
徹底解決ChatGPT健忘症!突破Transformer輸入限制:實測支援200萬個有效token

- 王林轉載
- 2023-05-13 14:07:062182瀏覽
ChatGPT,或者說Transformer類別的模型都有一個致命缺陷,就是太容易健忘,一旦輸入序列的token超過上下文視窗閾值,後續輸出的內容和前文邏輯就對不上了。
ChatGPT只能支援4000個token(約3000個字)的輸入,即便最新發布的GPT-4也只支援最大32000的token窗口,如果繼續加大輸入序列長度,計算複雜度也會成二次方增長。
最近來自DeepPavlov, AIRI, 倫敦數學科學研究所的研究人員發布了一篇技術報告,使用循環記憶Transformer(RMT)將BERT的有效上下文長度提升到「前所未有的200萬tokens」,同時保持了很高的記憶檢索準確性。
論文連結:https://www.php.cn/link/459ad054a6417248a1166b30f6393301
此方法可以儲存和處理局部和全局訊息,並透過使用循環讓資訊在輸入序列的各segment之間流動。
實驗部分證明了該方法的有效性,在增強自然語言理解和生成任務中的長期依賴處理方面具有非凡的潛力,可以為記憶密集型應用程式實現大規模情境處理。
不過天下沒有免費的午餐,雖然RMT可以不增加記憶體消耗,可以擴展到近乎無限的序列長度,但仍然存在RNN中的記憶衰減問題,並且需要更長的推理時間。

但也有網友提出了解決方案,RMT用於長期記憶,大上下文用於短期記憶,然後在夜間/維修期間進行模型訓練。
循環記憶Transformer
2022年,該團隊提出循環記憶Transformer(RMT)模型,透過在輸入或輸出序列中添加一個特殊的memory token,然後對模型進行訓練以控制記憶操作與序列表徵處理,能夠在不改變原始Transformer模型的前提下,實現全新的記憶機制。

論文連結:https://arxiv.org/abs/2207.06881
發表會:NeurIPS 2022
與Transformer-XL相比,RMT需要的記憶體更少,並且可以處理更長序列的任務。
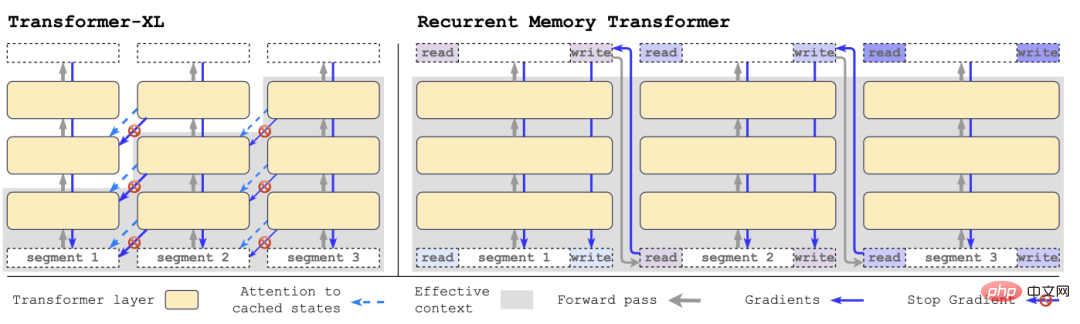
具體來說,RMT由m個實值的可訓練向量組成,過長的輸入序列被切分為幾個segments,記憶向量預設到在第一個segment embedding中,並與segment token一起處理。
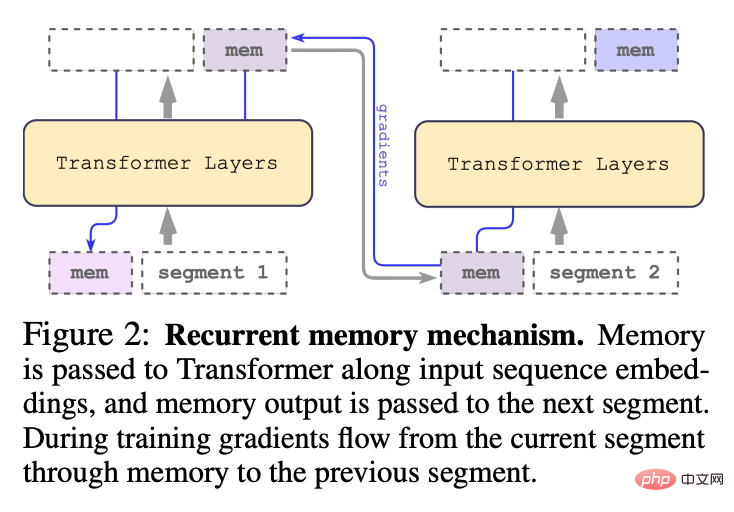
與2022年提出的原始RMT模型不同的是,對於像BERT這樣的純編碼器模型,只在segment的開始部分添加一次記憶;解碼模型將記憶分成讀寫兩部分。
在每個時間步長和segment中,以以下方式進行循環,其中N為Transformer的層數,t為時間步,H為segment
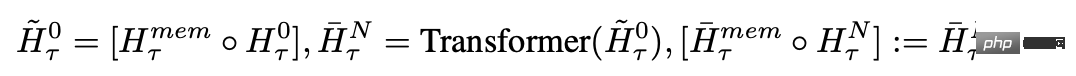
依序處理輸入序列的segments後,為了實現遞歸連接,研究人員將目前segment的memory token的輸出傳遞給下一個segment的輸入:
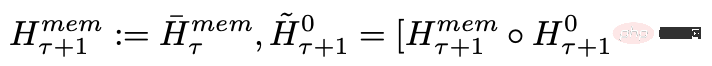
RMT中的記憶和循環都只基於全域memory token,可以保持骨幹Transformer模型不變,使得RMT的記憶增強能力可以與任意的Transformer模型相容。
計算效率
依照公式可以估算不同大小、序列長度的RMT和Transformer模型所需的FLOPs
在詞彙量大小、層數、隱藏大小、中間在隱藏大小和注意頭數的參數配置上,研究人員遵循OPT模型的配置,並計算了前向傳遞後的FLOPs數量,同時考慮到RMT循環的影響。
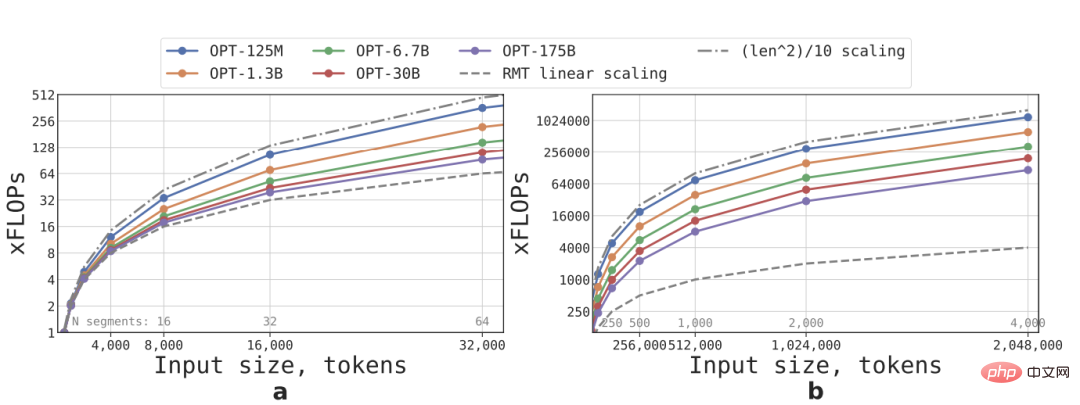
透過將一個輸入序列劃分為若干段,並且僅在segment的邊界內計算全部注意力矩陣來實現線性擴展,結果可以看到,如果segment長度固定,RMT的推理速度對任意模型尺寸都是線性成長的。
由於FFN層的計算量較大,所以較大的Transformer模型往往表現出相對於序列長度較慢的二次方增長速度,不過在長度大於32,000的極長序列上,FLOPs又回到了二次增長的狀態。
對於有一個以上segment的序列(在本研究中大於512),RMT比非循環模型有更低的FLOPs,在尺寸較小的模型上最多可以將FLOPs的效率提升×295倍;在尺寸較大的模型如OPT-175B,可以提升×29倍。
記憶任務
為了測試記憶能力,研究人員建立了一個合成資料集,要求模型記憶簡單的事實和基本推理。
任務輸入包括一個或幾個事實和一個只能用所有這些事實來回答的問題。
為了增加任務的難度,任務中還添加了與問題或答案無關的自然語言文本,這些文本可以看作是噪音,所以模型的任務實際上是將事實與不相關的文本分開,並使用事實文本來回答問題。

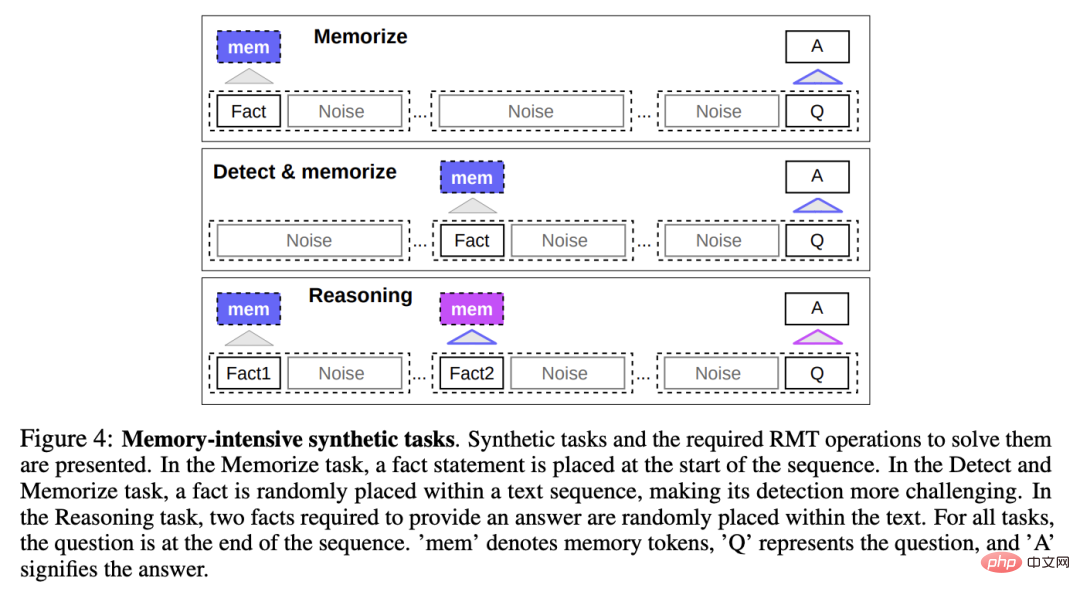
事實記憶
測試RMT在記憶中長時間寫入和儲存訊息的能力:在最簡單的情況下,事實位於輸入的開頭,問題在輸入的最後,並逐漸增加問題和答案之間的不相關文字數量,直到模型無法一次接受所有輸入。

事實檢測和記憶
事實檢測透過將事實移到輸入中的一個隨機位置來增加任務難度,要求模型首先將事實與不相關的文本區分開來,將其寫入記憶,然後回答位於最後的問題。
基於記憶事實進行推理
記憶的另一個重要操作是利用記憶的事實和當前的背景進行推理。
為了評估這個功能,研究人員引入了一個更複雜的任務,將產生兩個事實並隨機地放置在輸入序列;在序列末尾提出的問題是必須選擇用正確的事實來回答問題。

實驗結果
研究人員使用HuggingFace Transformers中預先訓練的Bert-base-cased模型作為所有實驗中RMT的主幹,所有模型以記憶大小為10進行增強。
在4-8塊英偉達1080Ti GPU上進行訓練和評估;對於更長的序列,則切換到單張40GB的英偉達A100上進行加速評估。
課程學習(Curriculum Learning)
研究人員觀察到,使用訓練排程可以顯著改善解決方案的準確性和穩定性。
剛開始讓RMT在較短的任務版本上進行訓練,在訓練收斂後,透過增加一個segment來增加任務長度,將課程學習過程一直持續到達到理想的輸入長度。
從適合單一segment的序列開始實驗,實際segment的大小為499,因為從模型輸入中保留了3個BERT的特殊標記和10個記憶佔位符,總共大小為512。
可以注意到,在對較短的任務進行訓練後,RMT更容易解決較長的任務,因為使用較少的訓練步驟就能收斂到完美的解決方案。
外推能力(Extrapolation Abilities)
為了觀察RMT對不同序列長度的泛化能力,研究人員評估了在不同數量的segment上訓練的模型,以解決更大長度的任務。
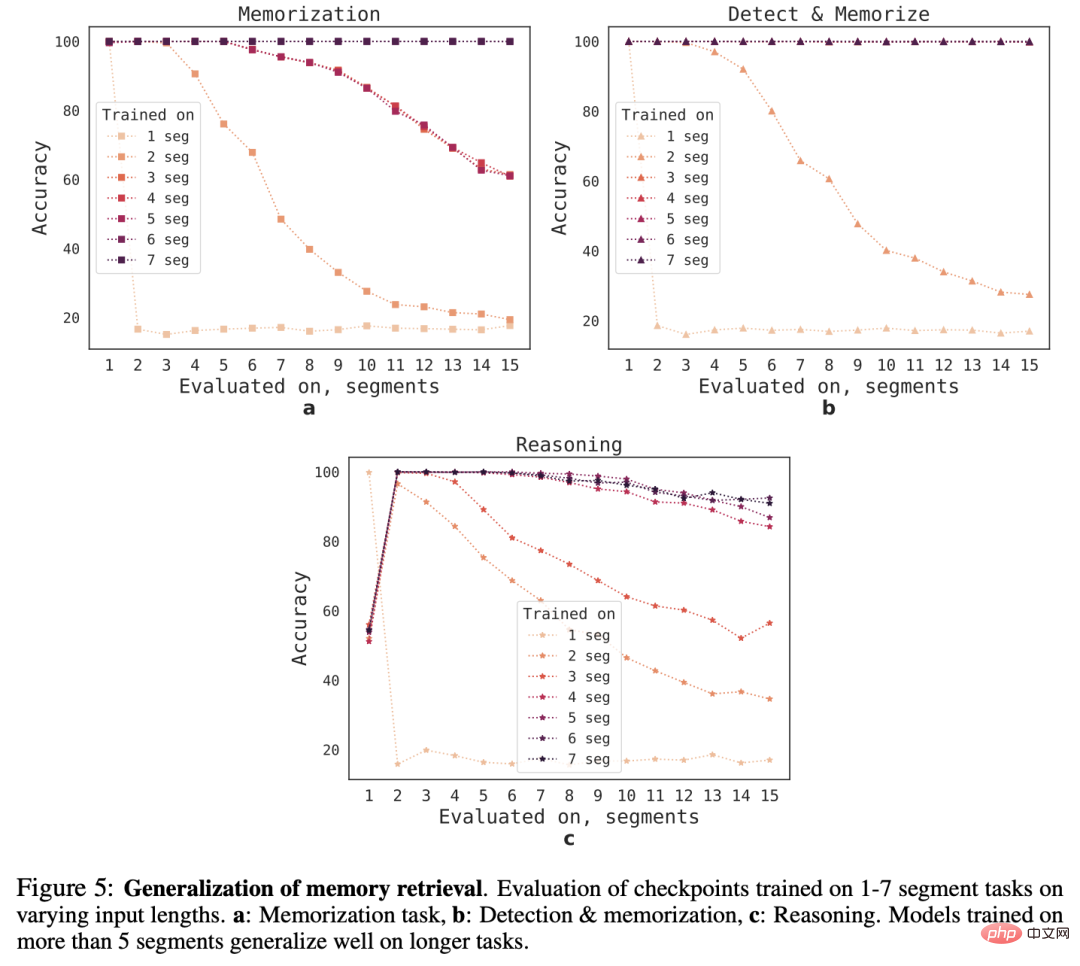
可以觀察到,模型在較短的任務上往往表現良好,但在較長的序列上訓練模型後,就很難處理單segment推理任務。
一個可能的解釋是,由於任務規模超過了一個segment,模型在第一個segment就停止了對問題的預期,導致品質下降。
有趣的是,隨著訓練segment數量的增加,RMT對較長序列的泛化能力也出現了,在對5個或更多的segment進行訓練後,RMT可以對兩倍長的任務進行近乎完美的泛化。
為了測試泛化的極限,研究人員驗證任務的規模增加到4096個segment(即2,043,904個tokens)。
RMT在如此長的序列上保持得出奇的好,其中“檢測和記憶”任務是最簡單的,推理任務是最複雜的。
參考資料:https://www.php.cn/link/459ad054a6417248a1166b30f6393301
#以上是徹底解決ChatGPT健忘症!突破Transformer輸入限制:實測支援200萬個有效token的詳細內容。更多資訊請關注PHP中文網其他相關文章!