
OpenAI文字生成3D模型再升級,數秒完成建模,比Point·E更好用

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-16 10:04:131653瀏覽
生成式 AI 大模型是 OpenAI 發力的重點,目前已經推出過文字生成圖像模型 DALL-E 和 DALL-E 2,以及今年初基於文字生成 3D 模型的 POINT-E。
近日,OpenAI 研究團隊升級了3D 生成模型,全新推出了Shap・E,它是一個用於合成3D 資產的條件生成式模型。目前相關模型權重、推理程式碼和樣本已開源。

- 論文網址:https://arxiv.org/abs/2305.02463
- #專案網址:https://github.com/openai/shap-e
我們先來看看生成效果。與根據文字產生影像類似,Shap・E 產生的 3D 物件模型主打一個「天馬行空」。例如,一個看起來像香蕉的飛機:

看起來像一棵樹的椅子:

##還有經典例子,像酪梨的椅子:

#當然也可以產生一些常見物體的三維模型,例如一碗蔬菜:

#甜甜圈:


#本文提出的Shap・E 是一種在3D 隱式函數空間上的潛擴散模型,可以渲染成NeRF 和紋理網格。在給定相同的資料集、模型架構和訓練計算的情況下,Shap・E 更優於同類明確生成模型。研究者發現純文字條件模型可以產生多樣化、有趣的物體,更彰顯了生成隱式表徵的潛力。
#############不同於3D 產生模型上產生單一輸出表示的工作,Shap-E 能夠直接產生隱式函數的參數。訓練 Shap-E 分為兩個階段:首先訓練編碼器,該編碼器將 3D 資產確定性地映射到隱式函數的參數;其次在編碼器的輸出上訓練條件擴散模型。當在配對 3D 和文字資料的大型資料集上進行訓練時, 該模型能夠在幾秒鐘內產生複雜而多樣的 3D 資產。 ######與點雲明確產生模型Point・E 相比,Shap-E 建模了高維、多表示的輸出空間,收斂更快,並且達到了相當或更好的樣本品質## ####。 #########研究背景#########本文聚焦兩種用於 3D 表示的隱式神經表示(INR):######
- NeRF 一個INR,它將3D 場景表示為將座標和視向映射到密度和RGB 顏色的函數;
- ##DMTet 及其擴充GET3D表示一個紋理3D 網格,它作為函數將座標映射到顏色、符號距離和頂點偏移的。這種 INR 能夠以可微的方式建構 3D 三角網格,然後渲染為可微的柵格化庫。
雖然 INR 靈活且富有表現力,但為資料集中每個樣本取得 INR 的成本高昂。此外每個 INR 可能有許多數值參數,在訓練下游生成模型時可能會帶來難題。透過使用具有隱式解碼器的自動編碼器來解決這些問題,可以獲得較小的潛在表示,它們直接以現有生成技術進行建模。另外還有一種替代方法,就是使用元學習建立一個共享大部分參數的 INR 資料集,然後在這些 INR 的自由參數上訓練擴散模型或歸一化流。也有人提出,基於梯度的元學習可能並不必要,相反地應該直接訓練 Transformer 編碼器,產生以 3D 物件多個視圖為條件的 NeRF 參數。
研究者將上述幾種方法結合併拓展,最終得到了 Shap・E,並成為用於各種複雜 3D 隱式表示的條件生成模型。首先透過訓練基於 Transformer 的編碼器來為 3D 資產產生 INR 參數,然後在編碼器的輸出上訓練擴散模型。與先前的方式不同,產生同時表示 NeRF 和網格的 INR,允許它們以多種方式渲染或匯入下游 3D 應用。
當在數百萬個 3D 資產的資料集上訓練時,本文模型能夠在文字 prompt 的條件下產生多種可識別的樣本。與最近提出的顯式 3D 生成模型 Point・E 相比,Shap-E 收斂得更快。在相同的模型架構、資料集和條件作用機制的情況下,它能得到相當或更好的結果。
方法概覽研究者首先訓練編碼器產生隱式表示,然後在編碼器產生的潛在表示上訓練擴散模型,主要分為以下兩步完成:
1. 訓練一個編碼器,在給定已知3D 資產的密集明確表示的情況下,產生隱式函數的參數。編碼器產生3D 資產的潛在表示後線性投影,以獲得多層感知器(MLP)的權重;
2. 將編碼器應用於資料集,然後在潛在資料集上訓練擴散先驗。該模型以圖像或文字描述為條件。
研究者在一個大型的 3D 資產資料集上使用對應的渲染、點雲和文字標題訓練所有模型。
3D 編碼器
#編碼器架構如下圖 2 所示。
潛在擴散
#產生模型採用基於transformer 的Point・E 擴散架構,但使用潛在向量序列取代點雲。潛在函數形狀序列為 1024×1024,並以 1024 個 token 序列輸入 transformer,其中每個 token 對應於 MLP 權重矩陣的不同行。因此,該模型在計算上大致相當於基礎 Point・E 模型(即具有相同的上下文長度和寬度)。在此基礎上增加了輸入和輸出通道,能在更高維度的空間中產生樣本。
實驗結果編碼器評估
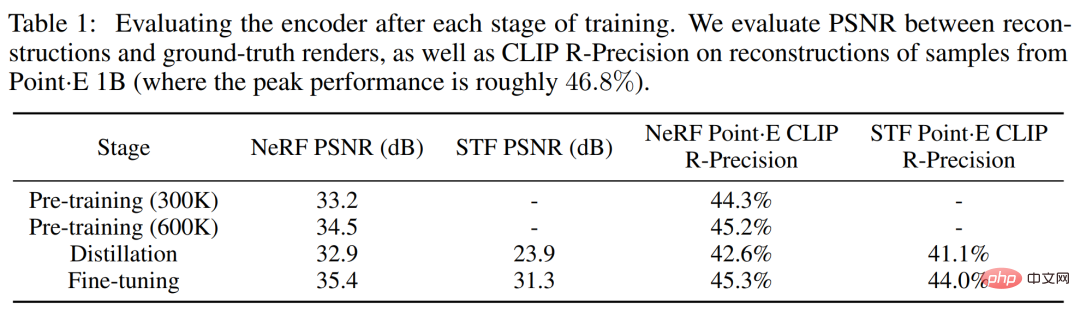
研究者在整個編碼器訓練過程中追蹤兩個基於渲染的指標。首先評估重建影像和真實渲染影像之間的峰值訊號雜訊比(PSNR)。此外,為了衡量編碼器捕捉 3D 資產語意相關細節的能力,對最大 Point・E 模型產生的網格進行編碼,重新評估重建 NeRF 和 STF 渲染的 CLIP R-Precision。
下表 1 追蹤了這兩個指標在不同訓練階段的結果。可以發現,蒸餾損害了 NeRF 重建質量,而微調不僅恢復還略微提高了 NeRF 質量,同時大幅提高了 STF 渲染質量。
對比Point・E
研究者提出的潛在擴散模型與Point・E. 具有相同架構、訓練資料集和條件模式。與 Point・E 進行比較更有利於區分生成隱式神經表示而不是顯式表示的影響。下圖 4 在基於樣本的評估指標上對這些方法進行了比較。
下圖 5 中顯示了定性樣本,可以看到這些模型通常為相同的文字 prompt 產生不同品質的樣本。在訓練結束之前,文本條件 Shap・E 在評估中開始變差。 
研究者發現 Shap・E 和 Point・E 傾向於共享相似的失敗案例,如下圖 6 (a) 所示。這表明訓練資料、模型架構和條件圖像對生成樣本的影響大於選擇的表示空間。
我們可以觀察到兩個圖像條件模型之間仍然存在一些定性差異,例如在下圖6 (b) 的第一行中,Point・E 忽略了長凳上的小縫隙,而Shap・E 試圖對它們進行建模。本文假設會出現這種特殊的差異,因為點雲不能很好地表示薄特徵或間隙。此外在表 1 中觀察發現,當應用於 Point・E 樣本時,3D 編碼器略微降低了 CLIP R-Precision。

#與其他方法比較
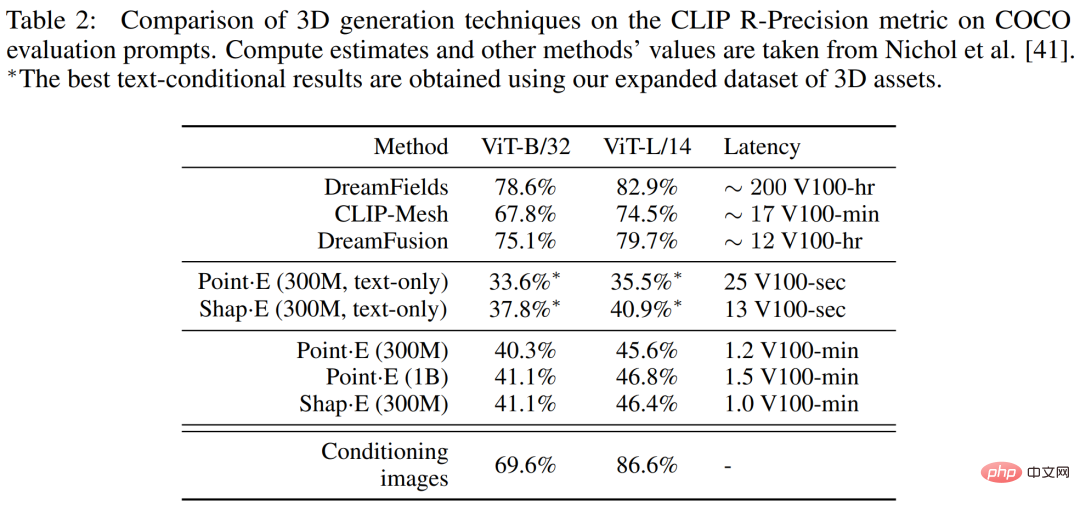
下表2 中,研究者在CLIP R-Precision 度量標準上將shape・E 與更廣泛的3D 生成技術進行了比較。
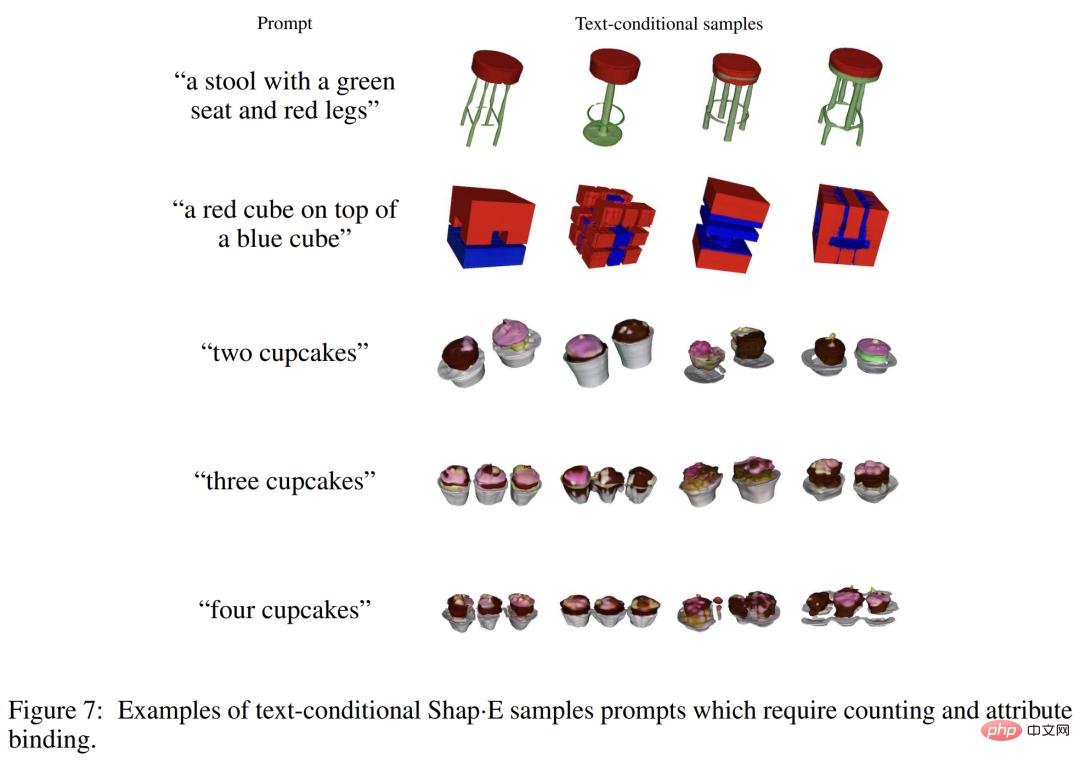
雖然Shap-E 可以理解許多具有簡單屬性的單一物件prompt,但它在組合概念方面的能力有限。下圖 7 中可發現,這個模型很難將多個屬性綁定到不同的對象,並且當請求兩個以上的對象時,無法有效產生正確的對象數量。這可能是配對訓練資料不足所導致的結果,透過收集或產生更大的標註 3D 資料集或許可以解決。

######################更多技巧與實驗細節請參考原文。 ######
以上是OpenAI文字生成3D模型再升級,數秒完成建模,比Point·E更好用的詳細內容。更多資訊請關注PHP中文網其他相關文章!