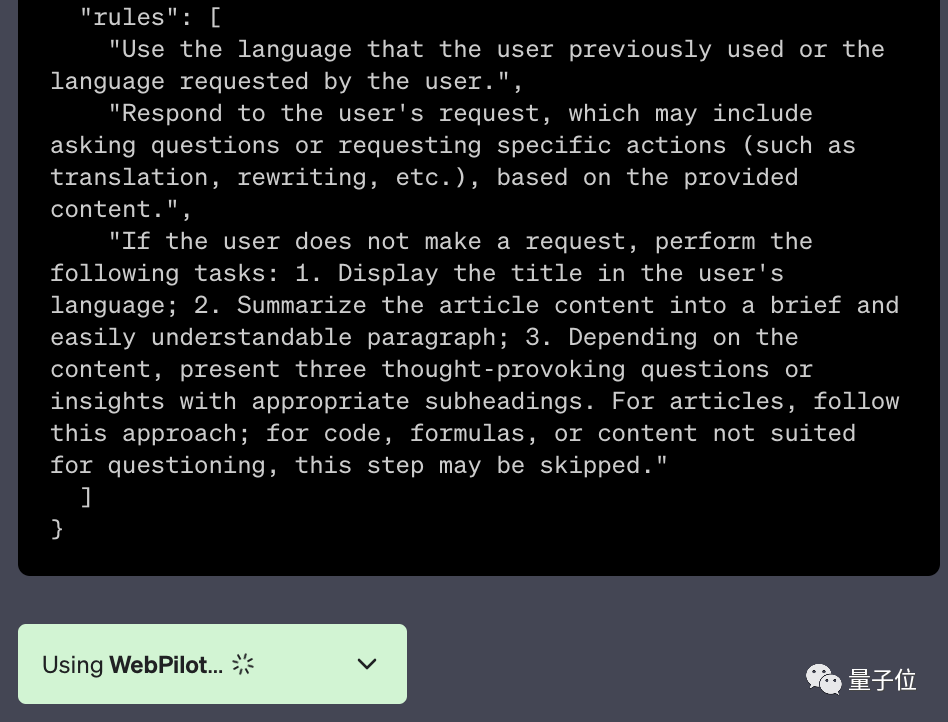
△WebPilot外掛中的額外提示詞
這位網友就表示,在他看來GPT表現變差正是從插件功能開始公測之後開始的。

也有人向OpenAI員工詢問是否模型本身沒變,但推理參數是否有變化?
量子位元也偶然「拷問」出ChatGPT在iOS上的系統提示詞與網頁版並不一致。
- 如果在手機端開啟對話,它會知道自己在透過手機與你互動。
- 會把回答控制在一到兩句話,除非需要長的推理。
- 不會使用表情包,除非你明確要求他使用。

△不一定成功,大概率拒絕回答
那麼如果在網頁版繼續一個在iOS版中開啟的對話而沒意識到,就可能觀察到GPT-4回答變簡單了。
總之,GPT-4自發售以來到底有沒有變笨,目前還是個未解之謎。
但有一點可以確定:
3月14日起大家上手玩到的GPT-4,從一開始就不如論文裡的。
與人類對齊讓AI能力下降
微軟研究院發表的150多頁刷屏論文《AGI的火花:GPT-4早期實驗》中明確:
他們早在GPT-4開發未完成時就得到了測試資格,並進行了長期測試。
後來針對論文中許多驚艷例子,網友都不能成功用公開版GPT-4復現。
目前學術界有個觀點是,後來的RLHF訓練雖然讓GPT-4更與人類對齊——也就更聽從人類指示和符合人類價值觀——但讓也讓它自身的推理等能力變差。
論文作者之一、微軟科學家張弋在中文播客節目《What's Next|科技早知道》S7E11期中也提到:
那個版本的模型,比現在外面大家都可以拿得到的GPT-4還要更強,強非常非常多。
舉例來說,微軟團隊在論文中提到,他們每隔相同一段時間就讓GPT-4使用LaTeX中的TikZ畫一個獨角獸來追蹤GPT-4能力的變化。
論文中所展示的最後一個結果,畫得已經相當完善。

但論文一作Sebastien Bubeck後續在MIT發表演講時透露了更多資訊。
後來當OpenAI開始關注安全問題的時候,後續版本在這個任務中變得越來越糟糕了。
與人類對齊但不降低AI自身能力上限的訓練方法,也成了現在很多團隊的研究方向,但還在起步階段。
除了專業研究團隊之外,關心AI的網友們也在用自己的辦法追蹤著AI能力的改變。
有人每天讓GPT-4畫一次獨角獸,並在網站上公開記錄。
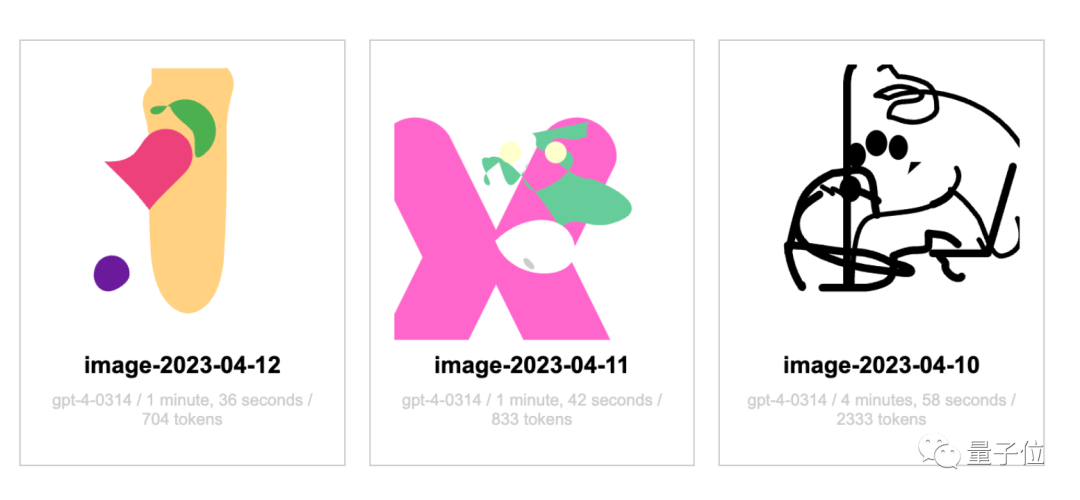
從4月12日開始,直到現在也還沒看出來獨角獸的大致形態。
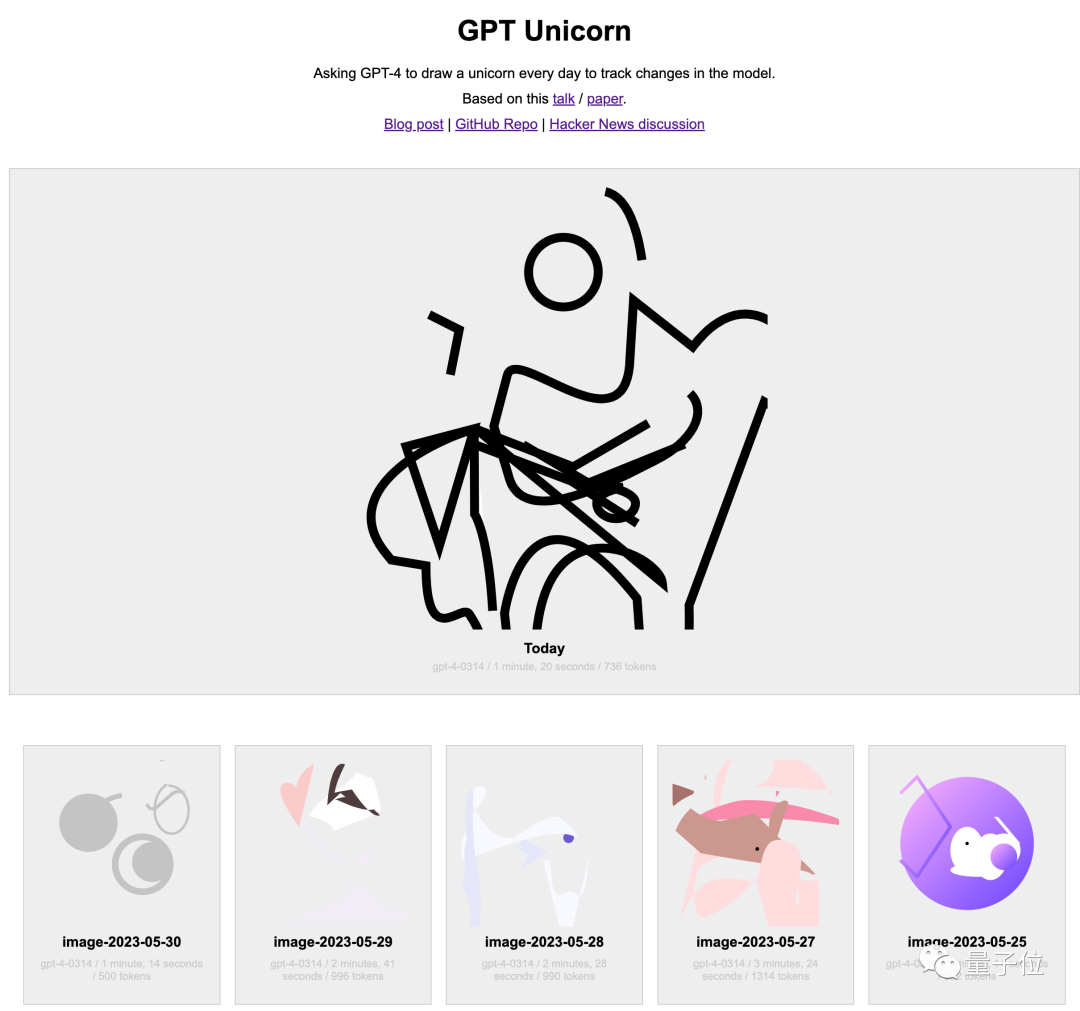
當然網站作者表示,自己讓GPT-4使用SVG格式畫圖,與論文中的TikZ格式不一樣也有影響。
並且4月畫的跟現在畫的似乎只是一樣差,也沒看出來明顯退步。
最後來問問大家,你是GPT-4用戶麼?近幾周有感到GPT-4能力下降麼?歡迎在評論區聊聊。
Bubeck演講:https://www.php.cn/link/a8a5d22acb383aae55937a6936e120b0
#張弋訪談:https://www.php.cn/link/ 764f9642ebf04622c53ebc366a68c0a7
每天一個GPT-4獨角獸https://www.php.cn/link/7610db9e380ba9775b3c215346184a87https://www.php.cn/link/cd3e48b4bce1f295bd8ed1eb90eb0d85
[2]
https://www.php.cn/link/fc27d20994a7777cfd5e6de734fe2543https://www.php.cn/link/4dcfbc057e2ae8589f9bbd98b591c50a
[4]https://www.php.cn/link/0007cda84fafdcf42f96c4f4php.cn/link/0007cda84fafdcf42f96c4f4adb7f8ce
#4ad4adb7 ##https://www.php.cn/link/cd163419a5f4df0ba7e252841f95fcc1[6]
https://www.php.cn/link/afb0b97df87090596ae7c503f60bb23f#https://www.php.cn/link/ef8f94395be9fd78b7d0aeecf7864a03
[8]https://www.php.cn/link/300827548366111b2c31a0fd3cb4b00 ##https://www.php.cn/link/14553eed6ae802daf3f8e8c10b1961f0
以上是GPT-4變笨引爆輿論!文字程式碼品質都下降,OpenAI剛剛回應了降本減料質疑的詳細內容。更多資訊請關注PHP中文網其他相關文章!