
MySQL聚合查詢與聯合查詢操作的範例分析

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-28 21:31:551819瀏覽
一. 聚合查詢
1.聚合函數(count,sum,avg...)
#常見的統計總數、計算平局值等操作,可以使用聚合函數來實現,常見的聚合函數有:
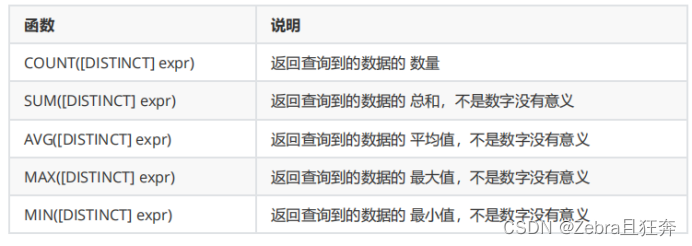

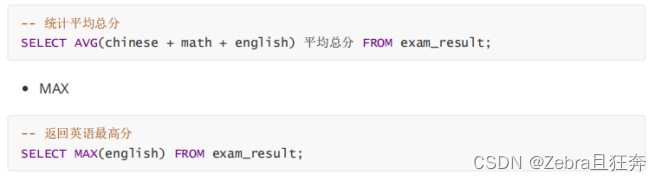

注意最後面都是可以加上where,order by這些語句的,這些聚合函數會根據這些語句的結果集來進行查詢
後面最好不要加上limit,因為MySQL的limit和別的資料庫的limit不一樣
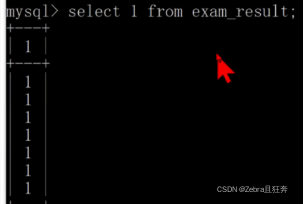
有使用統計列的聚合函數的時候,避免再寫上其他列,不然會出現這種無意義顯示第一列的情況

#注意點:
1.count:可以使用count(*),count(0),count(1)這樣,說白了實際上和select 1 from整個表是一樣的道理,這個count裡面的0,1只是作為參數傳入而已,先select 1,然後再統計count的值
#2.sum,max, min,avg都不可以傳入*,必須傳入字段或表達式使用
3.avg可以和sum結合起來用,聚合函數都可以多個一起用
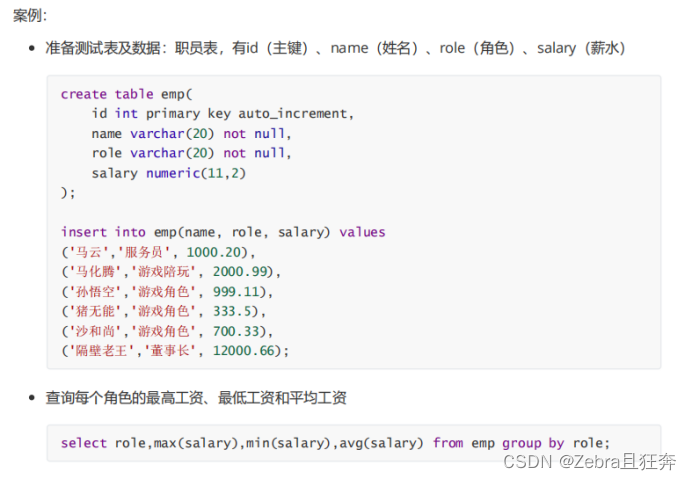
#2. GROUP BY子句
使用GROUP BY 子句可以對特定欄位進行分組查詢。需要滿足:使用 GROUP BY 進行分組查詢時,SELECT 指定的欄位必須是“分組依據欄位”,其他欄位若想出現在SELECT 中則必須包含在聚合函數中。
Select後面的聚合函數是等Group by執行完分組以後才進行的
Group by語句的實質就是分組,常配合聚合查詢使用
語法:

#Select指定的欄位必須是group by後面有的,沒有的只能出現在聚合函數中,不然會出問題
GROUP BY注意事項
1.Group by語句的實質就是分組,常配合聚合查詢使用
2.只要有聚合函數出現,就可能要分組
3.分組運算中,查詢允許的是分組字段,聚合函數,其他非分組欄位需要保證分組後沒有多行(如學生id分組,查詢字段可以有學生姓名,因為學生id分組以後,只有一行)
4.分組前過濾條件用where,分組後用having(代碼是順序執行的)
執行順序:from > on> join > where > group by > with > having >select > distinct > order by > limit
最早從from開始執行,所以別名一般都在from這裡命名,你在select命名也可以,不過select較後面執行,命名了前面執行那些地方都用不了。
Limit永遠在最後執行
#5.---select classid,average(score) from student where score>60 group by classid havinng classid
先找出score > 60的行,然後依照classid分組,得到的結果裡面,再選出class
6.group by 就是將重複的行合併成一行
7.group by 很多個欄位的時候,可能沒有合併,但是達到了分組的效果,可以使用聚合函數了。
3.HAVING
GROUP BY 子句進行分組以後,需要對分組結果再進行條件篩選時,不能使用 WHERE 語句,而需要用HAVING。 HAVING是在GROUP BY 後面執行的

二.聯合查詢((重點)多表格)
1.內部連結
語法:

#你可能無法區分第二種方法中連結條件和篩選結果集條件的差異。用哪一種都行,還是優先用第一種吧,為了和後面的外連接對應。內連接就相當於在得到的笛卡爾積上給了連接條件
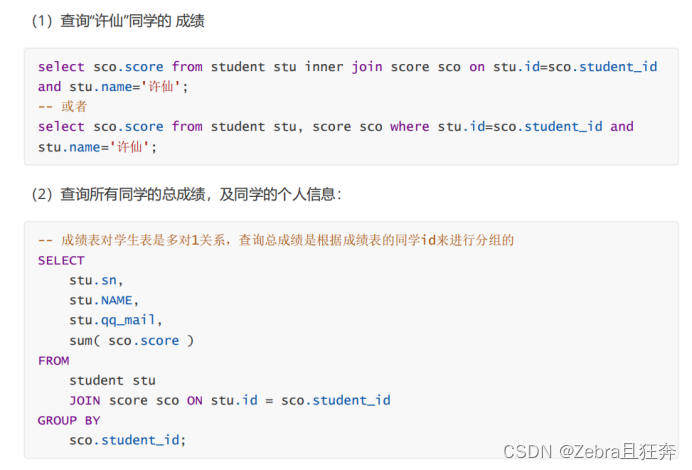
這裡要是不group by進行分組的話,就會像下面這樣只有一行,相當於是把所有學生的所有成績全部加起來了。由於我們需要的是每個學生的總成績,因此需要先根據學生ID將其分組。

2.外連接
外連接分為左外連接和右外連接。左外連接是當進行聯合查詢時,左側的表完全顯示的情況下的一種連接方式;右外連接是當進行聯合查詢時,右側的表完全顯示的情況下的一種連接方式。
注意點:
左連接:左表的資料不會依據連接條件(on後面的部分,包括and上去的) 過濾而全部顯示,其他條件還是可以過濾,例如後面再加上where等條件。
如果右邊表有資料有不符合連接條件的值,右表資料會顯示null,左表全顯示
語法: (註:On後面還能跟上where)


同樣的查詢方法,這次能顯示出第8名成績為空的學生的信息,左表也就是student表中的數據會全部顯示出來,不會受到連接條件stu.id = sco.student_id這一連接條件的影響,如果是之前的內連結,就顯示不出老外學中文這一學生的資訊,因為在sco表中根本就沒有老外學中文這一學生的id。
3.自連接
自連接是指在同一張表連接自身進行查詢。
使用場景:同一張表,多行進行比較。
附註:自連線查詢也可以使用join on語句來進行查詢。
4.子查詢
子查詢是指嵌入在其他sql語句中的select語句,也叫巢狀查詢
查詢與「不想畢業」 同學的同班同學:(自連接)

#多行子查詢:傳回多行記錄的子查詢(用的多)
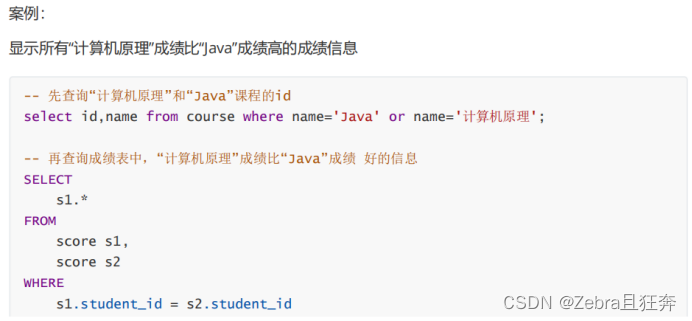
案例:查詢「語文」或「英文」課程的成績資訊:(內連結)
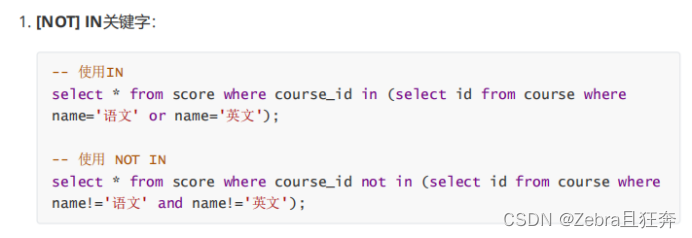
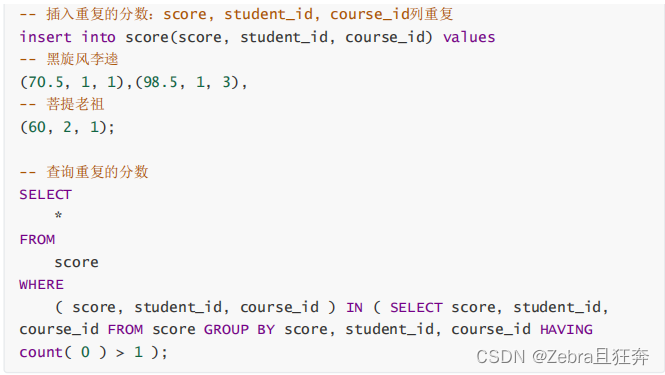
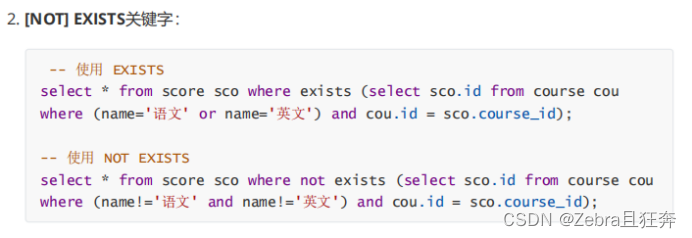
這裡的group by沒有起到合併的作用,但是起到了分組的作用
5.合併查詢
在實際應用中,為了合併多個select的執行結果,可以使用集合運算子union,union all。使用UNION和UNION ALL時,前後查詢的結果集中,欄位需要一致#。
**有些情況下,多張表之間沒法關聯,但是要查詢一樣字段的資料
#**union的效率比or高
union
此運算子用於取得兩個結果集的並集。此運算元會自動消除結果集中的重複行,當資料內容完全相同時會自動去重。
案例:查詢id小於3,或名字為「英文」的課程:
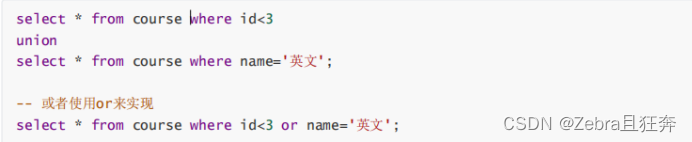
union all
此運算子用於取得兩個結果集的並集。當使用該運算元時,不會去掉結果集中的重複行。 (取到的資料完全一樣的時候,都會顯示出來,不會進行去重)
案例:查詢id小於3,或名字為「Java」的課程

以上是MySQL聚合查詢與聯合查詢操作的範例分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!