
大模型知識Out該怎麼辦?浙大團隊探索大模型參數更新的方法—模型編輯

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-30 22:11:091489瀏覽
夕小瑤科技說原創 作者| 小戲、Python
大模型在其巨大體量背後蘊藏著一個直觀的問題:「大模型應該怎麼更新?」
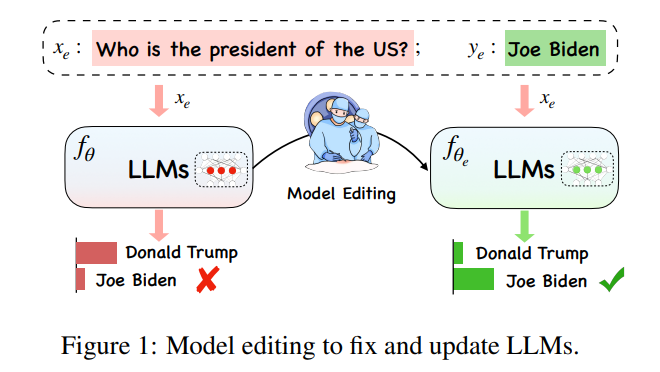
#在大模型極其巨大的計算開銷下,大模型知識的更新並不是一件簡單的“學習任務”,理想情況下,隨著世界各種形勢的紛繁複雜的變換,大模型也應該隨時隨地跟上時代的腳步,但是訓練全新大模型的計算負擔卻不允許大模型實現即時的更新,因此,一個全新的概念“Model Editing(模型編輯)”應運而生,以實現在特定領域內對模型數據進行有效的變更,同時不會對其他輸入的結果造成不利影響。

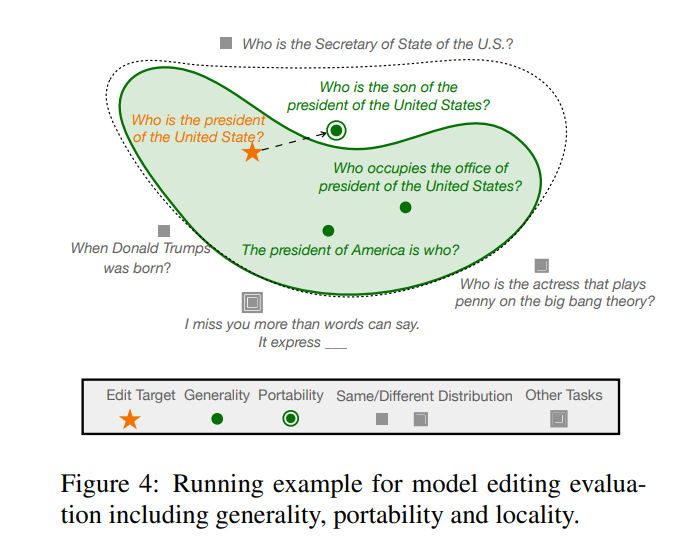
其中, 表示 的“有效鄰居”, 則表示超出 作用範圍的領域。一個編輯後的模型應滿足以下三點,分別是可靠性,普適性與局部性,可靠性即編輯後模型應該可以正確的輸出編輯前模型錯誤的例子,可以透過編輯案例的平均準確率來衡量,普適性表示對於 的“有效鄰居”,模型都應該可以給出正確的輸出,這點可以對編輯案例領域數據集進行均勻抽樣衡量平均正確率來衡量,最後局部性,即表示編輯後模型在超出編輯範圍的例子中仍然應該保持編輯前的正確率,可以通過分別測算編輯前編輯後的平均準確率來對局部性進行刻畫,如下圖所示,在編輯“特朗普”的位置時,一些其他的公共特徵不應受到更改。同時,其他實體,例如“國務卿”,儘管與“總統”具有相似的特徵,但也不應受到影響。
而今天介紹的這篇來自浙江大學的論文便站在一個大模型的視角,為我們詳細敘述了大模型時代下模型編輯的問題、方法以及未來,並且建構了一個全新的基準資料集與評估指標,幫助更全面確定的評估現有的技術,並為社群在方法選擇上提供有意義的決策建議與見解:
論文主題:Editing Large Language Models: Problems, Methods, and Opportunities
論文連結:https://arxiv.org/pdf/2305.13172.pdf
主流方法
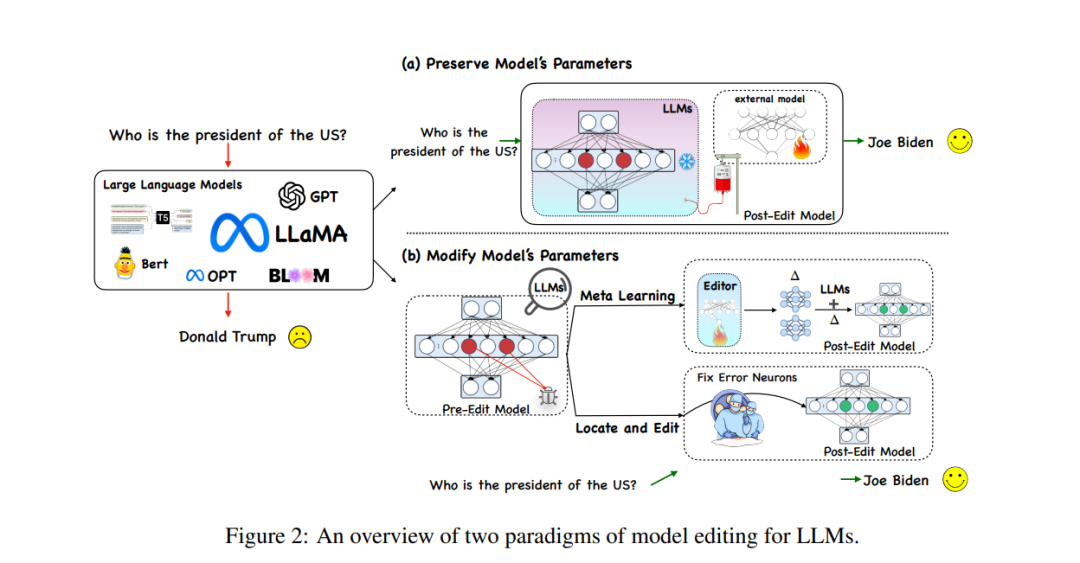
當下針對大規模語言模型(LLMs)的模型編輯方法如下圖所示主要可以分為兩類範式,分別是如下圖(a)所示的保持原模型參數不變下使用額外的參數以及如下圖(b )所示的修改模型的內部參數。
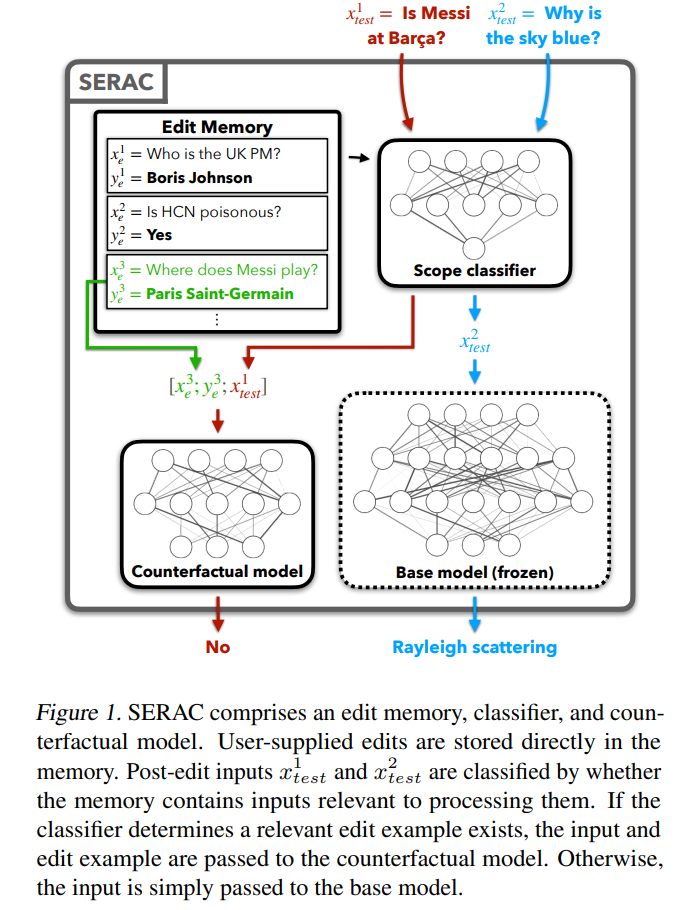
首先來看相對簡單的增加額外參數的方法,這種方法又稱基於記憶或記憶體的模型編輯方法,代表方法SERAC 最早出現於Mitchell 提出“模型編輯」的論文,其核心思想在於保持模型原始參數不變,透過一個獨立的參數集重新處理修改後的事實,具體而言,這類方法一般先增加一個「範圍分類器」判斷新輸入是否處於被「重新編輯」過的事實範圍內,如果屬於,則使用獨立參數集對該輸入進行處理,對快取中的「正確答案」賦予更高的選擇機率。在SERAC 的基礎上,T-Patcher 與CaliNET 向PLMs 的前饋模組中引入額外可訓練的參數(而不是額外外掛一個模型),這些參數在修改後的事實資料集中進行訓練以達到模型編輯的效果。
而另一個大類方法即修改原模型中參數的方法主要應用一個∆ 矩陣去更新模型中的部分參數 ,具體而言,修改參數的方法又可以分為「Locate-Then-Edit」與元學習兩類方法,從名字也可以看出,Locate-Then-Edit 方法先透過定位模型中的主要影響參數,再對定位到的模型參數進行修改實現模型編輯,其中主要方法如Knowledge Neuron 方法( KN)透過識別模型中的「知識神經元」來確定主要影響參數,透過更新這些神經元實現對模型的更新,另一種名為ROME 的方法思想與KN 類似,透過因果中介分析定位編輯區域,此外還有一種MEMIT 的方法可以實現一系列編輯描述的更新。這類方法最大的問題在於普遍依據一個事實知識局部性的假設,但是這一假設並沒有得到廣泛的驗證,對許多參數的編輯有可能導致意想不到的結果。
而元學習方法與Locate-Then-Edit 方法不同,元學習方法使用hyper network 方法,使用一個超網路(hyper network)為另一個網路產生權重,具體而言在Knowledge Editor 方法中,作者使用一個雙向的LSTM 去預測每個資料點為模型權重帶來的更新,從而實現對編輯目標知識的帶約束的最佳化。這類知識編輯的方法由於LLMs 的巨大參數量導致難以應用於LLMs 中,因此Mitchell 等又提出了MEND(Model Editor Networks with Gradient Decomposition)使得單一的編輯描述可以對LLMs 進行有效的更新,這種更新方法主要使用梯度的低秩分解來微調大模型的梯度,從而使得可以對LLMs 進行最小資源的更新。與 Locate-Then-Edit 方法不同,元學習方法通常花費的時間更長,消耗的記憶體成本更大。
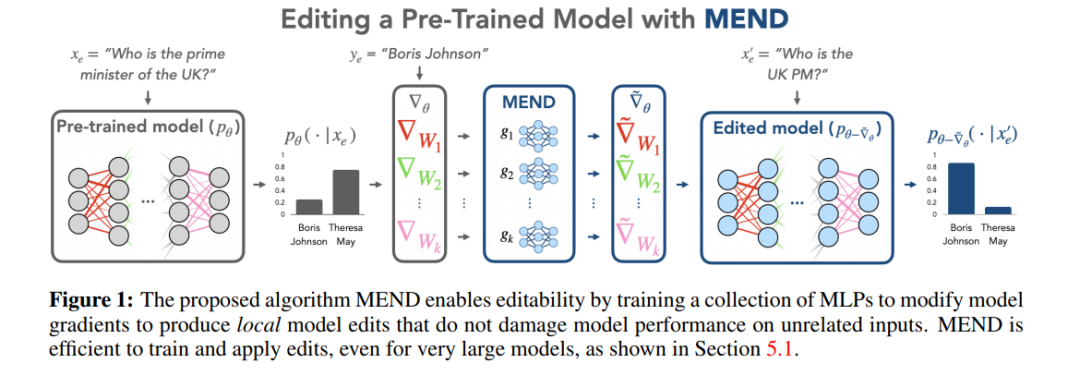
方法評估
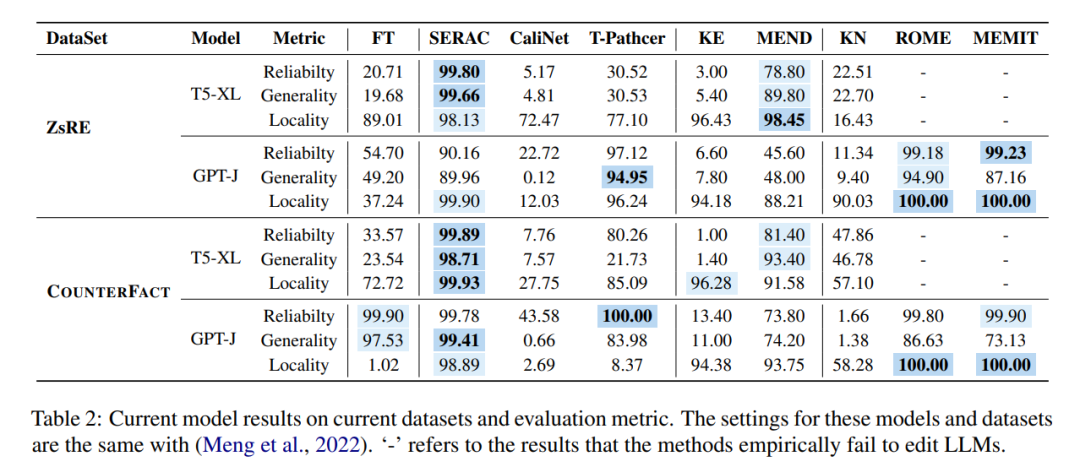
這些不同方法在模型編輯的兩個主流資料集ZsRE(問答資料集,使用反向翻譯產生的問題改寫為有效領域) 與COUNTERFACT(反事實資料集,將主詞實體替換為同義實體作為有效領域) 中進行實驗如下圖所示,實驗主要針對兩個相對以往研究較大的LLMs T5-XL(3B)和GPT-J(6B)作為基礎模型,高效的模型編輯器應該在模型效能、推理速度和儲存空間之間取得平衡。
對比第一列微調(FT)的結果,可以發現,SERAC 和ROME 在ZsRE 和COUNTERFACT 資料集上表現出色,特別是SERAC,它在多個評估指標上獲得了超過90% 的結果,雖然MEMIT 的通用性不如SERAC 和ROME,但在可靠性和局部性上表現出色。而T-Patcher 方法表現極不穩定,在COUNTERFACT 資料集中具有不錯的可靠性和局部性,但缺乏通用性,在GPT-J 中,可靠性和通用性表現出色,但在局部性方面表現不佳。值得注意的是,KE、CaliNET 和 KN 的表現表現較差,相對於這些模型在「小模型」中取得的良好表現而言,實驗可能證明了這些方法不是非常適配大模型的環境。
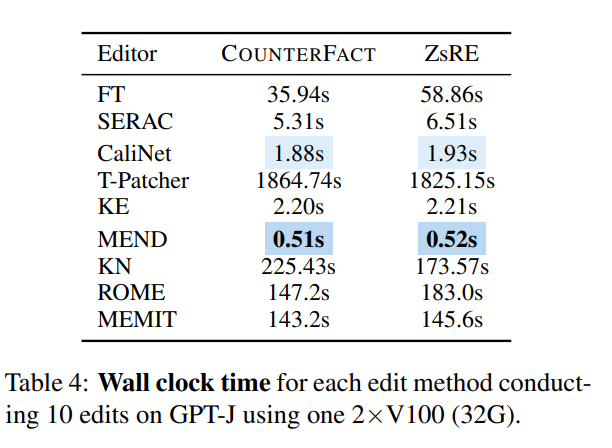
而如果從時間來看,一旦訓練好網絡,KE 和MEND 則表現相當優秀,而如T-Patcher 這類方法耗時則過於嚴重:
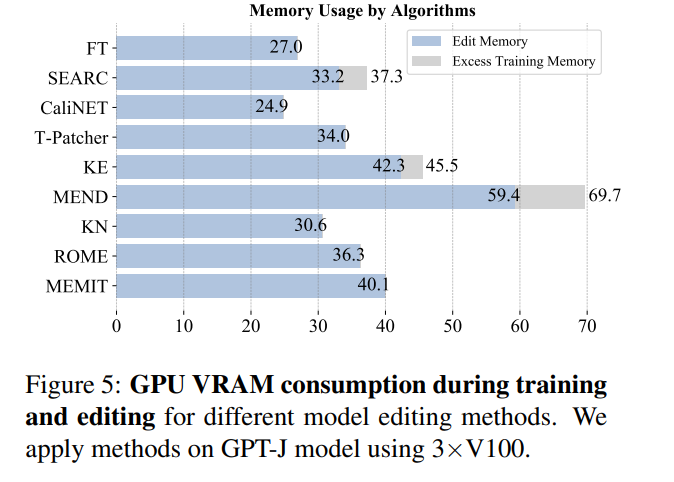
再從記憶體消耗來看,大多數方法消耗內存在同一個量級,但引入額外參數的方法會承擔額外的記憶體開銷:
#同時,通常對模型編輯的操作還需要考慮批次輸入編輯信息以及順序輸入編輯信息,即一次更新多個事實信息與順序更新多個事實信息,批量輸入編輯資訊整體模型效果如下圖所示,可以看到MEMIT 可以同時支援編輯超過10000條信息,並且還能保證兩個度量指標的性能都保持穩定,而MEND 和SERAC 則表現不佳:
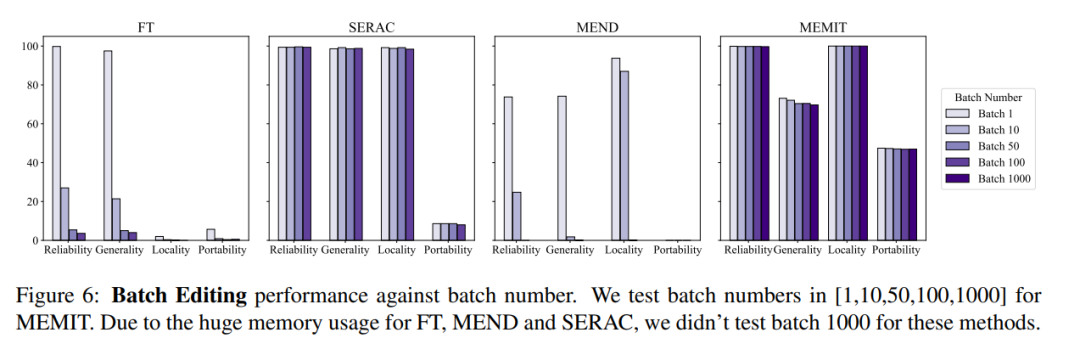
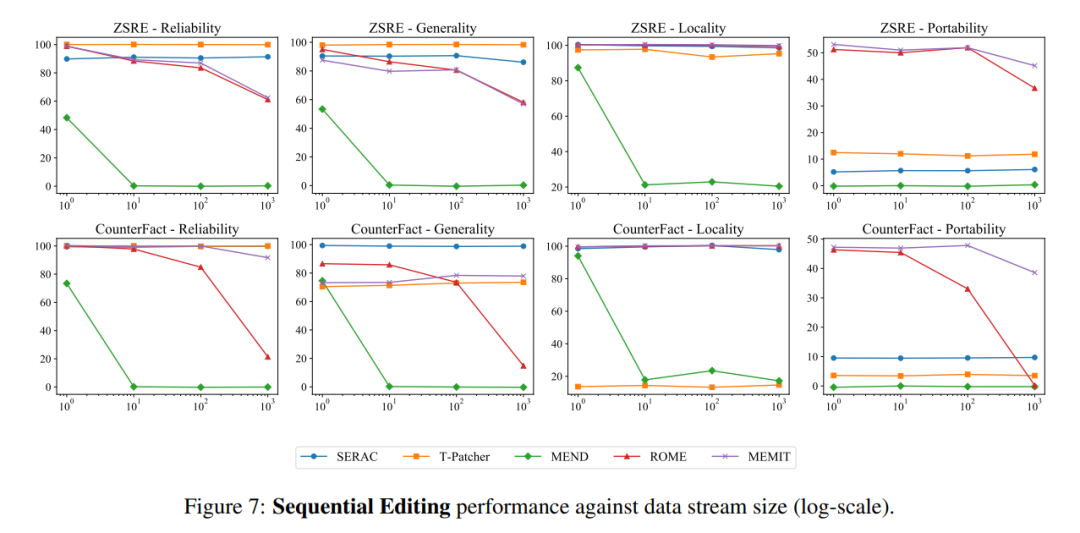
而在順序輸入方面,SERAC 和T-Patcher 表現出色而穩定,ROME,MEMIT,MEND 都出現了在一定數量的輸入後模型性能快速下降的現象:
最後,作者在研究中發現,當下這些資料集的建構及評估指標很大程度上只關注句子措詞上的變化,但是並沒有深入到模型編輯對許多相關邏輯事實的更改,譬如如果將“Watts Humphrey 就讀哪所大學”的答案從三一學院改為密西根大學,顯然如果當我們問模型“Watts Humphrey 大學時期居住於哪個城市?”時,理想模型應該回答安娜堡而不是哈特福德,因此,論文作者在前三個評估指標的基礎上引入了「可移植性」指標,衡量編輯後的模型在知識轉移方面的有效性。
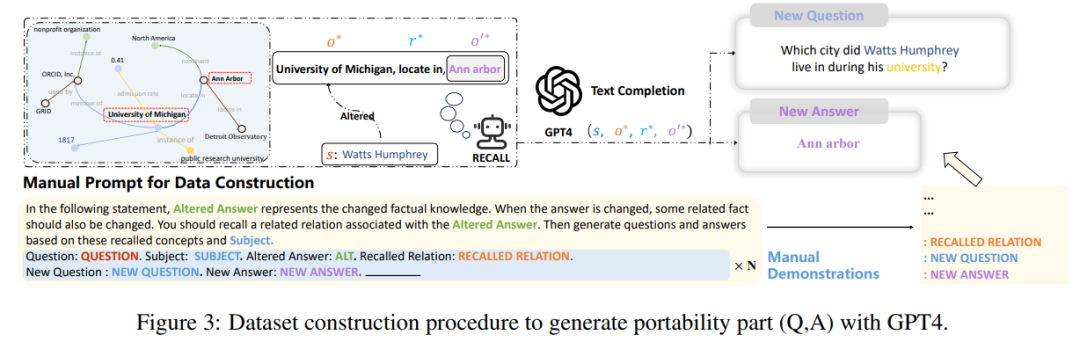
為此,作者使用GPT-4 建立了一個新的資料集,透過將原始問題 的答案從 改為 ,並建構另一個正確答案為 的問題,組成 三元組,對編輯後模型輸入 ,如果模型可以正確輸出 則證明該編輯後模型具有“可移植性”,而根據這個方法,論文測試了現有幾大方法的可移植性得分如下圖所示:
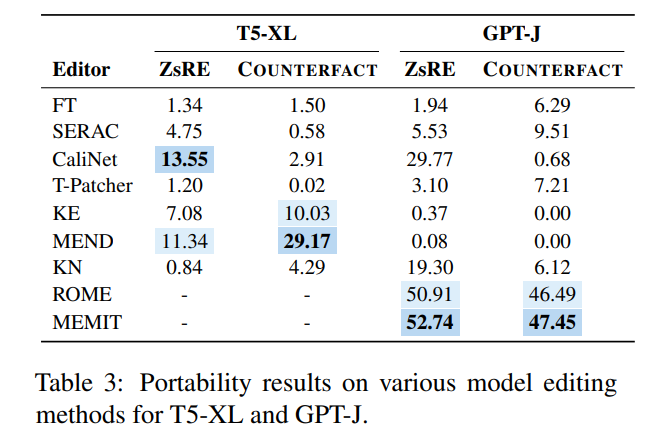
可以看到,幾乎絕大多數模型編輯方法在可移植性方面都不太理想,曾經表現優異的SERAC 可移植性準確率不到10%,相對最好的ROME 和MEMIT 最高也只有50% 左右,這表明當下的模型編輯方法幾乎難以做到編輯後知識的任何擴展和推廣,模型編輯尚有很長的路要走。
討論與未來
不管從何種意義來說,模型編輯預設的問題在未來所謂的「大模型時代」都十分有潛力,模型編輯的問題需要更好的探索如「模型知識究竟儲存在哪些參數」、「模型編輯操作如何不影響其他模組的輸出」等一系列非常困難的問題。而另一方面,解決模型“過時”的問題,除了讓模型進行“編輯”,還有一條思路在於讓模型“終身學習”並且做到“遺忘”敏感知識,不論是模型編輯還是模型終身學習,這類研究都將對LLMs 的安全與隱私問題做出有意義的貢獻。
以上是大模型知識Out該怎麼辦?浙大團隊探索大模型參數更新的方法—模型編輯的詳細內容。更多資訊請關注PHP中文網其他相關文章!