
因果推薦技術在行銷和可解釋性上的應用

- PHPz轉載
- 2023-05-18 13:58:061767瀏覽

一、Uplifit 增益敏感度預測
關於Uplift 增益,通用的業務問題可以總結為,在圈定的人群中,行銷人員會想知道,新的行銷動作T=1 相比較原始的行銷動作T=0,能帶來多少的平均收益(lift,ATE,Average Treatment Effect)。大家會關注新的行銷動作是否比原來的更有效。
在保險場景下,行銷動作主要指的是保險的推薦,例如推薦模組上透出的文案和產品,目標是在各種行銷在動作和約束條件限制下,找出因行銷動作而增益最多的群體,去做定向投放(Audience Targeting)。

#先做一個比較理想且完美的假設:對於每一個使用者i ,都能知道他對行銷動作t 是不是買單。如果買賬,可以認為公式中的 Di 為正,且 value 比較大;如果不買賬,且對行銷動作很反感,Di 可能就會比較小,甚至是負向的。這樣就能夠得到每個使用者個體對於 treatment 的效果。
關於人群劃分,可以看到上圖中的行銷四象限,我們最關注的肯定是左上角 Persuadables 的人群。結合公式,該人群的特徵是當有一些行銷動作的時候,會很買賬,也就是 Yi > 0 ,且值比較大。如果對該人群不去做行銷動作則是負的,或者是比較小,等於 0,這樣的人群的 Di 就比較大。
再看另外兩個像限的人,Sure things,指無論是否行銷,這些人都會買,那麼行銷投到這一人群上的收益率是比較低的。 Sleeping dogs,是指去做行銷反而會起到一些負面作用。這兩部分群體最好不要進行行銷投放。

#但這裡也存在著反事實的兩難:Di 沒有那麼完美。我們不可能同時知道一個使用者對 treatment 是否感興趣,即無法知道同一使用者在同一時間對不同 treatment 下的反應。
最通俗的例子是:假設有一個藥物,給 A 吃了之後,會得到 A 對藥物的反應。但卻不知道,如果 A 不吃的結果,因為 A 已經將藥吃下去了,這其實就是一個反事實的存在。
對於反事實,我們進行了近似的預估。 ITE(Individual Treatment Effect )預估的方式,雖然找不到一個用戶,實驗其對兩個treatment 的反應,但可以找到相同特徵的用戶群來預估反應,比如具有相同Xi 的兩個人,可以假設在同一特徵空間下,近似等同為一個人。

#這樣,Di 的預估分成了三個區塊:(1) Xi 在T=1 的行銷動作下的轉換率;(2)Xi 在T=0 的行銷動作下的轉換率;(3)lift 是一個差值,計算兩個條件機率下的差異。使用者群體的 lift 值越高,表示該族群更買單。如何讓 lift 更高呢?在公式中,是將 Xi 在 T=1 的行銷動作下的轉換率變大,Xi 在 T=0 的行銷動作下的轉換率越小即可。

在建模方式上,結合上文的公式,做一些歸納:
(1)T 變數的數量,如果不只是一個行銷動作,而是有n 個行銷動作,則為多變量Uplift 建模,否則是單變數Uplift 建模。
(2)條件機率P 以及lift 的預估方式:① 透過差分建模,預估P 值,然後找到lift 值,這是間接的建模。 ② 透過直接建模,例如標籤轉換模型,或因果森林,如 Tree base 、LR、 GBDT 或一些深度模型。
二、增益敏感度的應用

面的應用:保險產品的推薦,紅包推薦,以及文案的推薦。 首先來介紹一下,旅遊保險在飛豬上是什麼樣的定位。旅遊保險是旅行商品中的一個種類,但它更多的是出現在主營商品的搭售鏈路上。例如我們去訂機票、飯店的時候,主要購買意圖是:飯店、機票、火車票,這時候 APP 會問你要不要買保險。所以保險是屬於一個輔營業務,但是其目前已成為交通和住宿行業一個非常重要的商業性收入來源。
本文講的主要作用域在彈窗頁:彈窗頁是飛豬APP 下拉收銀台的時候會彈出的一個頁面,這個頁面只會展示一種創意文案,只能展示一種保險商品,這一點與前面詳情頁可以展示多個類型的商品,以及保險的價格不同。所以這個頁面,會讓用戶的注意力足夠的聚焦在這裡,並且可以做一些拉新促活,甚至是一些用戶教育培養的營銷動作。

#目前遇到的業務問題是:在彈窗頁面,我們需要推薦一個最佳的保險產品或紅包,使得整體的轉化或收益最大化。更具體的是去做一個拉新,或是更高轉換的業務目標。而業務收益目標是在收益不降低的情況下,提高轉換率。
在以上的限制條件下,有幾個行銷項目:(1)給用戶推薦一個入門級低價保險;(2)另外一個treatment ,推薦一些紅包,主要是去做一些拉新的操作。而 Base 就是原價的保險。
#建模的時候,有一些假設的條件:條件獨立的假設。指 treatment 行銷動作,在建模 uplift 採集的時候,樣本服從假設條件獨立,使用者的各個特徵是相互獨立的。例如發紅包,不能在年齡上有不同的分佈,例如,在年輕人上少一點,老年人上發的多一點。這個會導致樣本有偏。所以提出的解法是讓使用者隨機地去曝光商品。同樣的,也可以計算傾向性得分,得到同質的用戶群,去做對比。
############在實驗設計######上,AB 實驗:A 是用原來的策略去投放,可能是40 塊的保險,也可能是營運來進行保險的定價,或是原始模型的一個定價。 B 桶,低價保險投放。 ###### #####################Label :###使用者是否轉換成交。 ##########模型:T/S/X-learner 以及各類別的這種 Meta 模型。
樣本建構:#訴求是要刻畫使用者到底對這種低價保險是否更感興趣,就需要有足夠的特徵去刻畫使用者對價格的敏感度。但實際上像輔營產品,沒有一個比較強的意圖性。所以我們很難從用戶的歷史瀏覽購買記錄當中,看到用戶到底喜歡多少塊的保險,或者是他會購買多少錢的保險。我們只能從主營或使用者串流瀏覽的一些其他的飛豬APP 網域內的資料去看,也會看使用者紅包的使用頻率和紅包消費比例,例如使用者會不會只有在發紅包的前幾天,才在飛豬上進行轉化。

#基於以上的特徵樣本的構造,同樣進行特徵重要性和可解釋性的分析。透過 Tree base 模型可以看到,在一些時間、價格變數、年齡變數特徵上是比較敏感的。
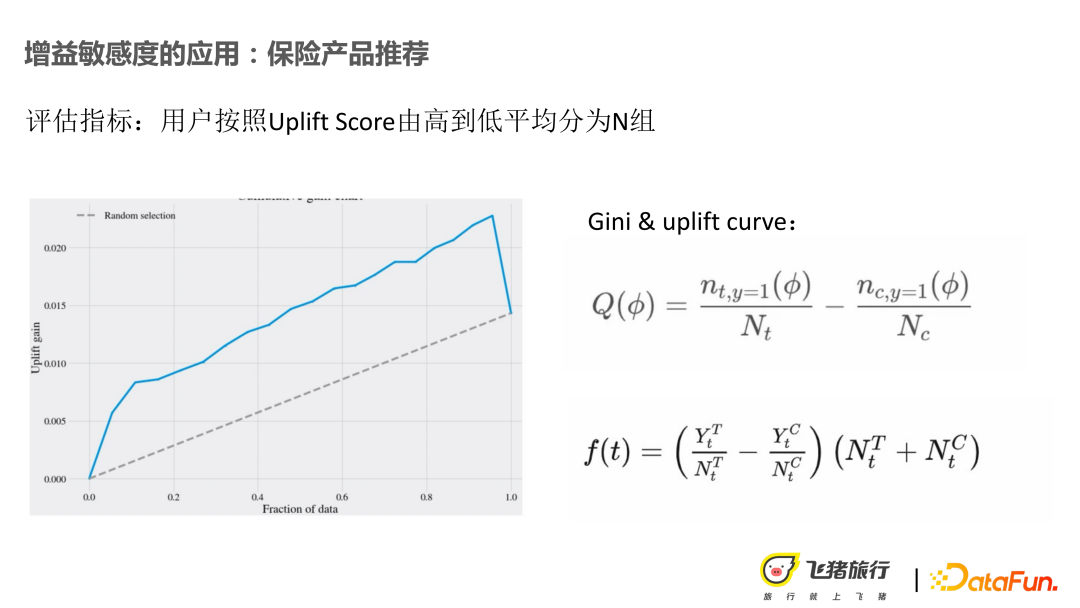
評估指標的計算方式:Gini 和 Accumulated Gini。將 Uplift 分成 n 組,每一組去計算一個 Gini 分,如上圖第一個公式所示,在該分組下得到用戶映射到 test 桶和 base 桶之後的轉換率,再去算 Gini。同理類推到 Uplift Gini,透過計算不同的門檻下的收益分,輔助我們去做閾值的一個判定。

透過離線可得,表現最好的模型是LR T-Learner,其實不太符合原始的預期。後來思考了這個問題,也許問題出在使用者對保險相關的價格特徵的建構上,並不太足夠去刻畫。因為我們也去做了一些用戶調查,例如用戶的性格,對保險的敏感程度,這種 APP 域內的一些用戶畫像數據,能看到用戶對一個無實體商品的感興趣程度。但最終,還是基於這樣的分數,去劃定人群做投放,線上的 base 桶相對提升 5.8%。

#在紅包推薦上,我們也可以在40 元的保險的base上,發一個3/5/8/10 塊的保險。

#我們有一個業務目標就是增量ROI,公式定義是:test 桶的GMV 減去base 桶的GMV,得到的增量GMV,能不能cover 掉在test 桶的行銷費用。如果增量 ROI 大於1,就表示行銷是不虧的。所以在該場景下,我們的要求是不虧。在我們在用 Uplift 模型之前,營運同學會先去做一波投放,在他們的種子人群上,ROI 在 0.12-0.6 之間,所以對我們的一個要求就是要比這個 ROI 高,且不虧本。
透過上述目標的拆解,問題最後又轉化為使用者的轉換率的預估以及 Uplift 預估,如上圖下面的公式所示。

最後經過一系列的變化,實際上又回到了去求解 Uplift 值以及未購買機率。未購機率是指用戶在不發券時候的轉換率,如果想讓剛剛提到的 ROI 越高,就代表需要找到一個用戶群,P0 越小越好,且 Uplift 值越高越好。
第一版模型是半智能的決策模型:根據在不同券額下計算得到的Uplift 值,再透過觀察treatment 上線之後的效果,卡定閾值,每個卡定的閾值是為了能夠cover 掉成本。

#第二版是智慧定價模型:借鑒了對偶問題的求解,限制條件是發券要小於等於1 即Xij

#使用定價模型相比原來營運桶的紅包投放,增量ROI 能達到1.2。

在文案的推薦上,跟之前的產品推薦和紅包推薦有相似的思路。我們會發現一些用戶對不同風格的文案有不同的偏好,所以將其結構化出來,比如溫馨類的“帶份平安保障”,或者一些提示風險。也會發現,在不同細分人群上,存在著比較大的明顯的差異,從特徵重要性來看,溫馨的語句,可能對80 後或者是一些年紀偏長的人有效,而偏理由性質的文案,對年輕人會比較適用。從細分人群的特徵重要性上,同時也做文案的個人化嘗試,有 5%~10% 的相對提升。
三、貝葉斯因果網絡

貝葉斯因果網絡主要是表徵事務間因果關係,有向五環圖的結構。先簡單介紹為什麼要使用貝葉斯網路。在不同的推薦文案下,我們想知道用戶為什麼對文案感興趣,或者說為什麼能轉化,背後到底有哪些隱藏的變數。所以做可解釋性網路的構建,頂點主要是觀測變量,或隱含變數;邊是指兩個頂點之間存在的因果關聯,關聯可以透過節點之間的條件機率去計算。在貝葉斯網路當中,經過每個頂點,在所有父節點條件之下的機率值相乘,得到最終的網路結構。

#在網路結構中有4 個類別模型學習的問題:
① 結構學習:基於樣本,怎樣才能學習一個比較優的貝葉斯網絡,主要是基於後驗,如上圖公式,如果structure 的概率值越高,則認為網絡學的最優。
② 得到結構之後,怎麼知道網路裡節點上的條件機率值,以及它的參數。
③ 推論:當事件 A 發生的時候,事件 B 發生對機率。
④ 歸因:當事件 A 發生的時候,導致 A 發生的原因有哪些。
四、畫像決策路徑建構及可解釋性應用

#上文中提到,保險推薦場景與搜尋推薦不太一樣,保險推薦是個輔營業務,用戶不帶有主觀,也就是在來到這個模組之前,他在APP 域內的瀏覽記錄,跟用戶對什麼樣的保險或文案感興趣,沒有同質的關聯性。而在搜尋中,輸入親子飯店,就知道使用者對親子標籤的飯店有需求。在輔營場景,需要複雜的推理過程,才能知道什麼樣的 Treatment 動作是有效的。舉個例子,透過網路挖掘會發現,在天氣惡劣的情況下,可能延誤險的銷售量會比較好。

#如何建模,把網路裡的節點和邊建構成如下的幾種:
① 使用者節點#,將年齡、性別這種使用者畫像的基礎資訊作為離散變量,成為一個節點。
② 事件節點#,因為保險場景對事件的敏感度要高於許多其他的商品推薦,例如在天氣或節日下,使用者可能會對延誤保險,或是某些有特定屬性的保險比較敏感。
③ 創意節點#,例如溫馨類別引導性文案、動態數字文案等都會有不同的效果。
基於以上三大類節點,做條件機率計算,完成圖的建構。
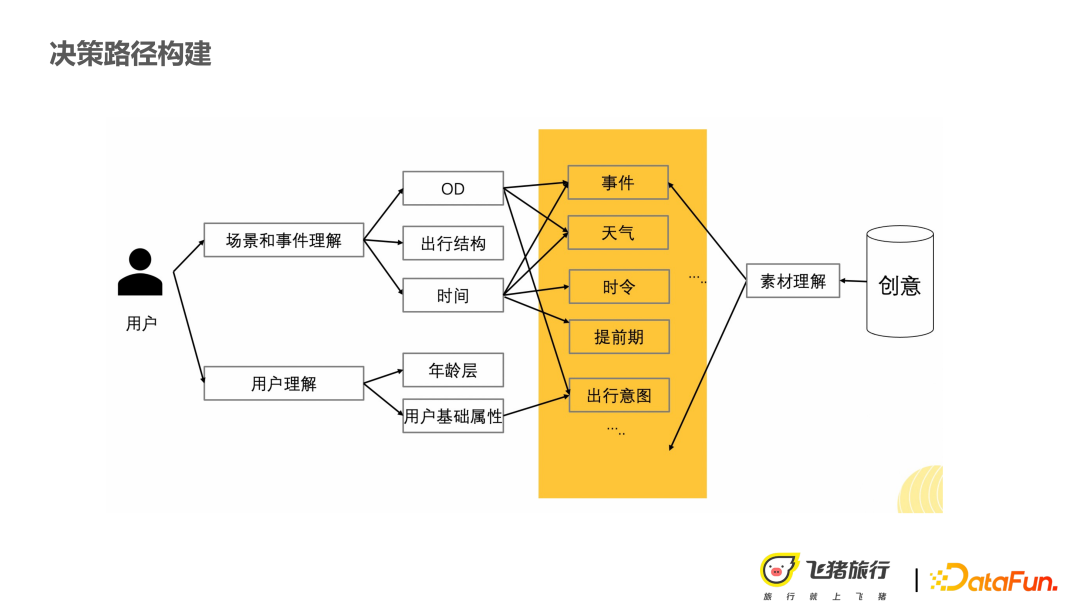
#剛剛提到的用戶,透過建構場景和事件的理解和創意理解。最後,把所有的節點類型都統一到如上圖所示的結構中。

得到節點之後,進行結構學習,使用 Hockman scoring function grade search 。這個過程主要是在給定資料和網路結構之後,計算得到網路的後驗機率值,評估這個網路到底有沒有效。
在做 Hockman scoring function 的時候,可能有多種變量,離散型或連續型。在建構時都變成一種離散變量,方便後續的解釋和建模。我們會假設每一個變數符合狄利克雷分佈,施加於樣本上去做後驗的更新,再計算每個節點的後驗的值,把節點之間的機率相乘,得到結構的評分。比較通用,大家如果有興趣,可以後面詳細了解下這個方法。由於網路結構比較複雜,所以在整個網路中選用 greedy search 的方法。參數估計比較簡單,根據樣本對節點的條件機率表做更新。

#可解釋的應用,基於結構以及參數的更新,可以做兩個部分的事情:
① 基於各類別的evidence 推論使用者可能會做哪種決策,就像上文中提到的那些例子。可以使用 Likelihood weighting 或 Loopy Belief Propagation,這些是比較常見的一些方法。
#② 歸因,上圖裡面顯示的是健康類的保險,例如意外險突然熱銷,我們很想知道背後的原因,是因為有人喜歡買,可能用戶的消費力比較高,還是因為使用者是新人以前不怎麼坐飛機,或是用戶的目的地存在高原屬性,因為害怕心理導致購買。
最後進行總結,因果推論在保險產品推薦、紅包和文案行銷的人群和推薦策略中起到了很大的效果。同時,結合貝葉斯因果圖的建構和視覺化的解釋,可以為業務提供一些比較有意義的決策,讓他們可以持續更新策略或文案,或是進行一些方向性的變更。透過貝葉斯因果圖,也為特徵的選擇提供了新的思路。
五、問答環節
Q1:飛豬保險行銷採取的 Uplift model 是否在落地後進行過驗證?在導入因果推斷模型前,飛書保險行銷採用的是什麼技術?局限性在哪裡?導入這個因果推論模型後,最明顯的改善在什麼地方?
A1:① 驗證是有的,因為已經在線上的 AB 上得到了效果提升。
② 在導入因果模型之前,舉個例子,在紅包場景最開始的策略是轉換率預估。如果能預估到一個使用者群體,它本來是不轉換的,對他們進行行銷操作,可以保證的是,行銷的成本是能被控制的。
③ 局限性,使用者的轉換率可能不高,這意味著即使你給他紅包,他也會不轉換。所以是我們之前遇到的一些問題。
④ 導入因果模型推論之後,最明顯的改善在應該是使用者彈性上。使用因果推論技術之後,可以對使用者有更清晰的理解,對使用者群種子有更清晰的判斷。
Q2:因果推論模型的特徵怎麼選擇?哪些特徵在場景下是最重要的?
A2:第一步如果大量的特徵進行選擇,效果可能不太好。在初始選的時候,我們使用單變量,看變數和增益之間有沒有特別強的相關性,有才會把它放進去。當然,後面在樹模型上可以看到對特徵進行評分,然後篩選,是我們去判斷的一個依據。
Q3:差分建模時資料出現 selection bias 嗎? T-Learner 是不能應付這種問題?評估時為什麼沒有使用 AUUC ?貝葉斯因果網絡的隱變數是指什麼?
A3:① 差分建模,它會導致一個誤差累積。
② T-learner 主要是透過離線的評估。這個問題當時我們也比較困惑,總結下,覺得可能是在特徵上,沒有一個非常強的特徵,直接對增益進行刻畫。所以後面在一些傳統的模型上,得到的效果也不是很差。這裡只是複雜模型和簡單模型的評估,簡單模型可能在穩健性上會更強一點。
③ AUUC 其實我們也有用到的,其實是差太多。
④ 觀測變數可能是指資料上可觀測的變量,而隱藏變數是指我們在觀測到的資料上面可以去刻畫的隱含的變數。例如性格這種,當然網路裡面還沒用到。
Q4:在實務上是否嘗試過使用 matching method 後跟隨一個迴歸的方?如果有,效果如何?
A4:還沒嘗試過。
#Q5:你們後續的探索是在什麼方向?例如現在是在保險的推薦探索的方向。
A5:因果推論是我們去年的一個工作,今年主要是在創意文案的推薦。
#以上是因果推薦技術在行銷和可解釋性上的應用的詳細內容。更多資訊請關注PHP中文網其他相關文章!