




ChatGPT回答問題時,是一個字一個字彈出的,給人一種在認真思考的感覺。
這段對話的基本內容是:
#問:大語言生成式模型是如何運作的
答案:大型語言生成模型(如GPT-3)是基於深度學習技術的神經網路模型。這些模型通常使用一種稱為"Transformer"的架構,該架構在自然語言處理領域中取得了巨大的成功。以下是大型語言生成模型的工作原理概述:
...省略一段...
產生文字:一旦模型經過訓練,就可以使用它來產生文字。給定一個初始文字或提示,模型會根據已經學到的機率分佈生成下一個單詞,然後使用生成的單字作為輸入,並繼續生成下一個單詞,以此類推,直到達到所需的文字長度或生成終止符號。
... 省略一段...
大語言模型,Large Language Model,簡稱LLM。
從模型的角度來看,LLM每進行一次推理產生一個token,直到達到文字長度限製或產生終止符。
從服務端的角度來看,產生的token需要透過HTTPS協定逐一回到瀏覽器端。
Client-Server 模式下,常規的互動方式是client端傳送一次請求,接收一次回應。顯然,這無法滿足ChatGPT回覆問題的場景。
其次,我們可能會想到websocket,它依賴HTTP實作握手,升級成WebSocket。不過WebSocket需要client和server都持續佔用一個socket,server側成本比較高。
ChatGPT使用的是一種折衷方案: server-sent event(簡稱SSE). 我們從OpenAI的API 文件可以發現這一點:
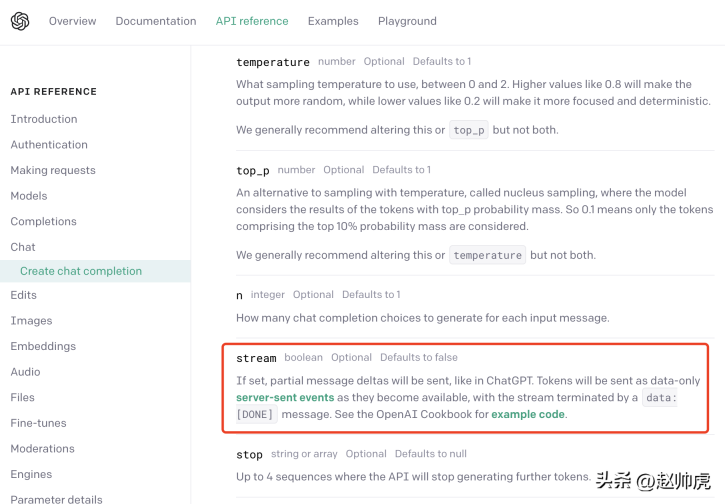
#SSE 模式下,client只需要向server傳送一次請求,server就能持續輸出,直到需要結束。整個交互過程如下圖所示:

SSE仍然使用HTTP作為應用層傳輸協議,充分利用HTTP的長連接能力,實現服務端推送能力。
從程式碼層面來看,SSE模式與單次HTTP請求不同的點有:
- client端需要開啟keep -alive,保證連線不會逾時。
- HTTP回應的Header包含 Content-Type=text/event-stream,Cache-Cnotallow=no-cache 等。
- HTTP回應的body一般是 "data: ..." 這樣的結構。
- HTTP回應裡可能有一些空數據,以避免連線逾時。
以ChatGPT API 為例,在傳送請求時,將stream參數設為true就啟用了SSE特性,但在讀取資料的SDK裡需要稍加註意。
在常規模式下,拿到 http.Response 後,請用ioutil.ReadAll 將資料讀出來即可,程式碼如下:
func main() {payload := strings.NewReader(`{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "大语言生成式模型是如何工作的"}],"max_tokens": 1024,"temperature": 1,"top_p": 1,"n": 1,"stream": false}`)client := &http.Client{}req, _ := http.NewRequest("POST", "https://api.openai.com/v1/chat/completions", payload)req.Header.Add("Content-Type", "application/json")req.Header.Add("Authorization", "Bearer <openai-token>")resp, err := client.Do(req)if err != nil {fmt.Println(err)return}defer resp.Body.Close()body, _ := ioutil.ReadAll(resp.Body)fmt.Println(string(body))}</openai-token>
執行大概耗費20s ,得到一個完整的結果:
{"id": "chatcmpl-7KklTf9mag5tyBXLEqM3PWQn4jlfD","object": "chat.completion","created": 1685180679,"model": "gpt-3.5-turbo-0301","usage": {"prompt_tokens": 21,"completion_tokens": 358,"total_tokens": 379},"choices": [{"message": {"role": "assistant","content": "大语言生成式模型通常采用神经网络来实现,具体工作流程如下:\n\n1. 数据预处理:将语料库中的文本数据进行预处理,包括分词、删除停用词(如“的”、“了”等常用词汇)、去重等操作,以减少冗余信息。\n\n2. 模型训练:采用递归神经网络(RNN)、长短期记忆网络(LSTM)或变种的Transformers等模型进行训练,这些模型都具有一定的记忆能力,可以学习到语言的一定规律,并预测下一个可能出现的词语。\n\n3. 模型应用:当模型完成训练后,可以将其应用于实际的生成任务中。模型接收一个输入文本串,并预测下一个可能出现的词语,直到达到一定长度或遇到结束符号为止。\n\n4. 根据生成结果对模型进行调优:生成的结果需要进行评估,如计算生成文本与语料库文本的相似度、流畅度等指标,以此来调优模型,提高其生成质量。\n\n总体而言,大语言生成式模型通过对语言的规律学习,从而生成高质量的文本。"},"finish_reason": "stop","index": 0}]}
#如果我們將stream 設為true,不做任何修改,請求總消耗28s ,體現對於很多條stream 訊息:
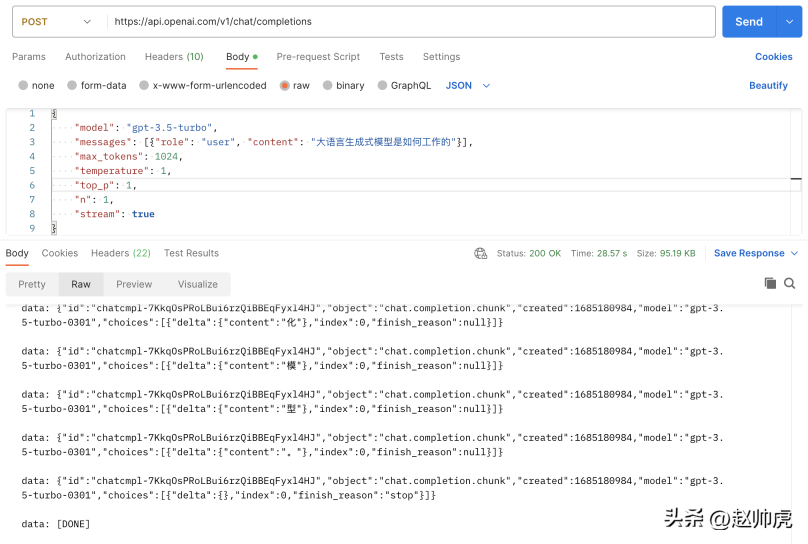
上面這張圖是一張Postman呼叫chatgpt api的圖,走的就是ioutil.ReadAll 的模式。為了實現stream讀取,我們可以分段讀取 http.Response.Body。以下是這種方式可行的原因:
- http.Response.Body 的類型是 io.ReaderCloser# ,底層依賴一個HTTP連接,支援stream讀。
- SSE 傳回的資料透過換行符號\n進行分割
所以修正的方法是透過 bufio.NewReader(resp.Body)包裝起來,並在一個for-loop裡讀取, 程式碼如下:
// stream event 结构体定义type ChatCompletionRspChoiceItem struct {Deltamap[string]string `json:"delta,omitempty"` // 只有 content 字段Indexint `json:"index,omitempty"`Logprobs *int`json:"logprobs,omitempty"`FinishReason string`json:"finish_reason,omitempty"`}type ChatCompletionRsp struct {IDstring`json:"id"`Objectstring`json:"object"`Created int `json:"created"` // unix secondModel string`json:"model"`Choices []ChatCompletionRspChoiceItem `json:"choices"`}func main() {payload := strings.NewReader(`{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "大语言生成式模型是如何工作的"}],"max_tokens": 1024,"temperature": 1,"top_p": 1,"n": 1,"stream": true}`)client := &http.Client{}req, _ := http.NewRequest("POST", "https://api.openai.com/v1/chat/completions", payload)req.Header.Add("Content-Type", "application/json")req.Header.Add("Authorization", "Bearer "+apiKey)req.Header.Set("Accept", "text/event-stream")req.Header.Set("Cache-Control", "no-cache")req.Header.Set("Connection", "keep-alive")resp, err := client.Do(req)if err != nil {fmt.Println(err)return}defer resp.Body.Close()reader := bufio.NewReader(resp.Body)for {line, err := reader.ReadBytes('\n')if err != nil {if err == io.EOF {// 忽略 EOF 错误break} else {if netErr, ok := err.(net.Error); ok && netErr.Timeout() {fmt.Printf("[PostStream] fails to read response body, timeout\n")} else {fmt.Printf("[PostStream] fails to read response body, err=%s\n", err)}}break}line = bytes.TrimSuffix(line, []byte{'\n'})line = bytes.TrimPrefix(line, []byte("data: "))if bytes.Equal(line, []byte("[DONE]")) {break} else if len(line) > 0 {var chatCompletionRsp ChatCompletionRspif err := json.Unmarshal(line, &chatCompletionRsp); err == nil {fmt.Printf(chatCompletionRsp.Choices[0].Delta["content"])} else {fmt.Printf("\ninvalid line=%s\n", line)}}}fmt.Println("the end")}
看完client端,我們再看server端。現在我們嘗試mock chatgpt server逐字回傳一段文字。這裡牽涉到兩個點:
- Response Header 需要設定 Connection 為 keep-alive 和 Content-Type 為 text/event-stream。
- 寫入 respnose 以後,需要flush到client端。
程式碼如下:
func streamHandler(w http.ResponseWriter, req *http.Request) {w.Header().Set("Connection", "keep-alive")w.Header().Set("Content-Type", "text/event-stream")w.Header().Set("Cache-Control", "no-cache")var chatCompletionRsp ChatCompletionRsprunes := []rune(`大语言生成式模型通常使用深度学习技术,例如循环神经网络(RNN)或变压器(Transformer)来建模语言的概率分布。这些模型接收前面的词汇序列,并利用其内部神经网络结构预测下一个词汇的概率分布。然后,模型将概率最高的词汇作为生成的下一个词汇,并递归地生成一个词汇序列,直到到达最大长度或遇到一个终止符号。在训练过程中,模型通过最大化生成的文本样本的概率分布来学习有效的参数。为了避免模型产生过于平凡的、重复的、无意义的语言,我们通常会引入一些技巧,如dropout、序列扰动等。大语言生成模型的重要应用包括文本生成、问答系统、机器翻译、对话建模、摘要生成、文本分类等。`)for _, r := range runes {chatCompletionRsp.Choices = []ChatCompletionRspChoiceItem{{Delta: map[string]string{"content": string(r)}},}bs, _ := json.Marshal(chatCompletionRsp)line := fmt.Sprintf("data: %s\n", bs)fmt.Fprintf(w, line)if f, ok := w.(http.Flusher); ok {f.Flush()}time.Sleep(time.Millisecond * 100)}fmt.Fprintf(w, "data: [DONE]\n")}func main() {http.HandleFunc("/stream", streamHandler)http.ListenAndServe(":8088", nil)}
#在真實場景中,要傳回的資料來自另一個服務或函數調用,如果這個服務或函數呼叫回傳時間不穩定,可能導致client端長時間收不到訊息,所以一般的處理方式是:
- #對第三方的呼叫放到一個goroutine 中。
- 透過 time.Tick 建立一個計時器,向client端發送空白訊息。
- 建立一個timeout channel,避免回應時間太久。
為了能夠從不同的channel讀取數據,select 是一個不錯的關鍵字,例如這段示範程式碼:
// 声明一个 event channel// 声明一个 time.Tick channel// 声明一个 timeout channelselect {case ev := <h2 id="小結一下">小結一下</h2><p style="text-align: justify;"><span style="color: #333333;">大語言模型產生響應整個結果的過程是比較漫長的,但逐token產生的響應比較快,ChatGPT將這一特性與SSE技術充分結合,一個字一個字地彈出回复,在用戶體驗上實現了質的提升。 </span></p><p style="text-align: justify;"><span style="color: #333333;">綜觀生成式模型,不管是LLAMA/小羊駝 (不能商用),還是Stable Diffusion/Midjourney。在提供線上服務時,均可利用SSE技術節省提升使用者體驗,節省伺服器資源。 </span></p>以上是ChatGPT是如何做到一個字一個字輸出的?的詳細內容。更多資訊請關注PHP中文網其他相關文章!


 軟AI的興起及其對當今企業的意義Apr 15, 2025 am 11:36 AM
軟AI的興起及其對當今企業的意義Apr 15, 2025 am 11:36 AM軟AI(被定義為AI系統,旨在使用近似推理,模式識別和靈活的決策執行特定的狹窄任務 - 試圖通過擁抱歧義來模仿類似人類的思維。 但是這對業務意味著什麼
 為AI前沿的不斷發展的安全框架Apr 15, 2025 am 11:34 AM
為AI前沿的不斷發展的安全框架Apr 15, 2025 am 11:34 AM答案很明確 - 只是雲計算需要向雲本地安全工具轉變,AI需要專門為AI獨特需求而設計的新型安全解決方案。 雲計算和安全課程的興起 在
 生成AI的3種方法放大了企業家:當心平均值!Apr 15, 2025 am 11:33 AM
生成AI的3種方法放大了企業家:當心平均值!Apr 15, 2025 am 11:33 AM企業家,並使用AI和Generative AI來改善其業務。同時,重要的是要記住生成的AI,就像所有技術一樣,都是一個放大器 - 使得偉大和平庸,更糟。嚴格的2024研究O
 Andrew Ng的新簡短課程Apr 15, 2025 am 11:32 AM
Andrew Ng的新簡短課程Apr 15, 2025 am 11:32 AM解鎖嵌入模型的力量:深入研究安德魯·NG的新課程 想像一個未來,機器可以完全準確地理解和回答您的問題。 這不是科幻小說;多虧了AI的進步,它已成為R
 大語言模型(LLM)中的幻覺是不可避免的嗎?Apr 15, 2025 am 11:31 AM
大語言模型(LLM)中的幻覺是不可避免的嗎?Apr 15, 2025 am 11:31 AM大型語言模型(LLM)和不可避免的幻覺問題 您可能使用了諸如Chatgpt,Claude和Gemini之類的AI模型。 這些都是大型語言模型(LLM)的示例,在大規模文本數據集上訓練的功能強大的AI系統
 60%的問題 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM
60%的問題 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM最近的研究表明,根據行業和搜索類型,AI概述可能導致有機交通下降15-64%。這種根本性的變化導致營銷人員重新考慮其在數字可見性方面的整個策略。 新的
 麻省理工學院媒體實驗室將人類蓬勃發展成為AI R&D的核心Apr 15, 2025 am 11:26 AM
麻省理工學院媒體實驗室將人類蓬勃發展成為AI R&D的核心Apr 15, 2025 am 11:26 AM埃隆大學(Elon University)想像的數字未來中心的最新報告對近300名全球技術專家進行了調查。由此產生的報告“ 2035年成為人類”,得出的結論是,大多數人擔心AI系統加深的採用


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3漢化版
中文版,非常好用

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

