
順序決策與基礎模型如何交叉互惠? Google、柏克萊等探討更多可能

- 王林轉載
- 2023-05-27 21:52:411488瀏覽
在廣泛資料集上基於自監督學習的預訓練基礎模型,已經展現出將知識遷移到不同下游任務的優秀能力。因此,這些模型也被應用到長期推理、控制、搜尋和規劃等更複雜的問題,或部署在對話、自動駕駛、醫療保健和機器人等應用中。未來它們也會提供介面給外部實體和智能體,例如在對話應用中,語言模型與人進行多輪交流;在機器人領域,感知控制模型在真實環境中執行動作。
這些場景為基礎模型提出了新的挑戰,包括:1) 如何從外部實體(如人對對話品質的評價)的回饋中學習,2) 如何適應大規模語言或視覺資料集中不常見的模態(如機器人動作),3) 如何在未來進行長期的推理和規劃。
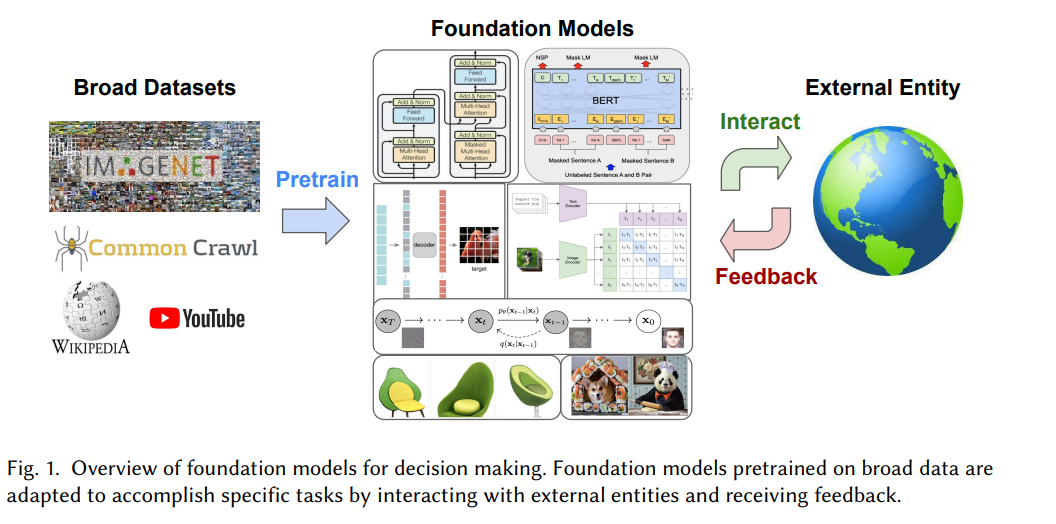
這些問題一直是傳統意義上順序決策的核心,涵蓋了強化學習、模仿學習、規劃、搜尋和最優控制等領域。與基礎模型使用數十億影像和文字 token 的廣泛資料集進行預訓練的範式相反,以往關於順序決策的工作主要集中在任務特定或具有有限先驗知識的白板設定上。
儘管缺少或沒有先驗知識讓順序決策看起來很難,但是對順序決策的研究已經在多個任務上超越了人類表現,如玩棋盤遊戲、雅達利(Atari)電子遊戲以及操作機器人完成導航和操作等。
然而,由於這些方法學習從零開始解決任務而沒有來自視覺、語言或其它數據集的廣泛知識,因此通常在泛化和样本效率方面表現不佳,例如需要7 塊GPU 運行一天才能解決單一雅達利遊戲。直覺上,類似基礎模型所使用的廣泛資料集也應該對順序決策制定模型有用。舉例而言,網路上有無數關於如何玩雅達利遊戲的文章和影片。同樣地,有關物件和場景屬性的大量知識對於機器人非常有用,關於人類願望和情感的知識也可以改善對話模型。
雖然因為應用和關注點不同,基礎模型和順序決策的研究大致上是不相交的,但交會的研究也越來越多。在基礎模型方面,隨著大語言模型的出現,目標應用從簡單的零樣本或少樣本任務擴展到現在需要長期推理或多次交互作用的問題 。相反地在順序決策領域,受到大規模視覺和語言模型成功的啟發,研究人員開始為學習多模型、多任務和通用互動智能體準備越來越大的資料集。
兩者領域之間的界線變得越來越模糊,一些最近的工作研究了預訓練基礎模型(例如CLIP 和ViT)在視覺環境中bootstrap 互動智能體的訓練,而其他工作則研究了基礎模型作為透過強化學習和人類回饋進行優化的對話智能體。還有一些工作還調整大型語言模型以與外部工具交互,例如搜尋引擎、計算器、翻譯工具、MuJoCo 模擬器和程式解釋器。
最近,Google大腦團隊、UC 柏克萊和 MIT 的研究者撰文表示,基礎模型和互動式決策研究結合會讓彼此受益。一方面,將基礎模型應用於涉及外部實體的任務中,可以從互動式回饋和長期規劃中受益。另一方面,順序決策可以利用基礎模型的世界知識更快地解決任務並進行更好的泛化。

論文網址:https://arxiv.org/pdf/2303.04129v1.pdf
為了在這兩個領域的交集上推動進一步的研究,研究者限定了用於決策的基礎模型的問題空間。同時提供了理解目前研究的技術工具,回顧了目前存在的挑戰和未解決的問題,並預測了解決這些挑戰的潛在解決方案和有前景的方法。
論文概覽
論文主要分為以下 5 個主要章節。
第 2 章回顧了順序決策的相關背景,並提供了一些基礎模型和決策制定最好一起考慮的範例情境。隨後講述了圍繞基礎模型如何建立決策制定係統的不同組件。

第3 章探討了基礎模型如何作為行為生成式模型(例如技能發現)和環境生成式模型(例如進行模型為基礎的推演)。
第4 章探討了基礎模型如何作為狀態、動作、獎勵和轉移動態的表示學習器(例如即插即用的視覺- 語言模型、基於模型的表示學習)。

第5 章探討了語言基礎模型如何作為互動式智能體與環境,使得可以在順序決策架構(語言模型推理、對話、工具使用)下考慮新問題和應用。

最後一章,研究者概述了未解決的問題和挑戰,並提出了潛在的解決方案(例如如何利用廣泛的數據、如何建構環境以及基礎模型和順序決策的哪些方面可以改進)。

更多細節內容請參閱原始論文。
以上是順序決策與基礎模型如何交叉互惠? Google、柏克萊等探討更多可能的詳細內容。更多資訊請關注PHP中文網其他相關文章!