cx | 93 | #深圳 | 男 |
|
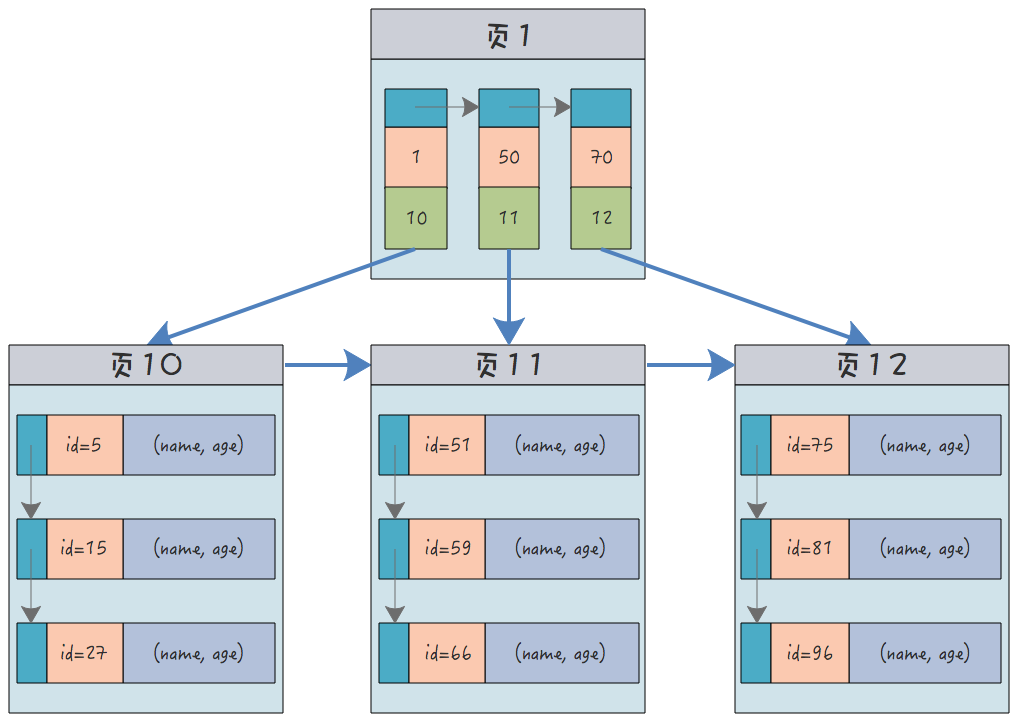
那麼它的叢集索引大概就是這個樣子:

那麼大家可以看到,葉子上既有主鍵值(索引)又有資料行,節點上則只有主鍵值(索引)。
小夥伴們想想,MySQL 表中的資料在磁碟中只可能保存一份,不可能保存兩份,所以,在一個表中,叢集索引只可能有一個,不可能有多個。
2. 叢集索引和主鍵
有的小夥伴搞不清楚這兩者之間的關係,甚至將兩者劃等號,這是一個巨大的迷思。
在有的資料庫中,支援開發者自由的選擇使用哪一個索引作為叢集索引,但是 MySQL 中是不支援這個特性的。
在MySQL 中,如果表本身就有設定主鍵,那麼主鍵就是叢集索引;如果表本身沒有設定主鍵,則會選擇表中的一個唯一且非空的索引來作為叢集索引;如果表中連唯一非空的索引都沒有,那麼就會自動選擇表中的隱式主鍵來作為聚集索引。松哥將在未來的文章中向大家介紹 MySQL 表的隱式主鍵。
不過一般來說,還是建議大家自己來為表設定主鍵,因為隱式主鍵是自增的,自增的都會存在一個問題:在自增值上會存在非常高的鎖定競爭問題,主鍵的上界會稱為熱點數據,因為所有的插入操作都要主鍵自增,又不能重複,所以會發生鎖定競爭進而導致效能降低。
根據上面的介紹,我們可以總結出MySQL 中叢集索引和主鍵索引的關係如下:
叢集索引不一定是主鍵索引。
主鍵索引一定是叢集索引。
3. 叢集索引優缺點
先來說優點:
相互關聯的資料我們可以將之保存在一起。例如有一個用戶訂單表,我們可以根據用戶ID 訂單ID 來聚集所有數據,用戶ID 可能會重複,訂單ID 則不會重複,這樣我們就能夠將一個用戶相關的訂單數據都保存在一起,如果需要查詢一個用戶的所有訂單,就會非常快,只需要少量的磁碟IO 就可以做到。
不需要回表,因此資料存取速度更快。在叢集索引中,索引和資料都在同一棵 B Tree 上,因此從叢集索引中取得的資料比從非叢集索引上取得資料更快(非叢集索引需要回資料表)。
對於第一點的案例,如果我們想根據使用者ID 查詢到這個使用者所有的訂單ID,那麼此時都不用去到葉子結點了,因為支節點上就有我們需要的數據,所以直接利用覆蓋索引的特性,就可以讀取到所需的數據。
這些就是叢集索引一些常見的優點,我們在日常的表設計中,其實應該充分利用好這些優點。
再來看看缺點:
小夥伴們發現,前面我們說的叢集索引的優勢主要是叢集索引減少了IO 次數,從而提高了資料庫的效能,但是有的IO 密集型應用,可能直接上一個足夠大的內存,把資料都讀取到內存中操作,此時聚簇索引就沒有啥優勢了。
隨機主鍵會導致頁分裂問題,主鍵順序插入的話,相對來說效率會高一些,因為在B Tree 中只需要不斷往後面追加即可;但是主鍵如果是非順序插入的話,效率就會低很多,因為可能會牽涉到頁分裂問題。以上面那張圖為例,假設每個節點可以保存三個數據,現在我們要插入一個主鍵是4.5 的記錄,那麼就需要把主鍵為5 的值往後移動,進而導致主鍵為8 的節點也要往後移動。頁分裂會導致資料插入效率降低並且佔用更多的儲存空間。
非聚集索引(二級索引)查詢的時候需要回表。因為一個索引就是一棵索引樹,資料都在叢集索引上,所以如果使用非叢集索引進行搜索,非叢集索引的葉子上儲存的是主鍵值,先找到主鍵值,然後拿著主鍵值再來聚集索引上搜索,這樣一共就查詢了兩棵索引樹,這就是回表。
#