



儘管大型語言模型能力驚人,但由於規模較大,其部署所需的成本往往巨大。華盛頓大學聯合Google雲端運算人工智慧研究院、Google研究院針對此問題進行了進一步解決,提出了逐步蒸餾(Distilling Step-by-Step)範式幫助模型訓練。相對於LLM,這種方法對於訓練小型模型並應用於特定任務方面更有效,且所需的訓練資料比傳統的微調和蒸餾更少。在一個基準任務上,他們的 770M T5 模型勝過了 540B PaLM 模型。令人印象深刻的是,他們的模型只使用了可用數據的 80%。

#雖然大型語言模型(LLMs)展現了令人印象深刻的少樣本學習能力,但要將這樣大規模的模型部署在現實應用上是很難的。為 1750 億參數規模的 LLM 提供服務的專門基礎設施,至少需要 350GB 的 GPU 記憶體。更甚者,現今最先進的 LLM 是由超過 5,000 億的參數組成的,這意味著它需要更多的記憶體和運算資源。這樣的計算要求對於大多數生產商來說都是難以企及的,更何況是要求低延遲的應用了。
為了解決大型模型的這個問題,部署者往往會採用小一些的特定模型來取代。這些小一點的模型用常見範式 —— 微調或是蒸餾來進行訓練。微調使用下游的人類註釋資料升級一個預先訓練過的小模型。蒸餾用較大的 LLM 產生的標籤訓練同樣較小的模型。但很遺憾,這些範式在縮小模型規模的同時也付出了代價:為了達到與 LLM 相當的性能,微調需要昂貴的人類標籤,而蒸餾需要大量很難獲得的無標籤數據。
在一篇題為「Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes」的論文中,來自華盛頓大學、谷歌的研究者引入了一種新的簡單機制— 逐步蒸餾(Distilling step-bystep),用於使用更少的訓練資料來訓練較小的模型。這種機制減少了微調和蒸餾 LLM 所需的訓練資料量,使其有更小的模型規模。

#論文連結:https://arxiv.org/pdf/2305.02301 v1.pdf
該機制的核心是換一個角度,將LLM 看作是可以推理的agent,而不是雜訊標籤的來源。 LLM 可以產生自然語言的理由(rationale),這些理由可以用來解釋和支持模型所預測的標籤。例如,當被問及「一位先生攜帶著打高爾夫球的設備,他可能有什麼?(a) 球桿,(b) 禮堂,(c) 冥想中心,(d) 會議,(e) 教堂」 ,LLM 可以透過思考鏈(CoT)推理回答出「(a)球桿」,並透過說明「答案一定是用來打高爾夫球的東西」來合理化這個標籤。在上述選擇中,只有球桿是用來打高爾夫的。研究者使用這些理由作為額外更豐富的資訊在多任務訓練設定中訓練較小的模型,並進行標籤預測和理由預測。
如圖 1 所示,逐步蒸餾可以學習特定任務的小模型,這些模型的參數量還不到 LLM 的 1/500。與傳統的微調或蒸餾相比,逐步蒸餾使用的訓練範例也少得多。

#實驗結果顯示,在4 個NLP 基準中,有三個有希望的實驗結論。
- 第一,相對於微調和蒸餾,逐步蒸餾模型在各資料集上實現了更好的性能,平均減少了50% 以上的訓練實例(最多可減少85% 以上) 。
- 第二,我們的模型在模型尺寸較小的情況下表現優於LLM(最多可以小到2000 倍),大大降低了模型部署所需的計算成本。
- 第三,研究在縮減模型尺寸的同時,也減少了超越 LLM 所需的資料量。研究者使用 770M 的 T5 模型超越了 540B 參數的 LLM 的表現。這個較小的模型只使用了現有微調方法 80% 的標記資料集。
當只有未標記的資料時,小模型的表現相比LLM 而言仍然有過之而無不及—— 只用一個11B 的T5 模型就超過了540B 的PaLM 的性能。
該研究進一步表明,當一個較小的模型表現比LLM 差時,與標準的蒸餾方法相比,逐步蒸餾可以更有效地利用額外的無標籤資料來使較小的模型媲美LLM 的性能。
逐步蒸餾
研究者提出了逐步蒸餾這個新範式,是利用LLM 對其預測的推理能力,以數據高效率的方式訓練更小的模型。整體框架如圖 2 所示。
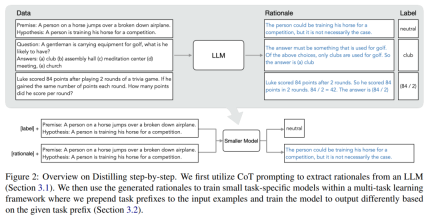
#這個範式有兩個簡單的步驟:首先,給定一個LLM 和一個無標籤的資料集,提示LLM 產生輸出標籤以及證明該標籤成立的理由。理由用自然語言解釋,為模型預測的標籤提供支持(見圖 2)。理由是當前自監督 LLM 的一個湧現的行為屬性。
然後,除了任務標籤之外,利用這些理由來訓練更小的下游模型。說白了,理由能提供了更豐富、更詳細的信息,來說明一個輸入為什麼被映射到一個特定的輸出標籤。
實驗結果
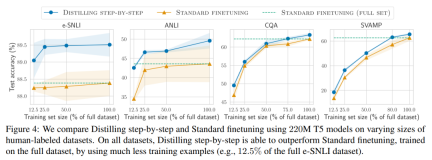
研究者在實驗中驗證了逐步蒸餾的有效性。首先,與標準的微調和任務蒸餾方法相比,逐步蒸餾有助於實現更好的效能,訓練實例的數量少得多,大幅提高了學習小型特定任務模型的資料效率。
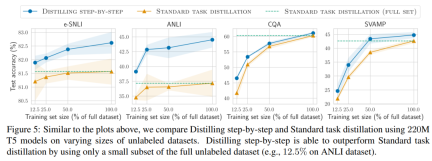
研究表明,逐步蒸餾方法以更小的模型大小超越了LLM 的性能,與llm 相比,大大降低了部署成本。
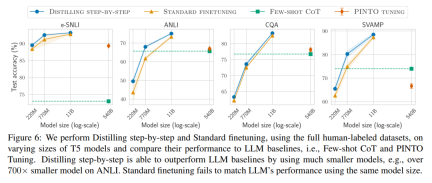
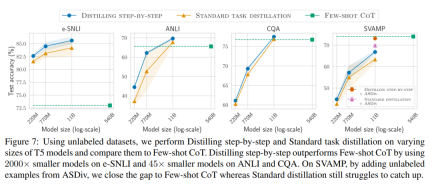
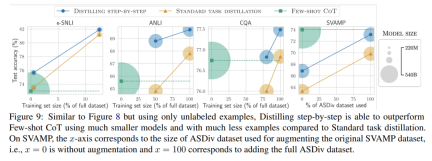
最後,研究者調查了逐步蒸餾方法在超過LLM 的性能方面所需的最低資源,包括訓練範例數量和模型大小。他們展示了逐步蒸餾方法透過使用更少的數據和更小的模型,同時提高了數據效率和部署效率。 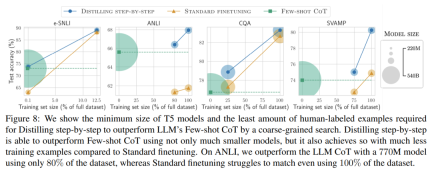
以上是蒸餾也能Step-by-Step:新方法讓小模型也能媲美2000倍體量大模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 AI太空公司誕生了May 12, 2025 am 11:07 AM
AI太空公司誕生了May 12, 2025 am 11:07 AM本文展示了AI如何以Tomorrow.io為典型的例子來徹底改變空間行業。 與像SpaceX這樣的建立太空公司不同,SpaceX並非沒有AI的核心,明天是AI本地公司。 讓我們探索
 印度的10個機器學習實習(2025)May 12, 2025 am 10:47 AM
印度的10個機器學習實習(2025)May 12, 2025 am 10:47 AM在印度(2025)登陸您夢想中的機器學習實習! 對於學生和早期職業專業人員來說,機器學習實習是一個有意義的職業的完美髮射台。 跨不同部門的印度公司 - 尖端的基因
 嘗試Fellou AI並向Google和Chatgpt說再見May 12, 2025 am 10:26 AM
嘗試Fellou AI並向Google和Chatgpt說再見May 12, 2025 am 10:26 AM在過去的一年中,在線瀏覽的景觀經歷了重大轉變。 這種轉變始於增強,個性化的搜索結果,例如困惑和副駕駛等平台,並隨著Chatgpt的整合而加速了
 個人黑客將是一隻非常兇猛的熊May 11, 2025 am 11:09 AM
個人黑客將是一隻非常兇猛的熊May 11, 2025 am 11:09 AM網絡攻擊正在發展。 通用網絡釣魚電子郵件的日子已經一去不復返了。 網絡犯罪的未來是超個性化的,利用了容易獲得的在線數據和AI來製作高度針對性的攻擊。 想像一個知道您的工作的騙子
 教皇獅子座XIV揭示了AI如何影響他的名字選擇May 11, 2025 am 11:07 AM
教皇獅子座XIV揭示了AI如何影響他的名字選擇May 11, 2025 am 11:07 AM新當選的教皇獅子座(Leo Xiv)在對紅衣主教學院的就職演講中,討論了他的同名人物教皇里奧XIII的影響,他的教皇(1878-1903)與汽車和汽車和汽車公司的黎明相吻合
 Fastapi -MCP初學者和專家教程-Analytics VidhyaMay 11, 2025 am 10:56 AM
Fastapi -MCP初學者和專家教程-Analytics VidhyaMay 11, 2025 am 10:56 AM本教程演示瞭如何使用模型上下文協議(MCP)和FastAPI將大型語言模型(LLM)與外部工具集成在一起。 我們將使用FastAPI構建一個簡單的Web應用程序,並將其轉換為MCP服務器,使您的L
 dia-1.6b tts:最佳文本到二元格生成模型 - 分析vidhyaMay 11, 2025 am 10:27 AM
dia-1.6b tts:最佳文本到二元格生成模型 - 分析vidhyaMay 11, 2025 am 10:27 AM探索DIA-1.6B:由兩個本科生開發的開創性的文本對語音模型,零資金! 這個16億個參數模型產生了非常現實的語音,包括諸如笑聲和打噴嚏之類的非語言提示。本文指南
 AI可以使指導比以往任何時候都更有意義May 10, 2025 am 11:17 AM
AI可以使指導比以往任何時候都更有意義May 10, 2025 am 11:17 AM我完全同意。 我的成功與導師的指導密不可分。 他們的見解,尤其是關於業務管理,構成了我的信念和實踐的基石。 這種經驗強調了我對導師的承諾


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

Atom編輯器mac版下載
最受歡迎的的開源編輯器

SublimeText3漢化版
中文版,非常好用

WebStorm Mac版
好用的JavaScript開發工具

Dreamweaver Mac版
視覺化網頁開發工具

