
大模型迎來「開源季」,盤點過去一個月那些開源的LLM和資料集

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-18 16:31:131879瀏覽
前段時間,Google洩露的內部文件表達了這樣一個觀點,雖然表面看起來OpenAI 和谷歌在AI 大模型上你追我趕,但真正的贏家未必會從這兩家中產生,因為有一個第三方力量正在悄悄崛起。這個力量就是「開源」。
圍繞Meta 的LLaMA 開源模型,整個社群正在迅速建立與OpenAI、Google大模型能力類似的模型,而且開源模型的迭代速度更快,可自訂性更強,更有私密性。
近日,前威斯康辛大學麥迪遜分校助理教授、新創公司Lightning AI 首席AI 教育官Sebastian Raschka 表示,對於開源而言,過去一個月很偉大。
不過,那麼多大語言模型(LLM)紛紛出現,要緊緊把握住所有模型並不容易。所以,Sebastian 在本文中分享了關於最新開源 LLM 和資料集的資源和研究洞見。
論文與趨勢
過去一個月出現了許多研究論文,因此很難從中挑選出最中意的幾篇進行深入的探討。 Sebastian 更喜歡提供額外洞見而非簡單展示更強大模型的論文。有鑑於此,引起他注意力的首先是 Eleuther AI 和耶魯大學等機構研究者共同撰寫的 Pythia 論文。

論文網址:https://arxiv.org/pdf/2304.01373.pdf
#Pythia:從大規模訓練中得到洞見
#開源Pythia 系列大模型真的是其他自回歸解碼器風格模型(即類GPT 模型)的有趣平替。論文中揭示了關於訓練機制的一些有趣洞見,並介紹了從 70M 到 12B 參數不等的相應模型。
Pythia 模型架構與 GPT-3 相似,但包含一些改進,例如 Flash 注意力(像 LLaMA)和旋轉位置嵌入(像 PaLM)。同時 Pythia 在 800GB 的多樣化文字資料集 Pile 上接受了 300B token 的訓練(其中在常規 Pile 上訓練 1 個 epoch,在去重 Pile 上訓練 1.5 個 epoch )。
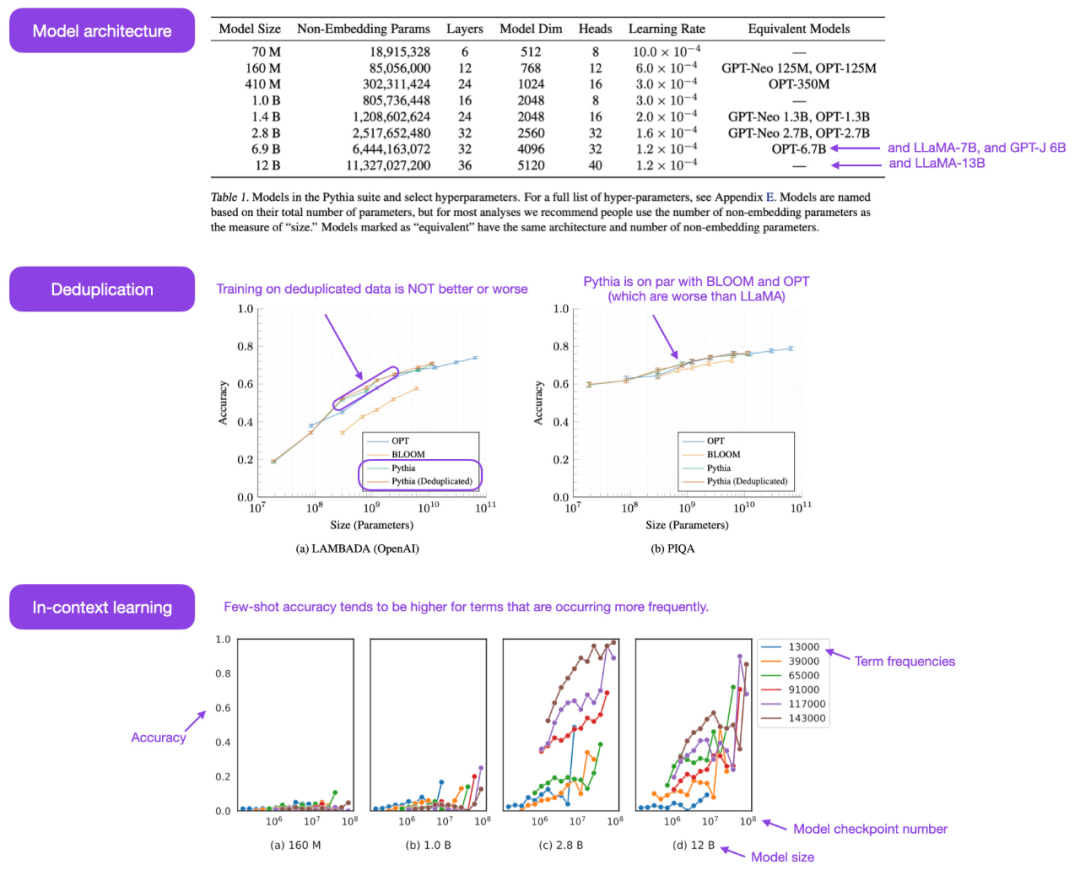
下面為一些從Pythia 論文中得到的洞見與思考:
- ##在重複資料上的訓練(即訓練epoch>1)會不會有什麼影響?結果表明,資料去重不會改善或損害表現;
- 訓練指令會影響記憶嗎?遺憾的是,結果顯示並不會。之所以說遺憾,是因為如果影響的話,則可以透過訓練資料的重新排序來減輕討厭的逐字記憶問題;
- batch 大小加倍可以將訓練時間減半但不損害收斂。
開源資料
#對於開源AI,過去一個月特別令人興奮,出現了幾個LLM 的開源實作和一大波開源資料集。這些資料集包括 Databricks Dolly 15k、用於指令微調的 OpenAssistant Conversations (OASST1)、用於預訓練的 RedPajama。這些資料集工作尤其值得稱讚,因為資料收集和清理佔了真實世界機器學習專案的 90%,但很少有人喜歡這項工作。
Databricks-Dolly-15 資料集
#Databricks-Dolly-15 是一個用於LLM 微調的數據集,它由數千名DataBricks 員工編寫了超過15,000 個指令對(與訓練InstructGPT 和ChatGPT 等系統類似)。
OASST1 資料集
OASST1 資料集用於在由人類創建和標註的類別ChatGPT 助手的對話集合上微調預訓練LLM ,包含了35 種語言編寫的161,443 則訊息以及461,292 個品質評估。這些是在超過 10,000 個完全標註的對話樹中組織起來。
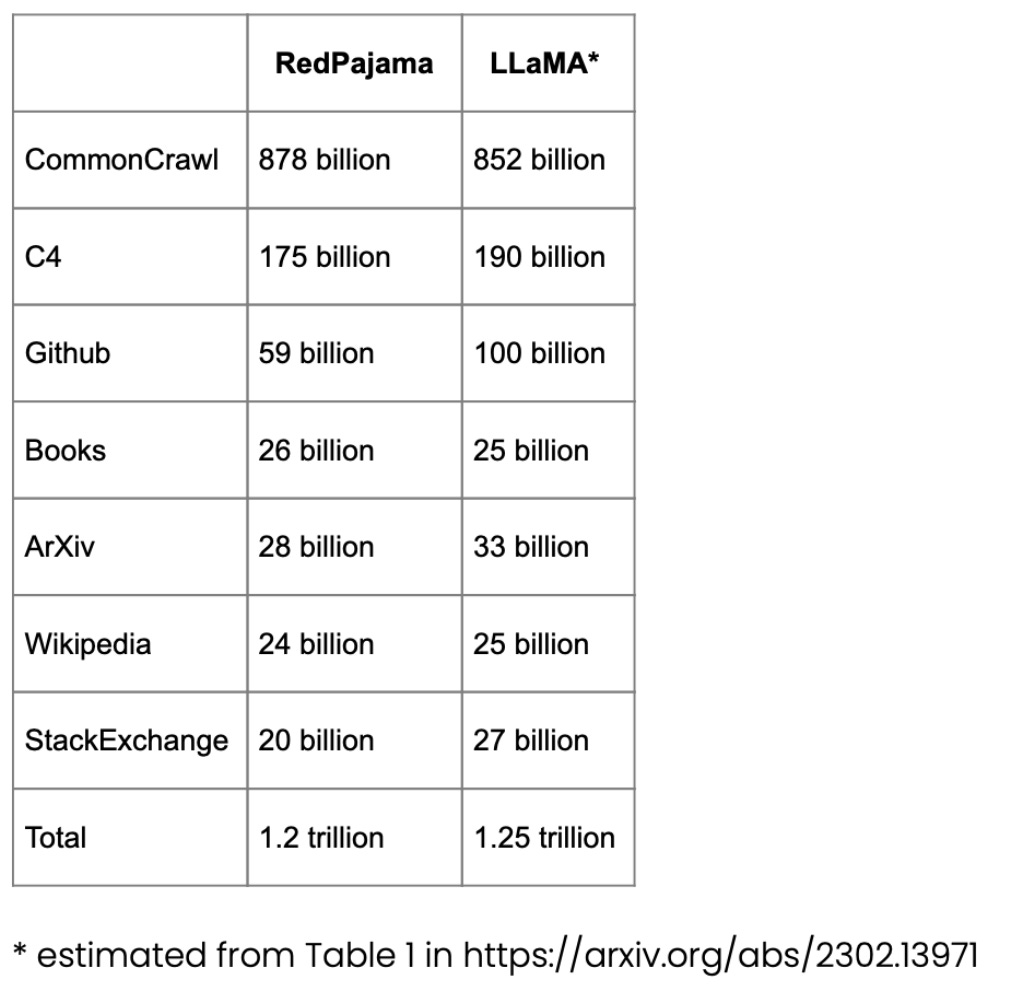
用於預訓練的RedPajama 資料集

RedPajama 是一個用於LLM 預訓練的開源資料集,類似於Meta 的SOTA LLaMA 模型。該資料集旨在創建一個媲美大多數流行 LLM 的開源競爭者,目前這些 LLM 要么是閉源商業模型要么僅部分開源。
RedPajama 的大部分由 CommonCrawl 組成,它對英文網站進行了過濾,但維基百科的文章涵蓋了 20 種不同的語言。
LongForm 資料集
論文《 The LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction》介紹了基於C4 和Wikipedia 等已有語料庫的人工創作文檔集合以及這些文檔的指令,從而創建了一個適合長文本生成的指令調優資料集。
論文網址:https://arxiv.org/abs/2304.08460
##Alpaca Libre 項目
Alpaca Libre 專案旨在透過將來自Anthropics HH-RLHF 儲存庫的100k 個MIT 授權演示轉換為Alpaca 相容格式,以重現Alpaca 專案。
擴展開源資料集
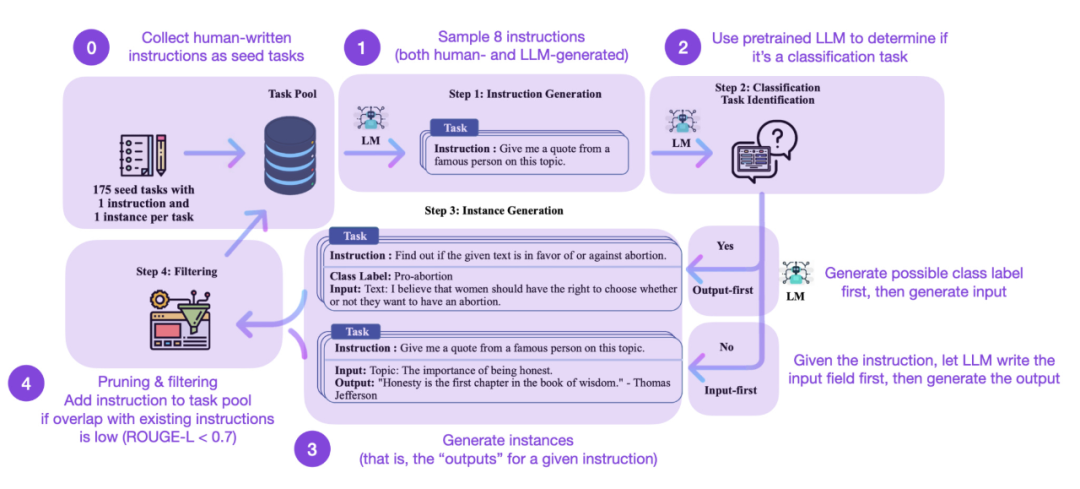
#指令微調是我們從類別GPT-3 預訓練基礎模型演化到更強大類ChatGPT 大語言模型的關鍵方式。 Databricks-Dolly-15 等開源人工生成指令資料集有助於實現這一點。但我們要如何進一步擴展呢?是否可以不收集額外數據呢?一種方法是從自身的迭代中bootstrap 一個 LLM。雖然 Self-Instruct 方法在 5 個月前提出(以如今標準來看過時了),但它仍然是一種非常有趣的方法。值得強調的是,由於 Self-Instruct 一種幾乎不需要註解的方法,因而可以將預訓練 LLM 與指令對齊。
如何運作呢?簡而言之可以分為以下四個步驟:
- 首先是具有一組手動編寫指令(本例中為175)和樣本指令的種子任務池;
- 其次使用一個預訓練LLM(如GPT-3)來決定任務類別;
- 接著給定新指令,使預訓練LLM 產生回應;
- 最後在將指令新增至任務池之前收集、修剪和過濾回應。
在實務中,基於ROUGE 分數的工作會比較有效、例如Self-Instruct 微調的LLM 優於GPT-3 基礎LLM,並且可以在大型人工編寫指令集上預先訓練的LLM 競賽。同時 self-instruct 也能使在人工指令上微調過的 LLM 效益。
但當然,評估 LLM 的黃金標準是詢問人類評分員。基於人類評估,Self-Instruct 優於基礎 LLM、以及以監督方式在人類指令資料集上訓練的 LLM(例如 SuperNI, T0 Trainer)。不過有趣的是,Self-Instruct 的表現並不優於透過人類回饋強化學習(RLHF)訓練的方法。
人工生成vs 合成訓練資料集
#人工生成指令資料集和self-instruct 資料集,它們兩個哪個更有前途呢? Sebastian 認為兩者皆有前途。為什麼不從人工生成指令資料集(例如 15k 指令的 databricks-dolly-15k)開始,然後使用 self-instruct 對它進行擴展呢?論文《Synthetic Data from Diffusion Models Improves ImageNet Classification》表明,真實影像訓練集與 AI 生成影像結合可以提升模型效能。探究對於文字資料是否也是一件有趣的事。
論文網址:https://arxiv.org/abs/2304.08466
最近的論文《Better Language Models of Code through Self-Improvement》就是關於這一方向的研究。研究者發現如果一個預先訓練 LLM 使用它自己產生的數據,則可以改進程式碼產生任務。
論文網址:https://arxiv.org/abs/2304.01228
少即是多(Less is more)?
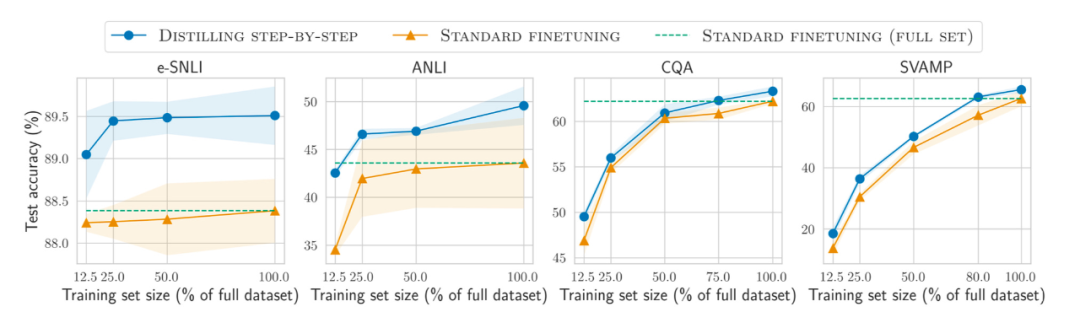
此外,除了在越來越大的資料集上預訓練和微調模型之外,又如何提高在更小資料集上的效率呢?論文《Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes》中提出使用一種蒸餾機制來管理任務特定的更小模型,它們使用更少的訓練數據卻超越了標準微調的性能。
論文網址:https://arxiv.org/abs/2305.02301
追蹤開源LLM
開源LLM 的數量呈現爆炸性成長,一方面是非常好的發展趨勢(相較於透過付費API 控制模型),但另一方面追蹤這一切可能很麻煩。以下四種資源提供了大多數相關模型的不同摘要,包括它們的關係、底層資料集和各種授權資訊。
第一種資源是基於論文《Ecosystem Graphs: The Social Footprint of Foundation Models》的生態系統圖網站,提供以下表格和互動式依賴圖(這裡未展示)。
這個生態系統圖是 Sebastian 迄今為止見過的最全面的列表,但由於包含了許多不太流行的 LLM,因而可能顯得有點混亂。檢查相應的 GitHub 庫發現,它已經更新了至少一個月。此外尚不清楚它會不會添加更新的模型。
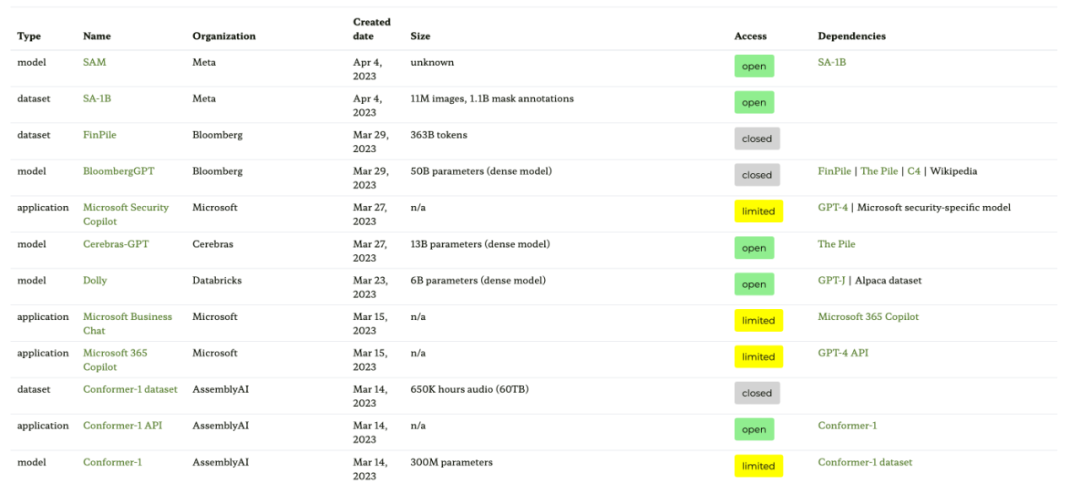
- #論文網址:https://arxiv.org/abs/2303.15772
- 生態系圖網址:https://crfm.stanford.edu/ecosystem-graphs/index.html?mode=table
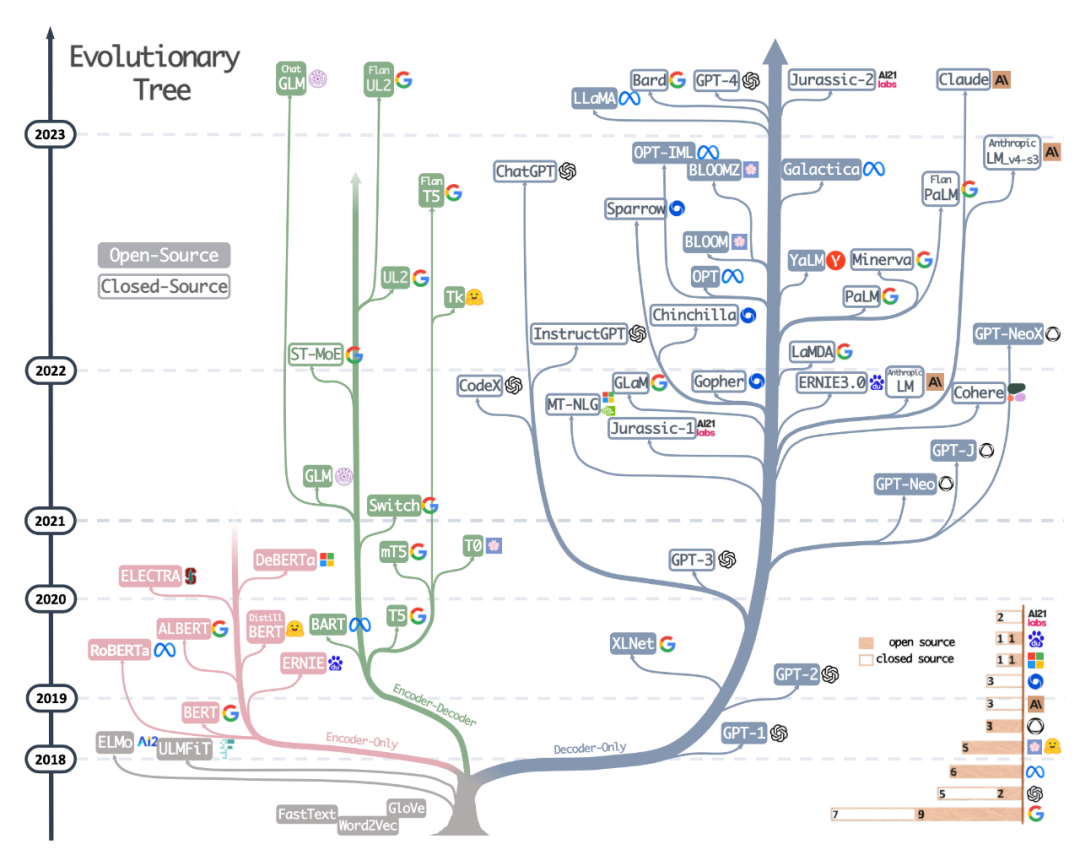
第二種資源是最近論文《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》中繪製精美的進化樹,該論文側重於最流行的LLM 和它們的關係。
雖然讀者看到了非常美觀和清晰的視覺化 LLM 演化樹,但也有一些小小的疑惑。例如不清楚為什麼底部沒有從原始 transformer 架構開始。此外開源標籤並不是非常的準確,例如 LLaMA 被列為開源,但權重在開源許可下不可用(只有推理代碼是這樣的)。
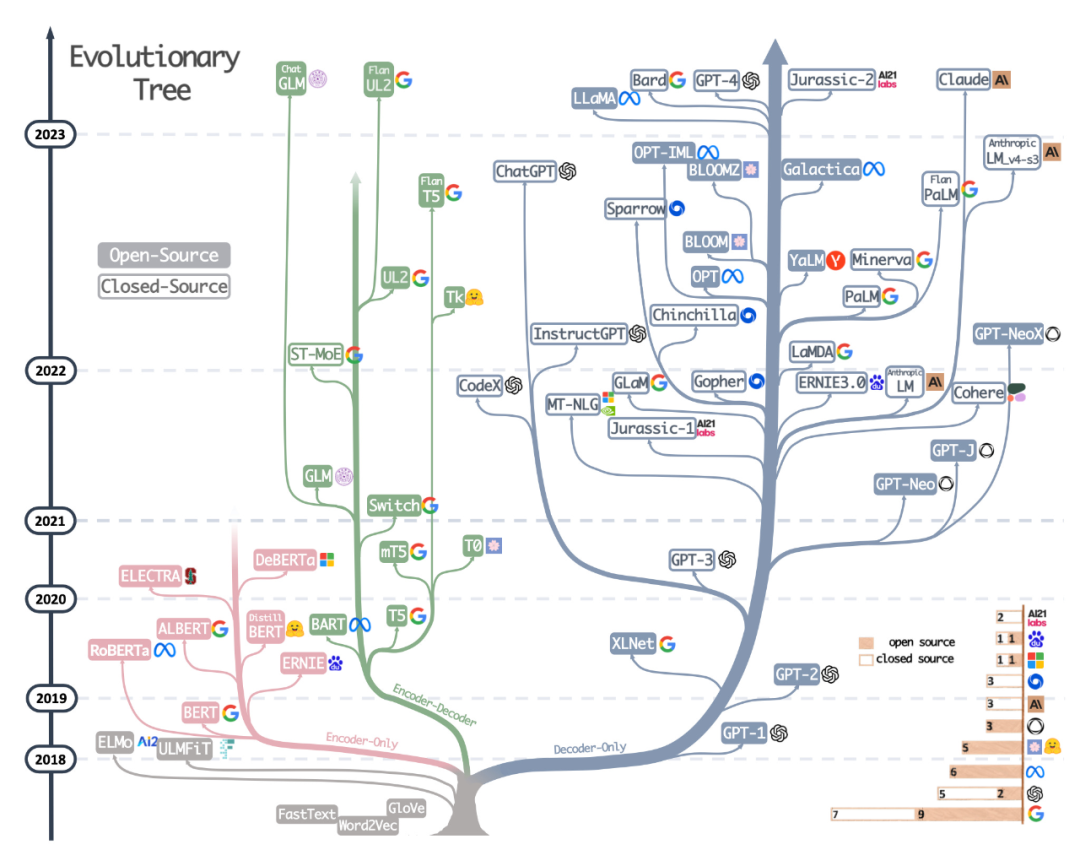
論文網址:https://arxiv.org/abs/2304.13712
#第三種資源是 Sebastian 同事 Daniela Dapena 繪製的表格,出自部落格《The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs …》。
雖然下述表格比其他資源小,但其優點在於包含了模型尺寸和授權資訊。如果你打算在任何專案中採用這些模型,則該表格會非常有實用性。
#部落格網址:https://lightning.ai/pages/community/community-discussions/the-ultimate-battle-of -language-models-lit-llama-vs-gpt3.5-vs-bloom-vs/
第四種資源是LLaMA-Cult-and-More 總覽表,它提供了有關微調方法和硬體成本的額外資訊。
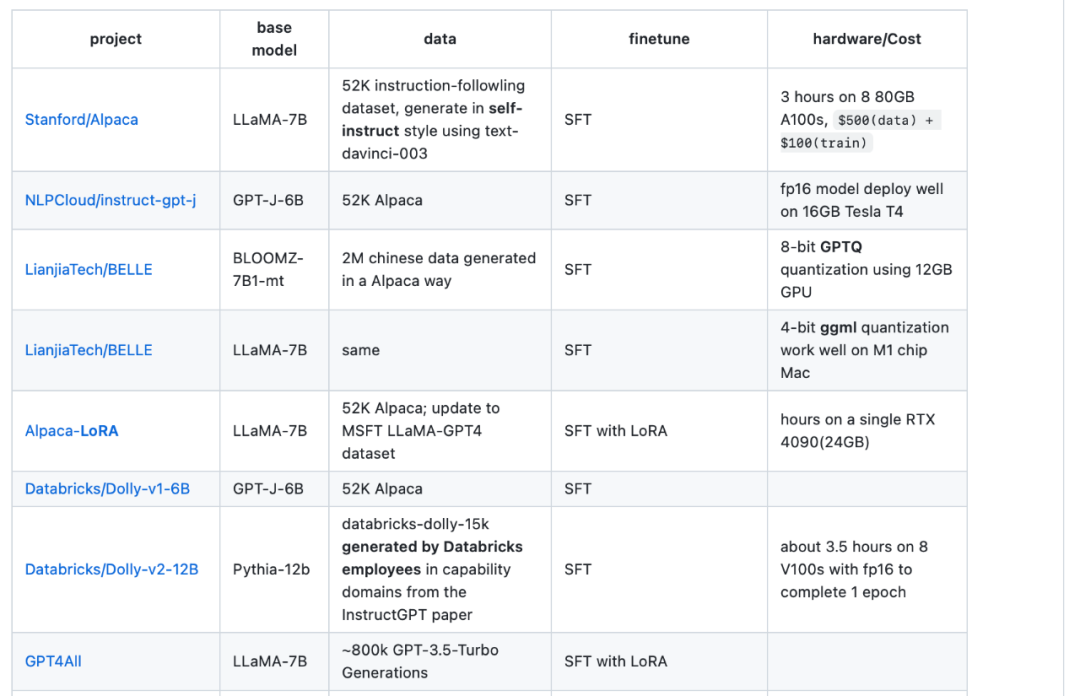
總覽表網址:https://github.com/shm007g/LLaMA-Cult-and- More/blob/main/chart.md
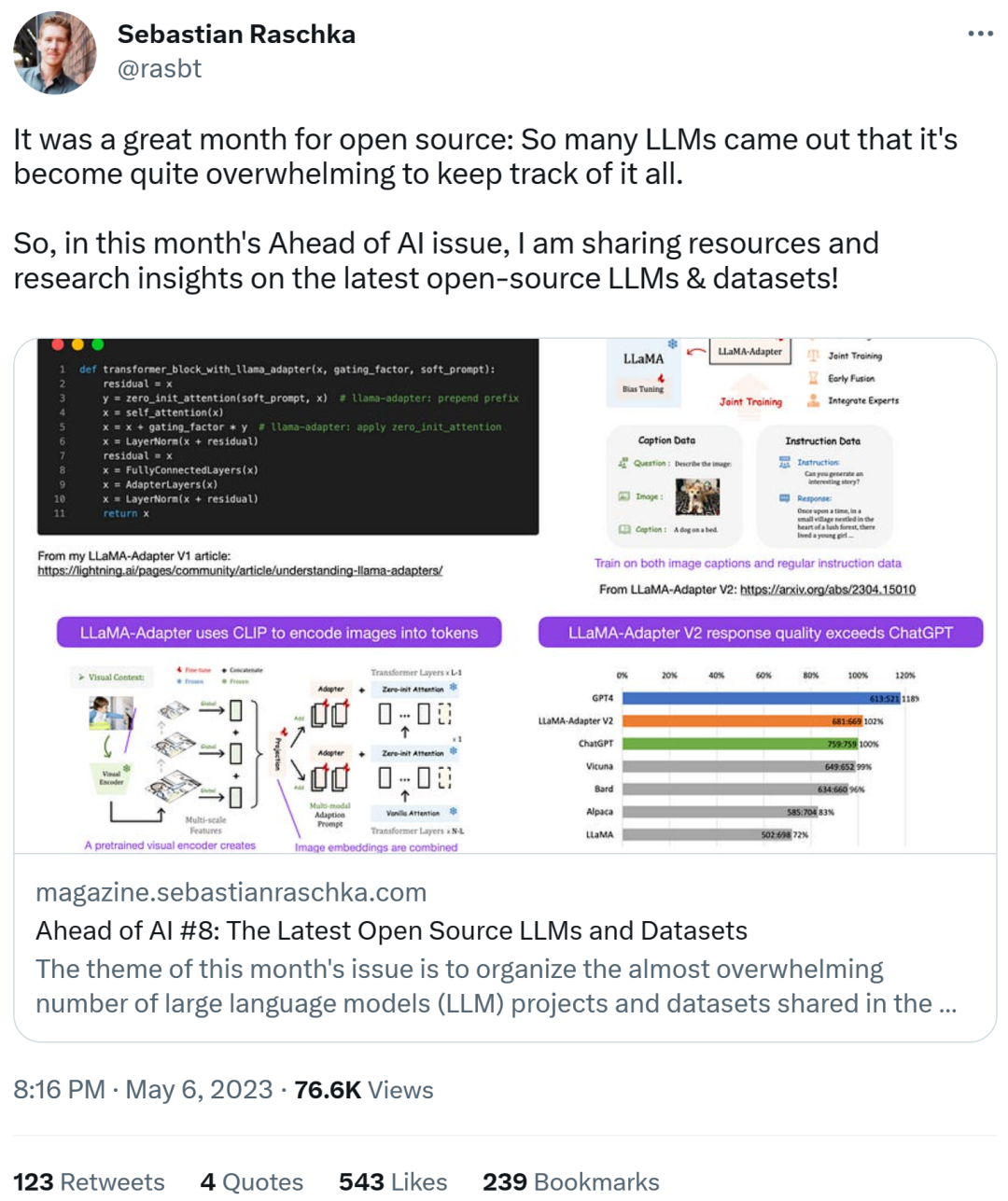
利用LLaMA-Adapter V2 微調多模態LLM
Sebastian 預測本月會看到更多的多模態LLM 模型,因此不得不談到不久前發布的論文《LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model》。先來回顧一下什麼是 LLaMA-Adapter?它是一種參數高效的 LLM 微調技術,修改了前面幾個 transformer 區塊並引入一種門控機制來穩定訓練。
論文網址:https://arxiv.org/abs/2304.15010
##使用LLaMA-Adapter 方法,研究人員能夠在52k 個指令對上僅用1 小時(8 塊A100 GPU)來微調一個7B 參數的LLaMA 模型。雖然僅對新添加的 1.2M 參數(adapter 層)進行了微調,但 7B LLaMA 模型仍處於凍結(frozen)狀態。
LLaMA-Adapter V2 的重點在多模態,即建構一個可以接收影像輸入的視覺指令模型。最初的 V1 雖然可以接收文字 token 和圖像 token,但在圖像方面沒有充分探索。
LLaMA-Adapter 從 V1 到 V2,研究人員透過以下三個主要技巧來改進 adapter 方法。
- 早期視覺知識融合:不再在每個adapted 層融合視覺和adapted 提示,而是在第一個transformer 區塊中將視覺token 與單字token 連接起來;
- 使用更多參數:解凍(unfreeze)所有歸一化層,並將偏移單元和縮放因子添加到transformer 區塊中每個線性層;
- 具有不相交參數的聯合訓練:對於圖文字幕數據,僅訓練視覺投影層;針對指令遵循的數據僅訓練adaption 層(以及上述新添加的參數)。
LLaMA V2(14M)比LLaMA V1 (1.2 M) 的參數多了很多,但它仍是輕量級,僅佔65B LLaMA 總參數的0.02% 。特別令人印象深刻的是,僅對 65B LLaMA 模型的 14M 參數進行微調,所得的 LLaMA-Adapter V2 在性能上媲美 ChatGPT(當使用 GPT-4 模型進行評估)。 LLaMA-Adapter V2 也優於使用全微調方法的 13B Vicuna 模型。
遺憾的是,LLaMA-Adapter V2 論文省略了 V1 論文中包含的計算效能基準,但我們可以假設 V2 仍然比全微調方法快得多。

其他開源 LLM
大模型的發展速度奇快,我們無法一一列舉,本月推出的一些著名的開源 LLM 和聊天機器人包括 Open-Assistant、Baize、StableVicuna、ColossalChat、Mosaic 的 MPT 等。此外,以下是兩個特別有趣的多模態 LLM。
OpenFlamingo
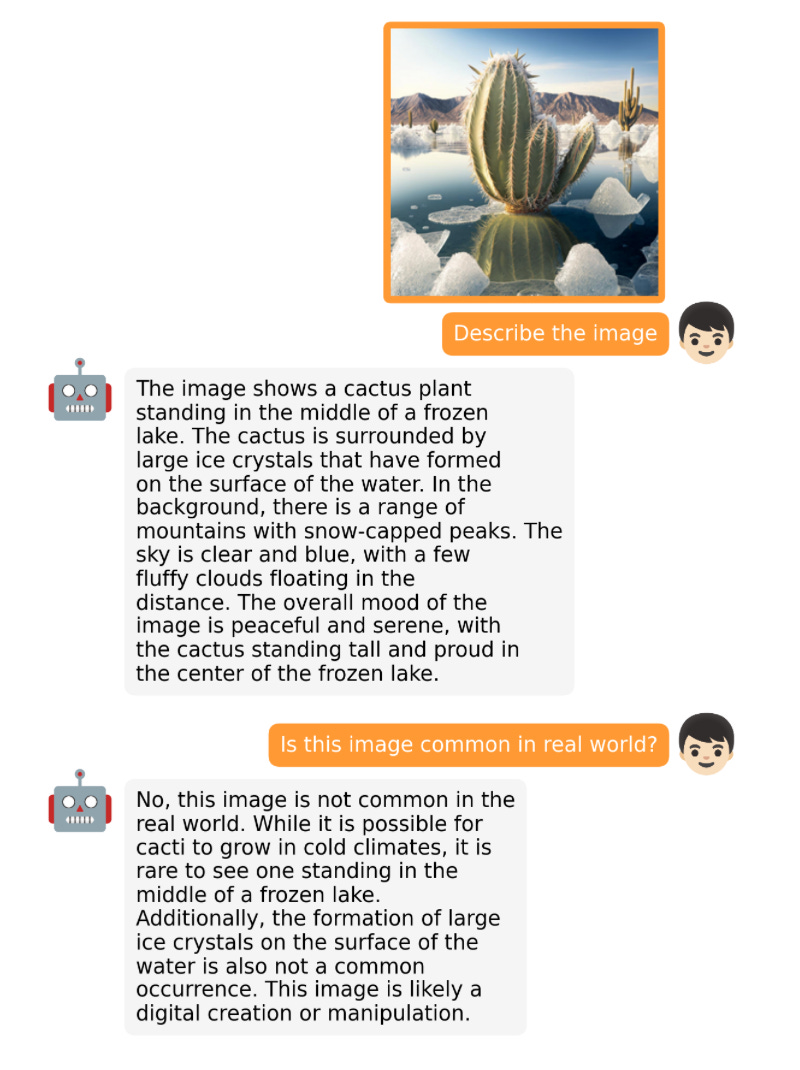
#OpenFlamingo 是 Google DeepMind 去年發布的 Flamingo 模型的開源複製版。 OpenFlamingo 旨在為 LLM 提供多模式圖像推理功能,讓人們能夠交錯輸入文字和圖像。
MiniGPT-4
#MiniGPT-4 是另一個具有視覺語言功能的開源模型。它基於 BLIP-27 的凍結視覺編碼器和凍結的 Vicuna LLM。
#NeMo Guardrails
隨著這些大語言模型的出現,許多公司都在思考如何以及是否應該部署它們,安全方面的擔憂尤其突出。目前還沒有好的解決方案,但至少有一個更有前景的方法:英偉達開源了一個工具包來解決 LLM 的幻覺問題。
簡而言之,它的工作原理是此方法使用資料庫連結到硬編碼的 prompt,這些 prompt 必須手動管理。然後,如果使用者輸入 prompt,內容將首先與該資料庫中最相似的條目相符。然後資料庫傳回一個硬編碼的 prompt,然後傳遞給 LLM。因此,如果有人仔細測試硬編碼 prompt,就可以確保互動不會偏離允許的主題等。
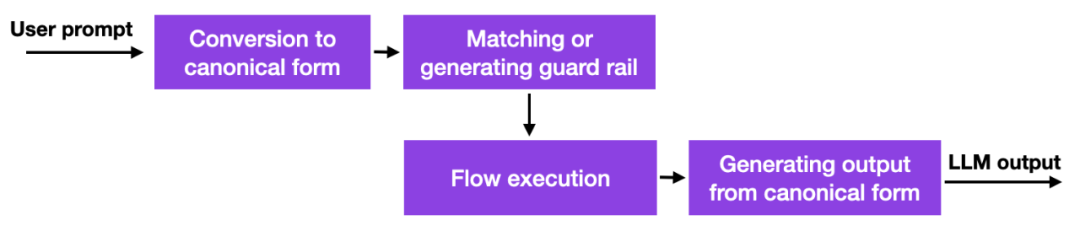
這是一種有趣但不是開創性的方法,因為它沒有為LLM 提供更好的或新的能力,它只是限制了使用者可以與LLM 互動的程度。儘管如此,在研究人員找到減輕 LLM 中的幻覺問題和負面行為的替代方法之前,這可能是一種可行的方法。
guardrails 方法也可以與其他對齊技術結合,例如作者在上一期 Ahead of AI 中介紹的流行的人類回饋強化學習訓練範例。
一致性模型
#談論LLM 以外的有趣模型是一個不錯的嘗試,OpenAI 終於開源了他們一致性模型的程式碼:https://github.com/openai/consistency_models。
一致性模型被認為是擴散模型的可行、有效的替代方案。你可以在一致性模型的論文中獲得更多資訊。
以上是大模型迎來「開源季」,盤點過去一個月那些開源的LLM和資料集的詳細內容。更多資訊請關注PHP中文網其他相關文章!