
Redis百億級Key儲存方案怎麼實現

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-30 17:44:441227瀏覽
1.需求背景
此應用程式場景為DMP快取儲存需求,DMP需要管理非常多的第三方id數據,其中包含各媒體cookie與自身cookie(以下統稱supperid)的mapping關係,還包括了supperid的人口標籤、行動端id(主要是idfa和imei)的人口標籤,以及一些黑名單id、ip等資料。
使用hdfs來進行離線儲存千億記錄並不困難,但是對於DMP而言,需要提供毫秒級的即時查詢。由於cookie這種id本身俱有不穩定性,因此許多的真實用戶的瀏覽行為會導致大量的新cookie生成,只有及時同步mapping的數據才能命中DMP的人口標籤,無法透過預熱來獲取較高的命中,這就跟快取儲存帶來了極大的挑戰。
經過實際測試,對於上述數據,常規存儲超過五十億的kv記錄就需要1T多的內存,如果需要做高可用多副本那帶來的消耗是巨大的,另外kv的長短不齊也會帶來許多記憶體碎片,這就需要超大規模的儲存方案來解決上述問題。
2.儲存何種資料
人⼝標籤主要是cookie、imei、idfa以及其對應的gender(性別)、age (年齡層)、geo(地理)等;mapping關係主要是媒體cookie對supperid的映射。以下是資料儲存⽰範例:
1) PC端的ID:
媒體編號-媒體cookie=>supperid
supperid => { age=>年齡段編碼,gender=>性別編碼,geo=>地理位置編碼}
2) Device端的ID:
imei or idfa => { age=>年齡段編碼,gender=>性別編碼,geo=>地理位置編碼}
顯然PC資料需要儲存兩種key=>value還有key=>hashmap,⽽而Device資料需要儲存⼀一種
key=>hashmap即可。
3.資料特點
#短key短value:其中superid為21位數字:例如1605242015141689522;imei為小寫md5:例如2d131005dc0f37d362a5d97094103633;idfa為大寫帶」-」md5:例如:51DFFC83-9541-4411-FA4F-356927E39D##ookie;#12#112#。
- #需要為全量資料提供服務,supperid是百億級、媒體映射是千億級、移動id是幾十億級;
- 每天有十億等級的mapping關係產生;
- 對於較大時間視窗內可以預判熱資料(有一些存留的穩定cookie);
- 對於目前mapping資料無法預判熱數據,有許多是新產生的cookie;
- 4.存在的技術挑戰
1)長短不一容易造成記憶體碎片;2)由於指標大量存在,記憶體膨脹率比較高,一般在7倍,純記憶體儲存通病;
3)雖然可以透過cookie的行為預判其熱度,但每天新生成的id依然很多(百分比比較敏感,暫不透露);4)由於服務要求在公網環境(國內公網延遲60ms以下)下100ms以內,所以原則上當天新更新的mapping和人口標籤需要全部in memory,而不會讓請求落到後端的冷資料;5)業務方面,所有資料原則上至少保留35天甚至更久;6)記憶體至今也比較昂貴,百億級Key乃至千億級儲存方案勢在必行! 5.解決方案#5.1 淘汰策略
每天有大量新資料進入資料庫,因此及時清理資料變得特別重要,這是儲存緊缺的一個主要原因。主要方法就是發現並保留熱數據淘汰冷數據。 網路使用者數量遠遠達不到數十億的規模,其ID也會隨著時間不斷變化並有一定壽命。所以很大程度上我們儲存的id其實是無效的。而查詢其實前端的邏輯就是廣告曝光,跟人的行為有關,所以一個id在某個時間窗口的(可能是一個campaign,半個月、幾個月)訪問行為上會有一定的重複性。
資料初始化之前,我們先利用hbase將日誌的id聚合去重,劃定TTL的範圍,一般是35天,這樣可以砍掉近35天未出現的id。另外在Redis中設定過期時間是35天,當有訪問並命中時,對key進行續命,延長過期時間,未在35天出現的自然淘汰。這樣可以針對穩定cookie或id有效,實際證明,續命的方法對idfa和imei比較實用,長期累積可達到非常理想的命中。 5.2 減少膨脹Hash表空間大小和Key的數量決定了衝突率(或用負載因子來衡量),再合理的範圍內,key越多自然hash表空間越大,消耗的記憶體自然也會很大。再加上大量指針本身是長整型,所以記憶體儲存的膨脹十分可觀。先來談談如何把key的個數減少。 大家先來了解一種儲存結構。依照下列步驟儲存可以將key1=>value1儲存在redis中,這是我們所期望的。先用固定長度的隨機雜湊md5(key)值當作redis的key,我們稱為BucketId,而將key1=>value1儲存在hashmap結構中,這樣在查詢的時候就可以讓client依照上面的流程計算出散列,從而查詢到value1。 過程變更簡單描述為:get(key1) -> hget(md5(key1), key1) 從而得到value1。 如果我們透過預先計算,讓很多key可以在BucketId空間裡碰撞,那麼可以認為一個BucketId下面掛了多個key。例如平均每個BucketId下面掛10個key,那麼理論上我們將會減少超過90%的redis key的數量。 具體實現起來有一些麻煩,而且用這個方法之前你要想好容量規模。我們通常使用的md5是32位元的hexString(16進位字元),它的空間是128bit,這個量級太大了,我們需要儲存的是百億級,大約是33bit,所以我們需要有一個機制計算出合適位數的雜湊,而且為了節省內存,我們需要利用全部字元類型(ASCII碼在0~127之間)來填充,而不用HexString,這樣Key的長度可以縮短到一半。 下面是具體的實作方式 public static byte [] getBucketId(byte [] key, Integer bit) {
MessageDigest mdInst = MessageDigest.getInstance("MD5");
mdInst.update(key);
byte [] md = mdInst.digest();
byte [] r = new byte[(bit-1)/7 + 1];// 因为一个字节中只有7位能够表示成单字符
int a = (int) Math.pow(2, bit%7)-2;
md[r.length-1] = (byte) (md[r.length-1] & a);
System.arraycopy(md, 0, r, 0, r.length);
for(int i=0;i<r.length if r return></r.length>
BucketId空間的最終大小由參數bit決定,空間大小的選用集合是離散的2的整數冪次方。這裡解釋一下為何一個位元組只有7位元可用,是因為redis儲存key時需要是ASCII(0~127),而不是byte array。如果規劃百億級存儲,規劃每個桶分擔10個kv,那麼我們只需2^30=1073741824的桶個數即可,也就是最終key的個數。
5.3 減少碎片
碎片主要原因在於記憶體無法對齊、過期刪除後,記憶體無法重新分配。透過上文描述的方式,我們可以將人口標籤和mapping資料按照上面的方式去存儲,這樣的好處就是redis key是等長的。另外對於hashmap中的key我們也做了相關優化,截取cookie或者deviceid的後六位作為key,這樣也可以保證內存對齊,理論上會有衝突的可能性,但在同一個桶內後綴相同的概率極低(試想id幾乎是隨機的字串,隨意10個由較長字符組成的id後綴相同的概率*桶樣本數=發生衝突的期望值
另外提一下,減少碎片還有個很low但是有效的方法,將slave重啟,然後強制的failover切換主從,這樣相當於給master整理的內存的碎片。
推薦Google-tcmalloc, facebook-jemalloc記憶體分配,可以在value不大時減少記憶體碎片和記憶體消耗。有人測過大value情況下反而libc更節約。
6. md5雜湊桶的方法需要注意的問題
1)kv儲存的量級必須事先規劃好,浮動的範圍大概在桶數的十到十五倍,例如我就想存放百億左右的kv,那麼最好選擇30bit~31bit作為桶的個數。也就是說業務成長在一個合理的範圍(10~15倍的成長)是沒問題的,如果業務太多倍數的成長,會導致hashset成長過快導致查詢時間增加,甚至觸發zip-list閾值,導致內存急劇上升。
2)適合短小value,如果value太大或字段太多並不適合,因為這種方式必須要求把value一次性取出,例如人口標籤是非常小的編碼,甚至只需要3、 4個bit(位)就能裝下。 3)典型的時間換空間的做法,由於我們的業務場景並不是要求在極高的qps之下,一般每天億到十億級別的量,所以合理利用CPU租值,也是十分經濟的。
使用資訊摘要後,由於key的大小會減少並被限制長度,因此無法從Redis中隨機產生key。如果需要匯出,必須在冷資料中匯出。
5)expire需要自己實現,目前的演算法很簡單,由於只有在寫入操作時才會增加消耗,所以在寫操作時按照一定的比例抽樣,用HLEN命中判斷是否超過15個entry ,超過才將過期的key刪除,TTL的時間戳記存放在value的前32bit。
6)桶的消耗統計是需要做的。需要定期清理過期的key,確保redis的查詢不會變慢。
7.測試結果
人口標籤和mapping的資料100億筆記錄。
在優化之前,使用了約2.3T的儲存空間,碎片率大約是2;而在優化之後,使用了約500g的儲存空間,而每個儲存桶的平均使用量約為4 。碎片率在1.02左右。查詢時這對於cpu的耗損微乎其微。
另外要提一下的是,每個桶子的消耗其實並不是均勻的,而是符合多項式分佈的。
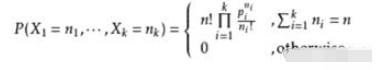
上面的公式可以計算桶消耗的機率分佈。這個公式只是為了提醒大家,不能夠想當然地認為桶的消耗是完全均衡的,有可能有一些桶會包含數百個鍵。但事實並沒有那麼誇張。試想投硬幣,結果只有兩種正反面。相當於只有兩個桶,如果你投上無限多次,每一次相當於一次伯努利實驗,那麼兩個桶子必然會十分的均勻。當你進行大量廣義伯努利實驗並面對許多桶子時,機率分佈就像一種無形的魔法,籠罩著你。桶的消耗分佈就會趨於一種穩定的值。接下來我們就了解桶消耗分佈具體什麼情況:
透過取樣統計
31bit(20億億)的桶,平均4.18消耗

#100億節約了1.8T記憶體。原文重寫: 不僅節省了原本 78% 的內存,而且桶的消耗指標也比預期的底線值 15 低得多。
對於未出現的桶子也是存在一定量的,如果過多會導致規劃不準確,其實數量是符合二項分佈的,對於2^30桶存儲2^32kv,不存在的桶大概有(百萬級,影響不大):
Math.pow((1 - 1.0 / Math.pow(2, 30)), Math.pow(2, 32)) * Math.pow( 2, 30);
對於桶消耗不均衡的問題不必太擔心,隨著時間的推移,寫入時會對HLEN超過15的桶進行削減,根據多項式分佈的原理,當實驗次數多到一定程度時,桶的分佈就會趨於均勻(硬幣投擲無數次,那麼正反面出現次數應該是一致的),只不過我們通過expire策略削減了桶消耗,實際上對於每個桶已經經歷了很多的實驗發生。
以上是Redis百億級Key儲存方案怎麼實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!