
阻礙人工智慧進步的八個問題

- PHPz轉載
- 2023-05-22 10:06:321827瀏覽

今天的人工智慧 (AI) 是有限的。它還有很長的路要走。
一些AI研究人員發現,電腦透過反覆試驗學習的機器學習演算法已經成為一種「神秘力量」。
不同類型的人工智慧
人工智慧 (AI) 的最新進展正在改善我們生活的許多方面。
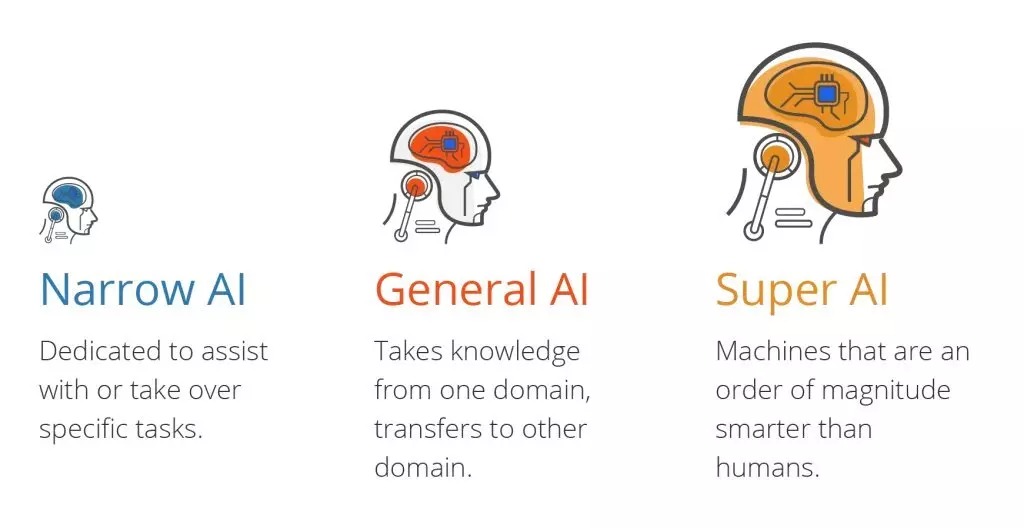
人工智慧有三種:
- 狹義人工智慧 (ANI),具有狹窄的能力範圍。
- 通用人工智慧 (AGI),與人類能力相當。
- 人工超級智慧 (ASI),比人類更有智慧。
今天的人工智慧有什麼問題?
今天的人工智慧主要由統計學習模型和演算法驅動,稱為數據分析、機器學習、人工神經網路或深度學習。它作為 IT 基礎設施(ML平台、演算法、資料、計算)和開發堆疊(從庫到語言、IDE、工作流程和視覺化)的組合來實現。
總之,其涉及:
- 一些應用數學、機率論和統計
- 一些統計學習演算法,邏輯迴歸,線性迴歸,決策樹和隨機森林
- 一些機器學習演算法,有監督、無監督和強化
- 一些人工神經網路、深度學習演算法和模型,透過多層過濾輸入資料以預測和分類資訊
- 一些優化(壓縮和量化)訓練的神經網路模型
- 一些統計模式和推論,例如高通神經處理SDK,
- 一些程式語言,如Python 和R.
- 一些ML平台、框架和運行時,例如PyTorch、ONNX、Apache MXNet、TensorFlow、Caffe2、CNTK、SciKit-Learn 和Keras,
- 一些整合開發環境(IDE),如PyCharm、 Microsoft VS Code、Jupyter、MATLAB等,
- 一些實體伺服器、虛擬機器、容器、專用硬體(如GPU)、基於雲端的運算資源(包括虛擬機器、容器和無伺服器運算)。
當今使用的大多數 AI 應用程式都可以歸類為狹義 AI,稱為弱 AI。
它們都缺少通用人工智慧和機器學習,這由三個關鍵的互動引擎定義:
- 世界模型[表示、學習和推理] 機,或現實模擬機(世界超圖網)。
- 世界知識引擎(全球知識圖譜)
- 世界資料引擎(全球資料圖網路)
通用AI和ML和DL應用/機器/系統的差別在於將世界理解為多個似是而非的世界狀態表示,其現實機器和全球知識引擎以及世界資料引擎。
它是General/Real AI Stack 最重要的組成部分,與其真實世界的資料引擎交互,並提供智慧功能/能力:
- ##處理關於世界的資訊
- 估計/計算/學習世界模型的狀態
- 概括其資料元素、點、集合
- #指定其資料結構和型別
- 遷移其學習
- 將其內容語境化
- 形成/發現因果資料模式,如因果規律、規則和規律
- 推斷所有可能的互動、原因、影響、循環、系統和網絡中的因果關係
- 以不同的範圍和規模以及不同的概括和規範水平預測/回顧世界的狀態
- 有效地和高效地與世界互動,適應它,導航它並根據它的智能預測和處方操縱它的環境
 #
#
AI Ops — 管理 AI 的端到端生命週期
今天的人工智慧的能力來自“機器學習”,需要針對每個不同的現實世界場景配置和調整演算法。這使得它非常需要人工操作,並且需要花費大量時間來監督其開發。這種手動過程也容易出錯、效率低且難以管理。更不用說缺乏能夠配置和調整不同類型演算法的專業知識。
配置、調整和模型選擇越來越自動化,Google、微軟、亞馬遜、IBM 等所有大型科技公司都推出了類似的AutoML平台,使機器學習模型建置流程自動化。
AutoML涉及自動化建立基於機器學習演算法的預測模型所需的任務。這些任務包括資料清理和預處理、特徵工程、特徵選擇、模型選擇和超參數調整,手動執行這些任務可能很乏味。
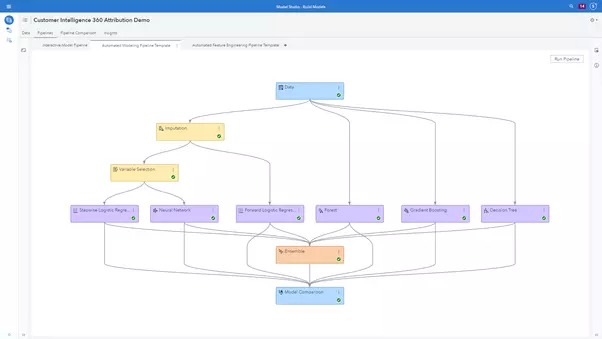
SAS4485-2020.pdf
所呈現的端對端ML 管道由3 個關鍵階段組成,同時缺少所有資料的來源,即世界本身:
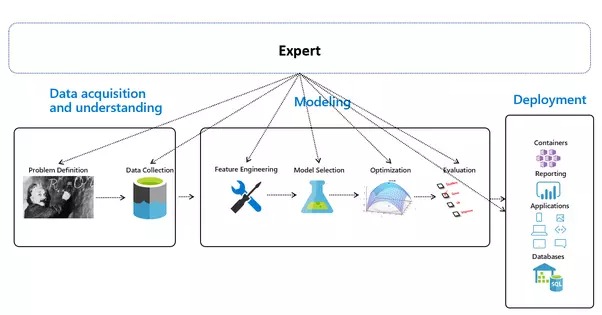
自動化機器學習-概述
Big-Tech AI 的關鍵秘密是作為暗深度神經網路的Skin-Deep Machine Learning,它的模型需要透過大量標記資料和包含盡可能多的層的神經網路架構進行訓練。
每個任務都需要其特殊的網路架構:
- 用於回歸和分類的人工神經網路(ANN)
- #用於電腦視覺的捲積神經網路(CNN)
- 用於時間序列分析的遞歸神經網路(RNN)
- #用於特徵提取的自組織映射
- 用於推薦系統的深度波茲曼機
- 推薦系統的自動編碼器
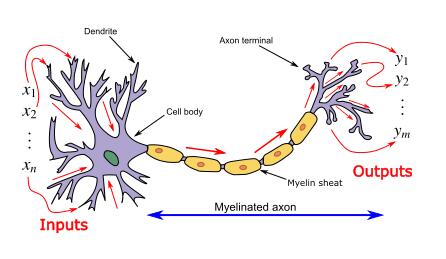
ANN作為一種訊息處理範式被引入,似乎是受到生物神經系統/大腦處理訊息的方式的啟發。而這樣的人工神經網路被表示為“通用函數逼近器”,它可以學習/計算各種激活函數。
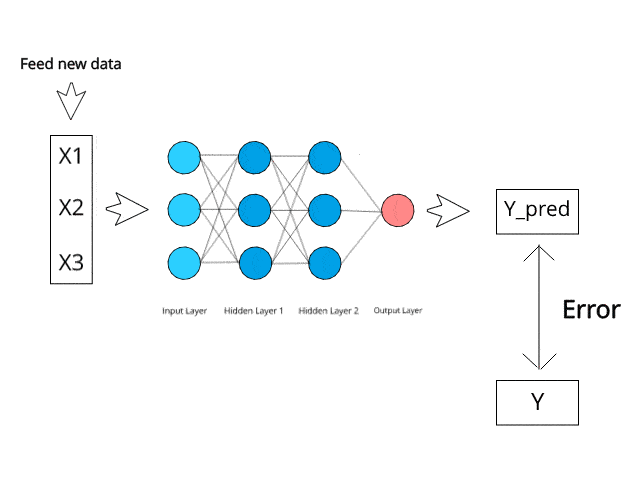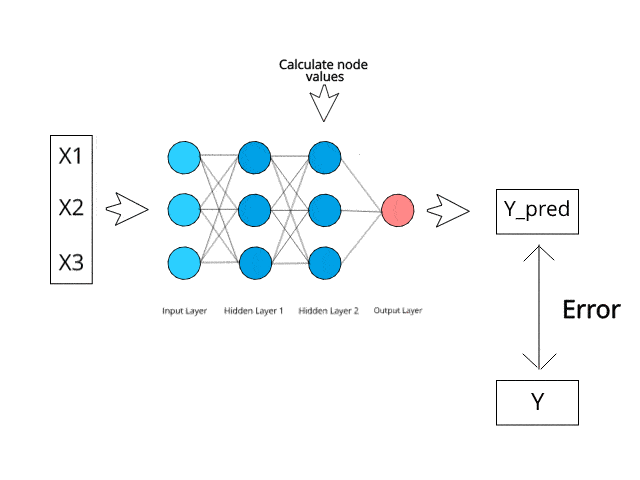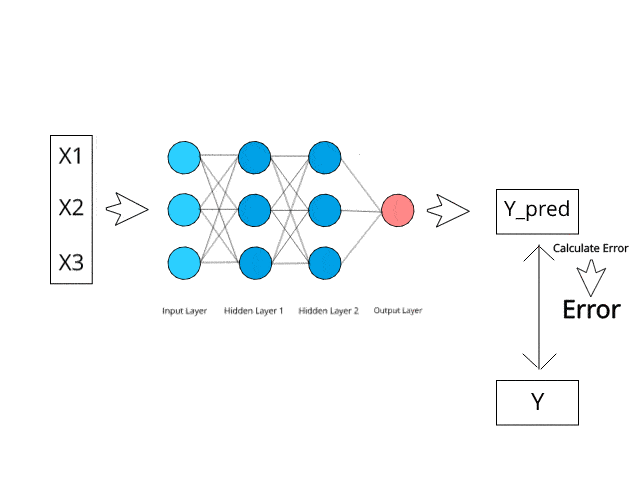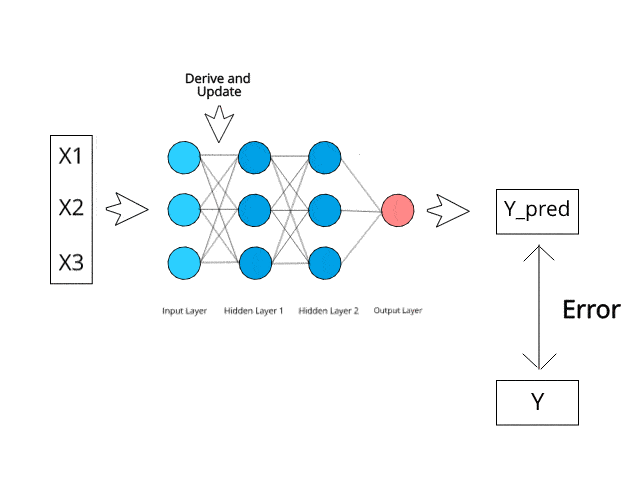
神經網路在測試階段透過特定的反向傳播和糾錯機制進行計算/學習。
試想一下,透過最小化錯誤,這些多層系統有望有一天自己學習和概念化想法。
人工神經網路(ANN) 簡介
總而言之,幾行R或Python程式碼就足以實現機器智能,並且有大量線上資源和教程可以訓練準神經網絡,例如各種深度偽造網絡,操縱圖像-視頻-音頻-文本,對世界的了解為零,如生成對抗網絡、BigGAN、CycleGAN、StyleGAN、GauGAN、Artbreeder、DeOldify等。
他們創造和修改面孔、風景、通用圖像等,對它的全部內容了解為零。
使用循環一致的對抗網路進行不成對的圖像到圖像的轉換,使2019年成為新人工智慧時代的 14 種深度學習和機器學習用途。
有無數的數位工具和框架以它們自己的方式運作:
- #開放語言-Python是最受歡迎的,R和 Scala也在其中。
- 開放框架-Scikit-learn、XGBoost、TensorFlow等。
- 方法和技術——從回歸到最先進的GAN和RL的經典ML技術
- 提高生產力的能力——可視化建模、AutoAI 以幫助進行特徵工程、演算法選擇和超參數最佳化
- 開發工具-DataRobot、H2O、Watson Studio、Azure ML Studio、Sagemaker、Anaconda 等。
令人遺憾的是,資料科學家的工作環境:scikit-learn、R、SparkML、Jupyter、R、Python、XGboost、Hadoop、Spark、TensorFlow、Keras、PyTorch、Docker、Plumbr等等,不勝枚舉。
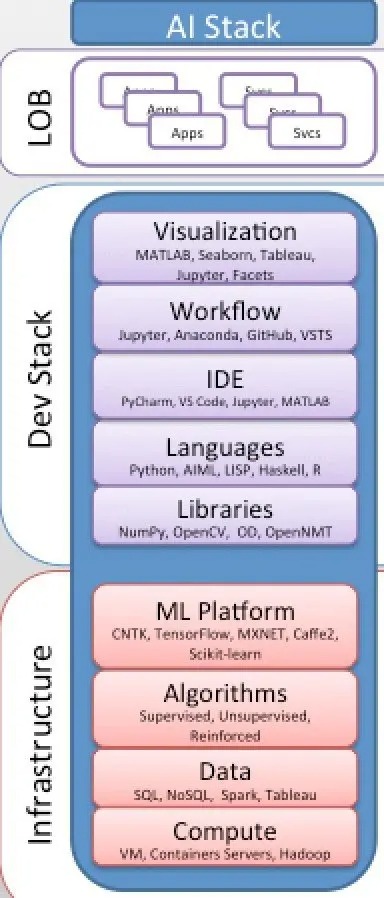
現代AI 堆疊與AI 即服務消費模式
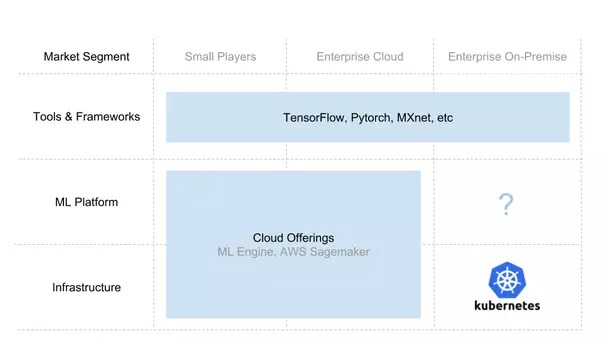
建構AI 堆疊
冒充人工智慧的,其實是假冒牌的人工智慧。在最好的情況下,它是一種自動學習技術,ML/DL/NN 模式識別器,本質上是數學和統計性質的,無法憑直覺行事或對其環境建模,具有零智能、零學習和零理解。
阻礙人工智慧進步的問題
儘管有許多優點,人工智慧並不完美。以下是阻礙人工智慧進步的8 個問題以及根本錯誤所在:
1、缺乏資料
人工智慧需要大量資料集進行訓練,這些資料集應該具有包容性/公正性,且品質良好。有時他們必須等待產生新資料。
2、耗時
人工智慧需要足夠的時間讓演算法學習和發展到足以以相當高的準確性和相關性實現其目的。它還需要大量資源才能發揮作用。這可能意味著對您的電腦能力有額外的要求。
3、結果解釋不力
另一個主要挑戰是準確解釋演算法產生的結果的能力,也必須根據自己的目的仔細選擇演算法。
4、高度易錯
人工智慧是自主的,但極易出錯。假設使用足夠小的資料集訓練演算法,使其不具包容性。最終會得到來自有偏見的訓練集的有偏見的預測。在機器學習的情況下,這樣的失誤會引發一系列錯誤,這些錯誤可能會在很長一段時間內未被發現。當他們確實被注意到時,需要相當長的時間來識別問題的根源,甚至更長時間來糾正它。
5、倫理問題
相信資料和演算法勝過我們自己的判斷的想法有其優點和缺點。顯然,我們從這些演算法中受益,否則,我們一開始就不會使用它們。這些演算法使我們能夠透過使用可用數據做出明智的判斷來自動化流程。然而,有時這意味著用演算法取代某人的工作,這會帶來倫理後果。此外,如果出現問題,我們該責怪誰?
6、缺乏技術資源
人工智慧還是比較新的技術。從啟動程式碼到流程的維護和監控,都需要機器學習專家來維護流程。人工智慧和機器學習產業對市場來說仍然比較新鮮。以人力形式尋找足夠的資源也很困難。因此,缺乏可用於開發和管理機器學習科學物質的有才華的代表。數據研究人員通常需要混合空間洞察力,以及從頭到尾的數學、技術和科學知識。
7、基礎設施不足
人工智慧需要大量的資料處理能力。繼承框架無法處理壓力下的責任和約束。應該檢查基礎架構是否可以處理人工智慧中的問題.、如果不能,應該使用良好的硬體和適應性強的儲存來完全升級。
8、緩慢的結果和偏差
人工智慧非常耗時。由於數據和要求過載,提供結果的時間比預期的要長。專注於資料庫中的特定特徵以概括結果在機器學習模型中很常見,這會導致偏差。
結論
人工智慧已經接管了我們生活的許多方面。雖然不完美,但人工智慧是一個不斷發展的領域,需求量很大。在沒有人為幹預的情況下,它使用已經存在和處理過的數據提供即時結果。它通常透過開發數據驅動模型來幫助分析和評估大量數據。雖然人工智慧有很多問題,這是一個不斷發展的領域。從醫學診斷、疫苗研發到先進的交易演算法,人工智慧已成為科學進步的關鍵。
以上是阻礙人工智慧進步的八個問題的詳細內容。更多資訊請關注PHP中文網其他相關文章!