
簡述機器學習加速器的五種類型

- 王林轉載
- 2023-05-25 14:55:251761瀏覽
譯者 | 布加迪
審校 | 孫淑娟
#過去十年是深度學習的時代。我們為從AlphaGo到DELL-E 2的一系列重大事件而感到興奮。日常生活中出現了不計其數的由人工智慧(AI)驅動的產品或服務,包括Alexa設備、廣告推薦、倉庫機器人和自動駕駛汽車等。

近年來,深度學習模型的規模呈指數級增長。這不是什麼新聞了:Wu Dao 2.0模型含有1.75兆參數,在SageMaker訓練平台的240個ml.p4d.24xlarge實例上訓練GPT-3大約只需25天。
但隨著深度學習訓練和部署的發展,它變得越來越具有挑戰性。由於深度學習模型的發展,可擴展性和效率是訓練和部署的兩大挑戰。
本文將總結機器學習(ML)加速器的五大類型。
了解AI工程中的ML生命週期
在全面介紹ML加速器之前,不妨先看看ML生命週期。
ML生命週期是資料和模型的生命週期。資料可謂是ML的根源,決定模型的品質。生命週期中的每個面向都有機會加速。
MLOps可以讓ML模型部署的流程自動化。但由於操作性質,它局限於AI工作流程的橫向過程,無法從根本上改善訓練和部署。
AI工程遠遠超越MLOps的範疇,它可以整體(橫向和縱向)設計機器學習工作流程的過程以及訓練和部署的架構。此外,它可以透過整個ML生命週期的有效編排來加速部署和訓練。
基於整體式ML生命週期和AI工程,有五種主要類型的ML加速器(或加速方面):硬體加速器、AI運算平台、AI框架、ML編譯器和雲端服務。先看下面的關係圖。
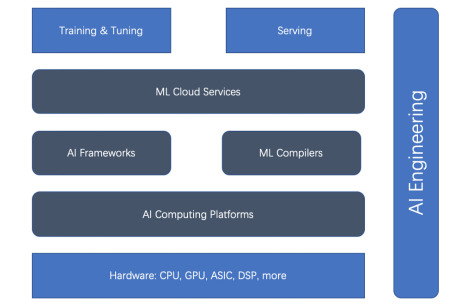
圖1. 訓練與部署加速器的關係
我們可以看到,硬體加速器和AI框架是加速的主流。但最近,ML編譯器、AI運算平台和ML雲端服務已變得越來越重要。
下面逐一介紹。
1. AI框架
在談到加速ML訓練和部署時,選擇合適的AI框架無法迴避。遺憾的是,不存在一應俱全的完美或最佳AI框架。廣泛用於研究和生產的三種AI框架是TensorFlow、PyTorch和JAX。它們在不同的方面各有千秋,例如易用性、產品成熟度和可擴展性。
TensorFlow:TensorFlow是旗艦AI框架。 TensorFlow一開始就主導深度學習開源社群。 TensorFlow Serving是個定義完備的成熟平台。對於網路和物聯網來說,TensorFlow.js和TensorFlow Lite也已成熟。
但由於深度學習早期探索的局限性,TensorFlow 1.x旨在以非Python的方式建立靜態圖。這成為使用「eager」模式進行即時評估的障礙,這種模式讓PyTorch可以在研究領域迅速提升。 TensorFlow 2.x試圖迎頭趕上,但遺憾的是,從TensorFlow 1.x升級到2.x很麻煩。
TensorFlow也引入了Keras,以便整體上更容易使用,另引入了最佳化編譯器的XLA(加速線性代數),以加快底層速度。
PyTorch:憑藉其eager模式和類似Python的方法,PyTorch是如今深度學習界的主力軍,用於從研究到生產的各個領域。除了TorchServe外,PyTorch還與跟框架無關的平台(例如Kubeflow)整合。此外,PyTorch的人氣與Hugging Face的Transformers庫大獲成功密不可分。
JAX:Google推出了JAX,基於裝置加速的NumPy和JIT。正如PyTorch幾年前所做的那樣,它是一種更原生的深度學習框架,在研究領域迅速受到追捧。但它還不是谷歌聲稱的「官方」谷歌產品。
2. 硬體加速器
毫無疑問,英偉達的GPU 可以加速深度學習訓練,不過它最初是為視訊卡設計的。
通用GPU出現後,用於神經網路訓練的圖形卡人氣爆棚。這些通用GPU可以執行任意程式碼,而不僅僅是渲染子程式。英偉達的CUDA程式語言提供了一種用類似C的語言寫任意程式碼的方法。通用GPU有相對方便的程式設計模型、大規模平行機制和高記憶體頻寬,現在為神經網路程式設計提供了一個理想的平台。
如今,英偉達支援從桌面到行動、工作站、行動工作站、遊戲機和資料中心的一系列GPU。
隨著英偉達GPU大獲成功,一路走來不乏後繼者,例如AMD的GPU和Google的TPU ASIC等。
3. AI運算平台
如前所述,ML訓練和部署的速度很大程度上依賴硬體(例如GPU和TPU)。這些驅動平台(即AI計算平台)對效能至關重要。有兩個眾所周知的AI計算平台:CUDA和OpenCL。
CUDA:CUDA(運算統一裝置架構)是英偉達於2007年發布的平行程式設計範式。它是為圖形處理器和GPU的眾多通用應用設計的。 CUDA是專有API,僅支援英偉達的Tesla架構GPU。 CUDA支援的顯示卡包括GeForce 8系列、Tesla和Quadro。
OpenCL:OpenCL(開放運算語言)最初由蘋果公司開發,現在由Khronos團隊維護,用於異質運算,包括CPU、GPU、DSP及其他類型的處理器。這種可移植語言的適應性足夠強,可以讓每個硬體平台實現高效能,包括英偉達的GPU。
英偉達現在符合OpenCL 3.0,可用於R465及更高版本的驅動程式。使用OpenCL API,人們可以在GPU上啟動使用C程式語言的有限子集編寫的計算核心。
4. ML編譯器
ML編譯器在加速訓練和部署方面起著至關重要的作用。 ML編譯器可顯著提高大規模模型部署的效率。有許多流行的編譯器,例如Apache TVM、LLVM、谷歌MLIR、TensorFlow XLA、Meta Glow、PyTorch nvFuser和Intel PlaidML。
5. ML雲端服務
ML雲端平台和服務在雲端管理ML平台。它們可以透過幾種方式來優化,以提高效率。
以Amazon SageMaker為例。這是一種領先的ML雲端平台服務。 SageMaker為ML生命週期提供了廣泛的功能特性:從準備、建置、訓練/調優到部署/管理,不一而足。
它優化了許多方面以提高訓練和部署效率,例如GPU上的多模型端點、使用異質叢集的經濟高效的訓練,以及適合基於CPU的ML推理的專有Graviton處理器。
結語
隨著深度學習訓練和部署規模不斷擴大,挑戰性也越來越大。提高深度學習訓練和部署的效率很複雜。基於ML生命週期,有五個面向可以加速ML訓練和部署:AI框架、硬體加速器、運算平台、ML編譯器和雲端服務。 AI工程可以將所有這些協調起來,利用工程原理全面提高效率。
原文標題:#5 Types of ML Accelerators#,作者:Luhui Hu
以上是簡述機器學習加速器的五種類型的詳細內容。更多資訊請關注PHP中文網其他相關文章!