
Redis的基礎資料結構是怎麼樣的

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-27 16:02:341459瀏覽
整數集合
如果一個集合只包含不多的整數元素,那麼Redis會使用整數集合intset。首先來看 intset 的資料結構:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
其實 intset 的資料結構比較好理解。一個資料保存元素,length 保存元素的數量,也就是contents的大小,encoding 用來保存資料的編碼方式。
透過程式碼我們可以知道,encoding 的編碼型別包含了:
#define INTSET_ENC_INT16 (sizeof(int16_t)) #define INTSET_ENC_INT32 (sizeof(int32_t)) #define INTSET_ENC_INT64 (sizeof(int64_t))
其實我們可以看出來。 Redis encoding的類型,就是指資料的大小。作為一個記憶體資料庫,採用這種設計就是為了節約記憶體。
既然有從小到大的三個資料結構,在插入資料的時候盡可能使用小的資料結構來節約內存,如果插入的資料大於原有的資料結構,就會觸發擴容。
擴充有三個步驟:
根據新元素的類型,修改整個陣列的資料類型,並重新分配空間
將原有的數據,裝換為新的數據類型,重新放到應該在的位置上,且保存順序性
- ##再插入新元素
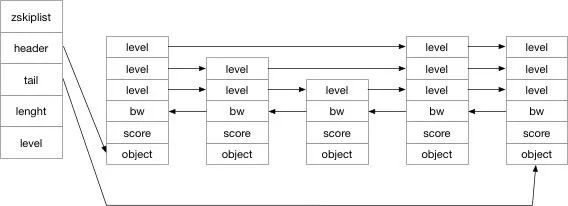
/* ZSETs use a specialized version of Skiplists *//*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;所以根據這個程式碼我們可以畫出如下的結構圖:
- 省記憶體。
- 在使用ZRANGE或ZREVRANGE時,涉及的是典型的鍊錶操作場景。時間複雜度的表現和平衡樹差不多。
- 最重要的一點是跳躍表的實作很簡單就能達到 O(logN)的等級。
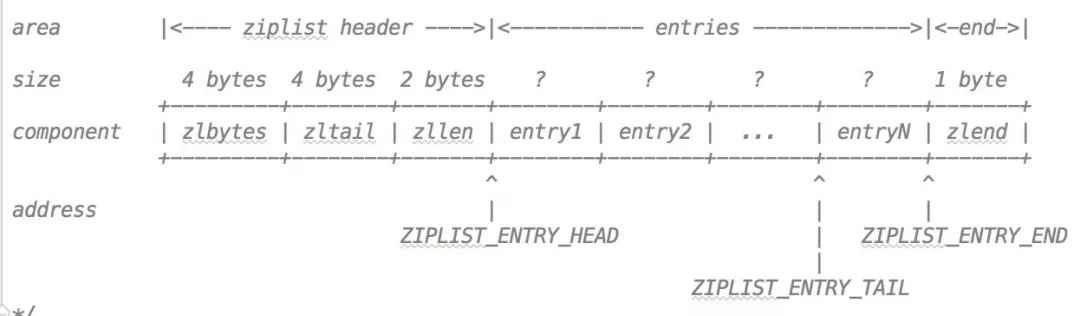
zlbytes 表示的是整個壓縮列表使用的記憶體位元組數
zltail 指定了壓縮清單的尾節點的偏移量
是壓縮清單entry 的數量
是ziplist 的節點
標記壓縮清單的末端這個清單中還有單一指標:
清單開始節點的頭偏移
清單結束節點的頭偏移
# 列表的尾節點結束的偏移量
再看看一個entry 的結構:
/*
* 保存 ziplist 节点信息的结构
*/
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;
依序解釋這幾個參數。
prevrawlen 前節點的長度,這裡多了一個 size,其實是記錄了 prevrawlen 的尺寸。 Redis 為了節省記憶體並不是直接使用預設的 int 的長度,而是逐漸升級的。 同理 len 記錄的是目前節點的長度,
lensize 記錄的是 len 的長度。
headersize 就是前文提到的兩個 size 總和。
encoding 就是這個節點的資料型態。這裡注意一下 encoding 的類型只包括整數和字串。
節點的指針,不用過多的解釋。
###需要注意一點,因為每個節點都保存了前一個節點的長度,如果發生了更新或刪除節點,則這個節點之後的資料也需要修改,有一種最壞的情況就是如果每個節點都處於需要擴容的零界點,就會造成這個節點之後的節點都要修改size 這個參數,引發連鎖反應。這時候就是 壓縮鍊錶最壞的時間複雜度 O(n^2)。不過所有節點都處於臨界值,這樣的機率可以說比較小。 ###以上是Redis的基礎資料結構是怎麼樣的的詳細內容。更多資訊請關注PHP中文網其他相關文章!