
MySQL如何為字串欄位加索引

- 王林轉載
- 2023-05-28 14:38:522631瀏覽
假設,你現在維護一個支援郵箱登入的系統,用戶表是這麼定義的:
create table SUser( ID bigint unsigned primary key, email varchar(64), ... )engine=innodb;
由於要使用郵箱登錄,所以業務碼中一定會出現類似這樣的語句:
select f1, f2 from SUser where email='xxx';
如果email 這個欄位上沒有索引,那麼這個語句就只能做全表掃描。
1)那我可以在郵件地址這個欄位上面建立索引嗎?
MySQL 是支援前綴索引的,可以定義字串的一部分作為索引
2)如果建立索引的語句不指定前綴長度,那麼會怎麼樣?
#索引就會包含整個字串
#3)能舉例來說明嗎?
alter table SUser add index index1(email); 或 alter table SUser add index index2(email(6));
index1 索引裡面,包含了每個記錄的整個字串
index2 索引裡面,對於每個記錄都是只取前6 個位元組
4)這兩個不同的定義在資料結構和儲存上有什麼差別呢?
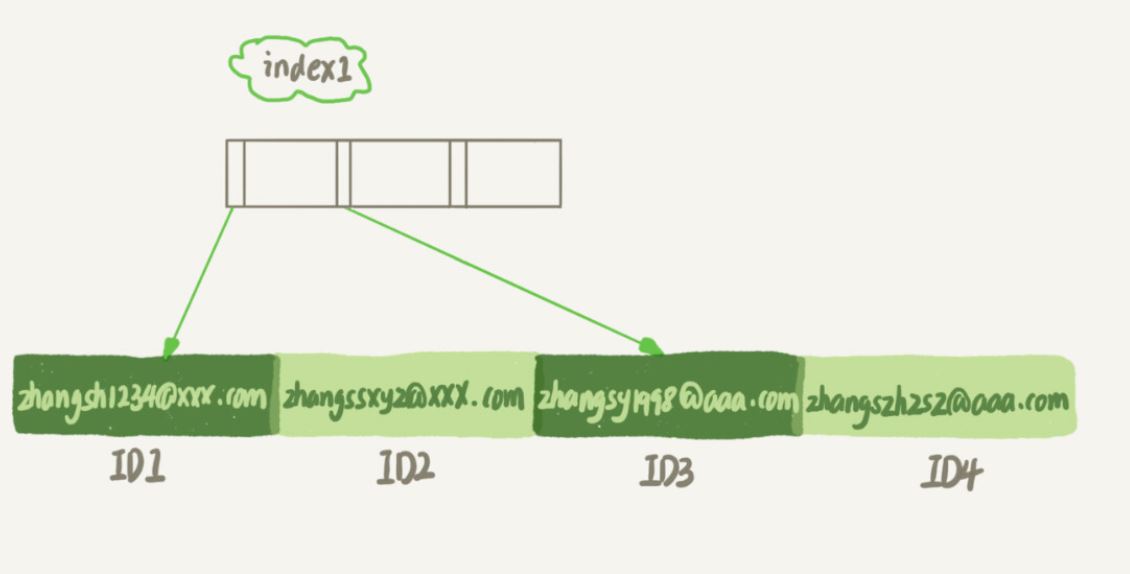
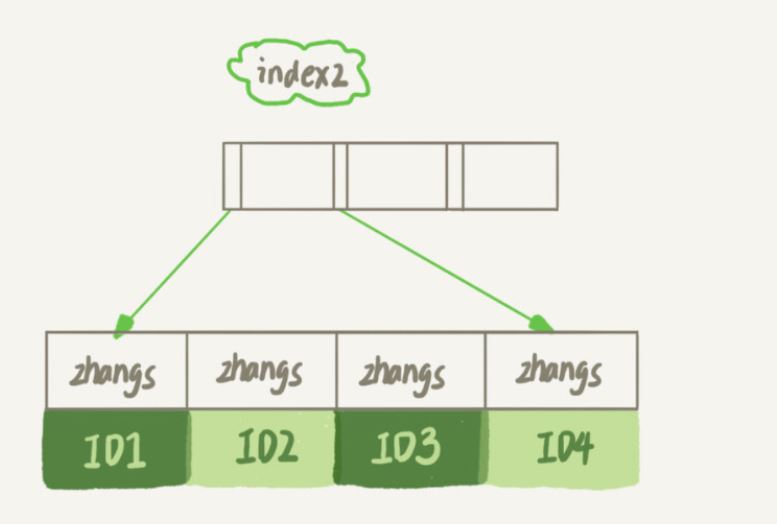
明顯看出email(6) 這個索引結構所佔用的空間會更小
#5)email(6) 這個索引結構有什麼缺點嗎?
可能會增加額外的記錄掃描次數
#6)下面這個語句,在這兩個索引定義下分別是怎麼執行的?
select id,name,email from SUser where email='zhangssxyz@xxx.com';
index1(即email 整個字串的索引結構),執行順序
從index1 索引樹找到滿足索引值是’zhangssxyz@xxx .com’的這條記錄,取得ID2 的值;
回表查到主鍵值是ID2 的行,判斷email 的值是正確的,將這行記錄加入結果集;
繼續在index索引樹的下一筆記錄,發現已經不滿足email='zhangssxyz@xxx.com’的條件了,循環結束。
這個過程中,只需要回主鍵索引取一次數據,所以系統認為只掃描了一行。
index2(即email(6) 索引結構),執行順序
從index2 索引樹找到滿足索引值是’zhangs’的記錄,找到的第一個是ID1;
到主鍵上查到主鍵值是ID1 的行,判斷出email 的值不是’zhangssxyz@xxx.com’,這行記錄丟棄;
取index2 上剛剛查到的位置的下一筆記錄,發現仍然是’zhangs’,取出ID2,再到ID 索引上取整行然後判斷,這次值對了,將這行記錄加入結果集;
#重複上一步,直到在idxe2 上取到的值不是’zhangs’時,循環結束。
在這個過程中,要回主鍵索引取 4 次數據,也就是掃描了 4 行。
7)透過上面的對比,能得到什麼結論?
使用前綴索引後,可能會導致查詢語句讀取資料的次數變多。
8)前綴索引真的一無是處嗎?
如果我們定義的index2 不是email(6) 而是email(7),那滿足前綴’zhangss’的記錄只有一個,直接就查到ID2了,只掃描一行就結束了。
9)那麼使用前綴索引有哪些注意事項?
長度選擇合理
10)當要給字串建立前綴索引時,我咋知道我該用多長的前綴索引呢?
統計索引上有多少個不同的值來判斷要使用多長的前綴。
11)怎麼統計索引上有多少個不同的值?
select count(distinct email) as L from SUser;
12)拿到了索引對應的有多少個不同的值之後下一步該做什麼?
-
依序選取不同長度的前綴來看這個值
select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from SUser;
然後,在L4~L7 中,找出第一個不小於L * 95% 的值,說明透過這個索引可以找出百分之95以上的資料。
13)前綴索引對覆寫索引的影響為何?
下面這個 SQL 語句:
select id,email from SUser where email='zhangssxyz@xxx.com';
與前面範例中的 SQL 語句
select id,name,email from SUser where email='zhangssxyz@xxx.com';
相比,第一個語句只要求傳回 id 和 email 欄位。
如果使用 index1(即 email 整個字串的索引結構)的話,查email的話就能得到ID,那就不用回表了,這個就是覆蓋索引。
用 index2(即 email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。
14)那我把index2 的定义修改为 email(18) 的前缀索引不就行了?
这个18是你自己定义的,系统不知道18这个长度是否已经大于我的email长度,所以它还是会回表去查一下验证。
总而言之:使用前缀索引就用不上覆盖索引对查询性能的优化了
针对类似于邮箱这样的字段,使用前缀索引可能会产生不错的效果。但是,遇到身份证这种前缀的区分度不够好的情况时,我们要怎么办呢?
索引选取的要更长一些。
但是所以越长的话,占的磁盘空间更大,相同的一页能放下的索引值就变少了,反而会影响查询效率。
16)如果我们能够确定业务需求里面只有按照身份证进行等值查询的需求,还有没有别的处理方法呢?
-
既然正过来相同的多,那我就把它倒过来存。查询时候这样查
select field_list from t where id_card = reverse('input_id_card_string');
使用 的时候用count(distinct) 方法去做个验证
-
使用 hash 字段。在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
alter table t add id_card_crc int unsigned, add index(id_card_crc);
新记录插入时必须使用 crc32() 函数生成校验码,并填入新字段中。由于校验码可能存在冲突,也就是说两个不同的身份证号通过 crc32() 函数得到的结果可能是相同的,所以你的查询语句 where 部分要判断 id_card 的值是否精确相同。
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
这样,索引的长度变成了 4 个字节(int类型),比原来小了很多
17)使用倒序存储和使用 hash 字段这两种方法有什么异同点?
相同点:都不支持范围查询
倒序存储的字段上创建的索引是按照倒序字符串的方式排序的,已经没有办法利用索引方式查出身份证号码在[ID_X, ID_Y]的所有市民了。同样地,hash 字段的方式也只能支持等值查询。
区别
从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,而 hash 字段的方式需要额外调用一次 crc32() 函数。以仅考虑这两个函数的计算复杂度为前提,reverse 函数对 CPU 资源的额外消耗将较少。
就查询性能而言,采用哈希字段方式的查询更具可靠性。虽然crc32算法不可避免地存在冲突的风险,但这种风险极其微小,因此我们可以认为查询时平均扫描行数接近于1。使用倒序存储方式仍然需要使用前缀索引来进行扫描,因此会增加扫描的行数。
案例:如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是”学号 @gmail.com", 而学号的规则是:十五位的数字,其中前三位是所在城市编号、第四到第六位是学校编号、第七位到第十位是入学年份、最后五位是顺序编号。
学生必须输入正确的登录名和密码,方可继续使用系统。如果只考虑登录验证这个行为,你会如何为登录名设计索引?
如果一个学校每年预计2万新生,50年才100万记录,如果直接使用全字段索引,可以节省多少存储空间?。除非遇到超大规模数据,否则不需要使用后两种方法,从而避免了开发转换和限制风险
在实际操作中,只需对所有字段进行索引,一个学校的数据库数据量和查询负担不会变得很大。 如果单从优化数据表的角度: \1. 后缀@gmail可以单独一个字段来存,或者用业务代码来保证, \2. 城市编号和学校编号估计也不会变,也可以用业务代码来配置 \3. 然后直接存年份和顺序编号就行了,这个字段可以全字段索引
以上是MySQL如何為字串欄位加索引的詳細內容。更多資訊請關注PHP中文網其他相關文章!