
從輸入網址到最後瀏覽器呈現頁面內容的流程分析

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-16 11:28:121596瀏覽
準備
當你在瀏覽器中輸入網址(例如www.coder.com)並且敲了回車以後, 瀏覽器首先要做的事情就是獲得coder. com的IP位址,具體的做法就是發送一個UDP的包給DNS伺服器,DNS伺服器會回傳coder.com的IP, 這時候瀏覽器通常會把IP位址給快取起來,這樣下次造訪就會加快。
例如Chrome, 你可以透過chrome://net-internals/#dns來查看。
有了伺服器的IP, 瀏覽器就要可以發起HTTP請求了,但是HTTP Request/Response必須在TCP這個「虛擬的連線」上來傳送和接收。
想要建立「虛擬的」TCP連接,TCP郵差需要知道4個東西:(本機IP, 本機端口,伺服器IP, 伺服器連接埠),現在只知道本機IP,伺服器IP , 兩個連接埠怎麼辦?
本機連接埠很簡單,作業系統可以給瀏覽器隨機分配一個, 伺服器連接埠更簡單,用的是一個「眾所周知」的端口,HTTP服務就是80, 我們直接告訴TCP郵差就行。
經過三次握手以後,客戶端和伺服器端的TCP連線就建立起來了!終於可以發送HTTP請求了。

之所以把TCP連線畫成虛線,是因為這個連線是虛擬的
Web伺服器
一個HTTP GET請求經過千山萬水,經過多個路由器的轉發,終於到達伺服器端(HTTP封包可能被下層進行分片傳輸,略去不表)。
Web伺服器需要著手處理了,它有三種方式來處理:
(1) 可以用一個執行緒來處理所有請求,在同一時刻只能處理一個,這種結構易於實現,但是這樣會造成嚴重的效能問題。
(2) 可以為每個請求分配一個進程/線程,但是當連接太多的時候,伺服器端的進程/線程會耗費大量記憶體資源,進程/線程的切換也會讓CPU不堪負荷。
(3) 復用I/O的方式,許多Web伺服器都採用了複用結構,例如透過epoll的方式監視所有的連接,當連接的狀態發生變化(如有資料可讀) , 才用一個行程/執行緒對那個連線處理,處理完以後繼續監視,等待下次狀態改變。用這種方式可以用少量的進程/執行緒來應對成千上萬的連線請求。
我們使用Nginx這個非常流行的Web伺服器來繼續下面的故事。
對於HTTP GET請求,Nginx利用epoll的方式給讀取了出來,Nginx接下來要判斷,這是個靜態的請求還是個動態的請求啊?
如果是靜態的請求(HTML文件,JavaScript文件,CSS文件,圖片等),也許自己就能搞定了(當然依賴於Nginx配置,可能轉發到別的緩存伺服器去),讀取本機硬碟上的相關文件,直接回傳。
如果是動態的請求,需要後端伺服器(如Tomcat)處理以後才能返回,那就需要向Tomcat轉發,如果後端的Tomcat還不止一個,那就需要按照某種策略選取一個。
例如Ngnix支援這麼多種:
輪詢:依序挨個向後端伺服器轉送
權重:給每個後端伺服器指定一個權重,相當於向後端伺服器轉送的幾率。
ip_hash: 依照ip做一個hash操作,然後找伺服器轉發,這樣的話同一個客戶端ip總是會轉發到同一個後端伺服器。
fair:根據後端伺服器的回應時間來分配請求,回應時間段的優先分配。
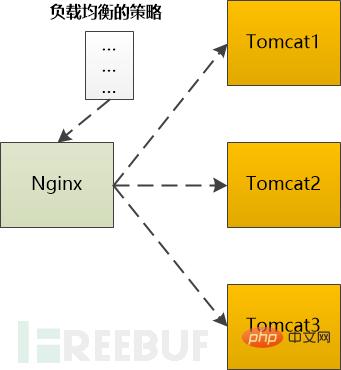
不管用哪種演算法,某個後端伺服器最終被選中,然後Nginx需要把HTTP Request轉發給後端的Tomcat,並且把Tomcat輸出的HttpResponse再轉發給瀏覽器。
由此可見,Nginx在這種場景下,是一個代理人的角色。

應用程式伺服器
Http Request終於來到了Tomcat,這是一個由Java寫的、可以處理Servlet/JSP的容器,我們的程式碼就運行在這個容器之中。
如同Web伺服器一樣, Tomcat也可能為每個請求分配一個執行緒去處理,也就是通常所說的BIO模式(Blocking I/O 模式)。
也可能使用I/O多路復用技術,僅使用若干執行緒來處理所有請求,即NIO模式。
不管用哪一種方式,Http Request 都會被交給某個Servlet處理,這個Servlet又會把Http Request做轉換,變成框架所使用的參數格式,然後分發給某個Controller(如果你是在用Spring)或是Action(如果你是在Struts)。
The rest of the story is relatively simple (no, for coders, it is actually the most complicated part), which is to execute the add, delete, modify and check logic that coders often write. In this process, it is very likely to interact with cache, The database and other back-end components deal with each other and ultimately return HTTP Response. Since the details depend on the business logic, they are omitted.
According to our example, this HTTP Response should be an HTML page.
Homecoming
Tomcat happily sent the Http Response to Ngnix.
Ngnix is also happy to send the Http Response to the browser.

Can the TCP connection be closed after sending?
If you are using HTTP1.1, this connection is keep-alive by default, which means it cannot be closed;
If you are using HTTP1.0, you need to check the previous HTTP Request Header. There is no Connection:keep-alive. If there is, it cannot be turned off.
The browser works again
The browser received the Http Response, read the HTML page from it, and began to prepare to display the page.
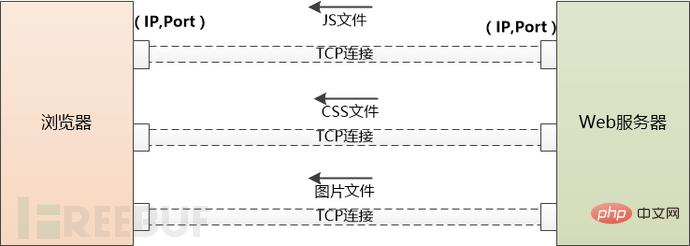
But this HTML page may reference a large number of other resources, such as js files, CSS files, pictures, etc. These resources are also located on the server side and may be located under another domain name, such as static.coder.com.
The browser has no choice but to download them one by one. Starting from using DNS to obtain the IP, the things that have been done before have to be done again. The difference is that there will no longer be the intervention of application servers such as Tomcat.
If there are too many external resources that need to be downloaded, the browser will create multiple TCP connections and download them in parallel.
But the number of requests to the same domain name at the same time cannot be too many, otherwise the server will have too much traffic and will not be able to bear it. Therefore, browsers need to limit themselves. For example, Chrome can only download 6 resources in parallel under Http1.1.
When the server sends JS and CSS files to the browser, it will tell the browser when these files will expire (using Cache-Control or Expire), and the browser can The file is cached locally. When the same file is requested for the second time, if it does not expire, it can be retrieved directly from the local area.
If it expires, the browser can ask the server whether the file has been modified? (Based on the Last-Modified and ETag sent by the last server), if it has not been modified (304 Not Modified), you can also use caching. Otherwise the server will send the latest file back to the browser.
Of course, if you press Ctrl F5, a GET request will be forcibly issued, completely ignoring the cache.
Note: Under Chrome, you can view the cache through the chrome://view-http-cache/ command.
Now the browser gets three important things:
1.HTML, the browser turns it into a DOM Tree
2. CSS, the browser Turn it into a CSS Rule Tree
3. JavaScript, it can modify the DOM Tree
The browser will generate the so-called "Render Tree" through the DOM Tree and CSS Rule Tree, calculating each The position/size of each element, layout, and then calling the API of the operating system for drawing. This is a very complicated process and will not be shown here.
So far, we finally see the content of www.coder.com in the browser.
以上是從輸入網址到最後瀏覽器呈現頁面內容的流程分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!