
機器學習真能產生智慧決策嗎?

- 王林轉載
- 2023-05-17 08:16:05735瀏覽
歷經三年時間,我們在2022年完成了圖靈獎得主、加州大學洛杉磯分校電腦科學教授,美國國家科學院院士,被譽為「貝葉斯網路之父」的朱迪亞·珀爾大作《因果論:模型、推理與推論》。
這本書原版的第1版寫於2000年,開創了因果分析和推斷的新想法和新方法,一出版就得到廣泛的好評,促進了數據科學、人工智慧、機器學習、因果分析等領域的新革命,在學術界產生了很大的影響。
後來又在2009年修訂了第2版,內容上結合當時因果研究的新發展,做了較大的改變。目前我們翻譯的這本書英文原版是在2009年出版的,到目前已經有十多年了。
此書中文版的出版有利於廣大中國學者、學生和各領域的實踐人員了解和掌握因果模型、推理和推斷相關的內容。特別是在當前統計學和機器學習流行的時代,如何實現從「數據擬合」到「數據理解」的轉變?如何在下一個十年裡,從「所有知識都來自資料本身」這一目前佔據主流的假設到一個全新的機器學習範式?是否會引發「第二次人工智慧革命」?
正如圖靈獎授予珀爾時評價他的工作為「人工智慧領域的基礎性貢獻,他提出機率和因果性推理算法,徹底改變了人工智慧最初基於規則和邏輯的方向。」 我們期待這種範式能為機器學習帶來新的技術方向和前進動力,並且最終能夠在實際應用中發揮作用。
正如珀爾所說「資料擬合目前牢牢地統治著當前的統計學和機器學習領域,是當今大多數機器學習研究者的主要研究範式,尤其是那些從事連接主義、深度學習和神經網路技術的研究者。」 這種以「數據擬合」為核心的範式在電腦視覺、語音辨識和自動駕駛等應用領域取得了令人矚目的成功。但是,許多數據科學領域的研究人員也已經意識到,從當前實踐效果來看,機器學習無法產生智慧決策所需的那種理解能力。這些問題包括:穩健性、可遷移性、可解釋性等。下面我們來看看例子。
1.資料統計可靠度嗎?
近年來來自媒體上的很多人都會覺得自己是統計學家。因為「資料擬合」「所有知識都來自資料本身」為許多重大決策提供了資料統計依據。但是,在進行分析時,我們需要謹慎分析。畢竟,事情可能並不總是乍看之下!與我們生活息息相關的案例。 10年前,某城市市中心的房價是8,000元/平米,共銷售了1,000萬平;高新區是4,000元/平米,共銷售了100萬平;整體來看,該市的平均房價為7,636元/平米。現在,市中心10000元/平米,但由於市中心的土地供應少了,只銷售了200萬平;高新區是6000元/平米,但由於新開發的土地變多了,銷售了2000萬平;整體來看,現在該市的平均房價為6363元/平米。因此,分區來看房價分別都漲了,但從整體來看,會有產生疑惑:為什麼現在的房價反而跌了呢?
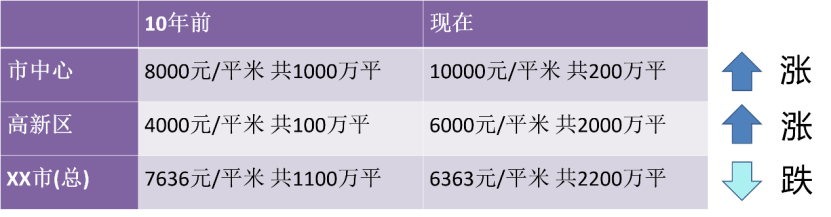
圖1 房價趨勢依照不同區域分割後與總體結論相悖
我們知道這種現象叫作辛普森悖論。這些案例清楚地表明當我們沒有給予足夠的觀察變數時,我們是如何從統計數據中得到了完全錯誤的模型和結論。就這次新冠大流行而言,我們通常會獲得全國範圍的統計數據。如果我們按地區或市縣分組,我們可能會得出截然不同的結論。在全國範圍內,我們可以觀察到新冠病例數量正在下降,儘管某些地區的病例數量會增加(這可能預示著下一波浪潮的開始)。如果存在差異很大的群體,例如人口差異很大的地區,則也可能發生這種情況。在國家數據中,人口密度較低地區的病例激增可能與人口稠密地區的病例下降相形見絀。
類似的基於「資料擬合」的統計問題比比皆是。例如下面兩個有趣的例子。
如果我們每年收集尼可拉斯凱吉每年出現的電影數量和美國溺死人數的數據,我們會發現這兩個變數高度相關,數據擬合程度奇高。
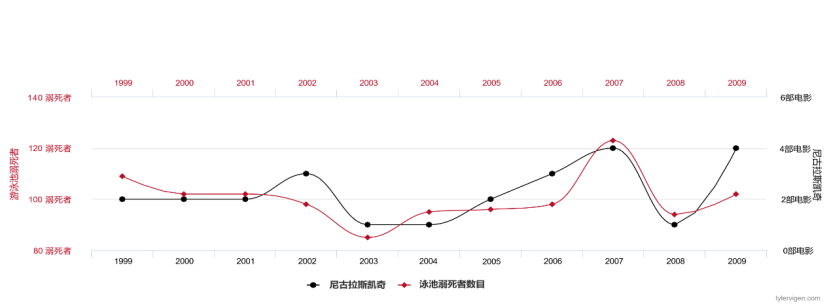
圖2 尼可拉斯凱吉每年演出的電影數與美國溺死的人數
如果我們收集每個國家人均牛奶銷售量和獲得諾貝爾獎人數的數據,我們會發現這兩個變數高度相關。
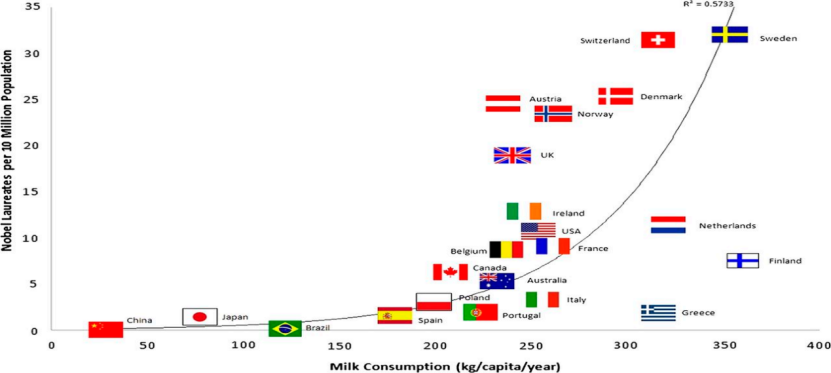
圖3 人均牛奶消費量與諾貝爾獎人數
從我們人類的常識認知來說,這些都是偽相關,甚至是悖論。但從數學和機率論的角度來看,表現出偽相關或悖論的案例無論從數據上或計算上都是沒有問題的。如果有一些因果基礎的人都知道,發生這種情況是因為數據中隱藏著所謂的潛伏變量,即未被觀察到的混雜因子。
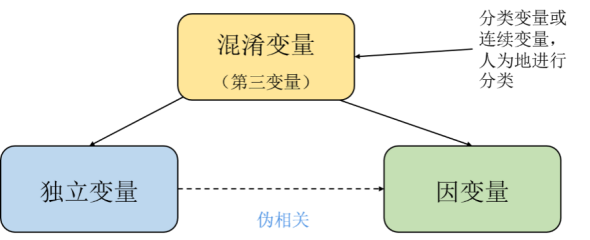
#圖4 獨立變數導致了兩個變數之間偽相關
#珀爾在《因果論》中給出了解決的範式,詳細分析和推導了以上問題,強調了因果與統計之間有著本質的區別,雖然因果分析與推斷仍然是建立在統計學的語境上。珀爾提出了乾預操作(算子)的基本計算模式,包括後門原則和具體的計算公式,這是目前因果關係最為數學化的描述。 “因果以及相關的概念(例如隨機化、混雜、幹預等)不是統計概念”,這是貫穿珀爾因果分析思想的一條基本原理,珀爾稱之為第一原理[2]。
那麼,目前基於數據驅動的機器學習方法,特別是那些嚴重依賴統計方法的演算法,學習到的模型極大可能也會出現半真半假、誤導性或反轉性的結果。這是因為這些模型往往是基於觀察資料的分佈來學習,而非資料產生的機制。
2.機器學習亟需解決的三個問題
穩健性:隨著深度學習方法的流行,計算機視覺、自然語言處理和語音辨識等研究大量利用了最先進的深層神經網路結構。但仍然長期存在這樣一個事實問題,即在現實世界中,我們採集到數據的分佈通常很少是完整的,與實際世界中的分佈可能不一致。在電腦視覺應用中,訓練集與測試集資料分佈可能受到來自諸如像素差、壓縮質量,或來自於攝影機位移、旋轉或角度等的影響。這些變數其實就是因果概念中的「幹預」問題。由此,人們提出了簡單的演算法來模擬幹預,以專門測試分類和識別模型的泛化能力,如空間偏移、模糊、亮度或對比度的變化、背景控制和旋轉,以及在多種環境中收集的圖像等。到目前為止,儘管我們利用資料增強、預訓練、自監督學習等方法在穩健性上取得了一定的進展,但對於如何解決這些問題還沒有明確的共識。有人認為這些修正可能是不夠的,在獨立同分佈假設之外進行泛化不僅需要學習變數之間的統計關聯,還需要學習潛在的因果模型,以明確資料產生的機制,並允許透過介入概念模擬分佈變化。
#可遷移性:嬰兒對物體的理解是基於追蹤隨時間變化表現一致的物體,這樣的方法可以讓嬰兒快速學習新的任務,因為他們對物體的知識和直觀理解可以重複使用。類似地,能夠有效率地解決現實世界中的任務需要在新的場景中重複使用學習到的知識技能。研究已經證明,學習了環境知識的機器學習系統效率更高,通用性更好。如果我們將現實世界模型化,許多模組在不同的任務和環境中表現出相似的行為。因此,面對新環境或新任務,人類或機器可能只需要調整其內部表示中的幾個模組。當學習因果模型時,由於大多數知識(即模組)可以在無須進一步訓練的情況下重複使用,因此只需要較少的樣本以適應新環境或新任務。
可解釋性:可解釋性是一個微妙的概念,不能僅僅使用布林邏輯或統計機率的語言完全描述,它需要額外的干預概念,甚至是反事實的概念。因果關係中的可操縱性定義關注的是這樣一個事實,即條件概率(“看到人們打開雨傘表明正在下雨”)無法可靠地預測主動幹預的結果(“收起雨傘並不能阻止下雨” )。因果關係被視為推理鏈的組成部分,它可以為與觀察到的分佈相去甚遠的情況提供預測,甚至可以為純粹假設的場景提供結論。從這個意義上說,發現因果關係意味著獲得可靠的知識,這些知識不受觀察到的資料分佈和訓練任務的限制,從而為可解釋的學習提供明確的說明。
3.因果學習建模的三個層次
具體地說,基於統計模型的機器學習模型只能對相關關係進行建模,而相關關係往往會隨著數據分佈的變化而變化;而因果模型是基於因果關係建模,則抓住了數據生成的本質,反映了數據生成機制的關係,這樣的關係更加穩健,具有分佈外泛化的能力。例如,在決策理論中,因果關係和統計之間的差異更加清楚。決策理論有兩類問題,一類是已知當前環境,擬採取乾預,預測結果。另一類是已知目前環境和結果,反推原因。前者稱為求果問題,後者稱為溯因問題[3]。
在獨立同分佈條件下的預測能力
統計模型只是對觀察到的現實世界的粗淺描述,因為它們只關注相關關係。對於樣本和標籤,我們可以透過估計來回答這樣的問題:「這張特定的照片中有一隻狗的機率是多少?」「已知一些症狀,心臟衰竭的機率是多少?」。這樣的問題是可以透過觀察足夠多的由所產生的獨立同分佈資料來回答的。儘管機器學習演算法可以把這些事做得很好,但是準確的預測結果對於我們的決策是不夠,而因果學習為其提供了一種有益的補充。就前面的例子來說,尼可拉斯凱吉演出電影的頻率和美國溺亡率正相關,我們的確可以訓練一個統計學習模型透過尼可拉斯凱吉演出電影的頻率來預測美國溺亡率,但顯然這兩者並沒有什麼直接的因果關係。統計模型只有在獨立同分佈的情況下才是準確的,如果我們做任何的干預來改變資料分佈,就會導致統計學習模型出錯。
在分佈偏移/幹預下的預測能力
我們進一步討論幹預問題,它更具挑戰性,因為幹預(操作)會使我們跳出統計學習中獨立同分佈的假設。繼續用尼可拉斯凱吉的例子,「今年增加邀請尼可拉斯凱吉演出電影的數量會增加美國的溺亡率嗎?」就是一個幹預問題。顯然,人為的干預會使得資料分佈發生變化,統計學習賴以生存的條件就會被打破,所以它會失效。另一方面,如果我們可以在有介入的情況下學習一個預測模型,那麼這有可能讓我們得到一個在現實環境中對分佈變化更加穩健的模型。實際上,這裡所謂的干預並不是什麼新鮮事,很多事情本身就是隨時間變化的,例如人的興趣偏好,或者模型的訓練集與測試集本身在分佈上就存在不匹配的現象。我們前面已經提到,神經網路的穩健性已經獲得了越來越多的關注,成為一個與因果推論緊密連結的研究主題。在分佈偏移的情況下預測不能只局限於在測試集上取得高準確率,如果我們希望在實際應用中使用機器學習演算法,那麼我們必須相信在環境條件改變的情況下,模型的預測結果也是準確的。實際應用中的分佈偏移類別可能多種多樣,一個模型僅僅在某些測試集上取得好效果,不能代表我們可以在任何情況下都能夠信任這個模型,這些測試集可能只是恰好符合這些測試集樣本的分佈。為了讓我們可以在盡可能多的情況下信任預測模型,就必須採用具有回答幹預問題能力的模型,至少僅僅使用統計學習模型是不行的。
回答反事實問題的能力
反事實問題涉及推理事情為什麼會發生,想像實施不同行為所帶來的後果,並由此可以決定採取何種行為來達到期望的結果。回答反事實問題比介入更加困難,但也是對於AI非常關鍵的挑戰。如果一個幹預問題是“如果我們現在讓一個病人有規律地進行鍛煉,那麼他心臟衰竭的機率會如何變化?”,對應的反事實問題就是“如果這個已經發生心臟衰竭的病人一年前就開始鍛煉,那他還會得心臟衰竭嗎?」顯然回答這樣的反事實問題對於強化學習是很重要的,它們可以通過反思自己的決策,制定反事實假說,再通過實踐驗證,就像我們的科學研究一樣。
4.因果學習應用
最後,我們來看看如何在各個領域應用因果學習。 2021年諾貝爾經濟學獎頒給了約書亞·安格里斯特(Joshua D.Angrist)和吉多·因本斯(Guido W.Imbens),表彰「他們對因果關係分析的方法論」貢獻。他們研究了因果推論在實證勞動經濟學的應用。諾貝爾經濟學獎評選委員認為“自然實驗(隨機試驗或對照試驗)有助於回答重要問題”,但如何“使用觀測數據回答因果關係”更具挑戰性。經濟學中的重要問題是因果關係問題。如移民如何影響當地人的勞動市場前景?讀研究所能夠影響收入增加嗎?最低工資對技術工人的就業前景有何影響?這些問題很難回答,因為我們缺乏正確的反事實解釋方法。
自從1970年代以來,統計學家就發明了一套計算「反事實」的框架,以揭示兩個變數之間的因果效應。經濟學家又在此基礎上進一步發展了斷點迴歸、雙重差分、傾向分數等方法,並且大量地應用於各種經濟政策議題的因果性研究。從6世紀的宗教文本到2021年的因果機器學習,包括因果自然語言處理,我們可以使用機器學習、統計學和計量經濟學來模擬因果效應。經濟學和其他社會科學的分析主要圍繞著因果效應的估計,即一個特徵變數對於結果變數的干預效應。實際上,在大多數情況下,我們感興趣的事情是所謂的干預效應。介入效應是指介入或治療對結果變項的因果影響。例如在經濟學中,分析最多的干預效應之一是對企業進行補貼對企業收入的因果影響。為此,魯賓(Rubin)提出了潛在成果架構(potential outcome framework)。
儘管經濟學家和其他社會科學家對因果效應的精確估計能力強於預測能力,但他們對機器學習方法的預測優勢也十分感興趣。例如,精確的樣本預測能力或處理大量特徵的能力。但正如我們所看到的,經典機器學習模型並非旨在估計因果效應,使用機器學習中現成的預測方法會導致因果效應的估計偏差。那麼,我們必須改進現有的機器學習技術,以利用機器學習的優勢來持續有效地估計因果效應,這就促使了因果機器學習的誕生!
目前,根據要估計的因果效應類型,因果機器學習可以大致分為兩個研究方向。一個重要的方向是改進機器學習方法以用於無偏且一致的平均幹預效應估計。該研究領域的模型試圖回答以下問題:客戶對行銷活動的平均反應是什麼?價格變動對銷售額的平均影響是多少?此外,因果機器學習研究的另一條發展路線是專注於改進機器學習方法以揭示幹預效應的特異性,即識別具有大於或小於平均幹預效應的個體亞群。這類模型旨在回答以下問題:哪些客戶對行銷活動的反應最大?價格變動對銷售額的影響如何隨著顧客年齡的變化而改變?
除了這些活生生的例子,我們還可以感覺到因果機器學習引起資料科學家興趣的一個更深刻的原因是模型的泛化能力。具備描述資料之間因果關係的機器學習模型可泛化到新的環境中,但這仍然是目前機器學習的最大挑戰之一。
珀爾更深層地分析這些問題,認為如果機器不會因果推理,我們將永遠無法獲得達到真正人類水平的人工智慧,因為因果關係是我們人類處理和理解周遭複雜世界的關鍵機制。珀爾在《因果論》中文版的序中寫到「在下一個十年裡,這個框架將與現有的機器學習系統相結合,從而可能引發'第二次因果革命'。我希望這本書也能使中國讀者積極參與這場即將到來的革命之中。」
##############################################################以上是機器學習真能產生智慧決策嗎?的詳細內容。更多資訊請關注PHP中文網其他相關文章!