
一種輕鬆且客觀介紹大模型方式,避免過度解讀

- 王林轉載
- 2023-05-12 18:13:061221瀏覽
一、前言
這篇文章旨在為沒有電腦科學背景的讀者提供一些關於ChatGPT及其類似的人工智慧系統(如GPT-3、GPT-4、Bing Chat、Bard等)如何工作的原理。 ChatGPT是一種聊天機器人,建立在一個大型語言模型之上,用於對話互動。這些術語可能比較晦澀難懂,我將對其進行解釋。同時,我們將討論它們背後的核心概念,而本文並不需要讀者俱備任何技術或數學的背景知識。我們將大量使用比喻來解釋相關概念,以便更好地理解它們。我們也將討論這些技術的意義,以及我們應該期待或不應該期待大型語言模型如ChatGPT所能做的事情。
接下來我們將以盡可能不使用專業術語的方式,從基礎的「什麼是人工智慧」開始,逐步深入討論與大型語言模型和ChatGPT相關的術語和概念,並將使用比喻來解釋它們。同時,我們也將談論這些技術的意義,以及我們應該期待它們能夠做什麼或不應該期待它們能夠做什麼。
二、什麼是人工智慧
首先,讓我們從一些基本術語開始,這些術語你可能經常聽到。那什麼是人工智慧呢?
人工智慧:指一種能夠表現出類似人類所認為的智慧行為的實體。用「智能」來定義人工智慧有些問題,因為「智能」本身並沒有一個清晰的定義。但是,這個定義仍然比較恰當。它基本上意味著,如果我們看到一些人造的東西,它們能夠進行有趣、有用、看起來有一定難度的行為,那麼我們可能會說它們具有智慧。例如,在電腦遊戲中,我們通常稱電腦控制的角色為「AI」。這些角色大多是基於if-then-else程式碼的簡單程式(例如,「如果玩家在射程範圍內,則開火,否則移動到最近的石頭後躲藏」)。但是,如果這些角色可以保持我們的參與和娛樂性,同時不做任何顯然愚蠢的事情,那麼我們可能會認為它們比實際上更為複雜。
一旦我們了解了某個東西的工作原理,我們可能就不會覺得它很神奇,而是期望在幕後有更複雜的東西。這完全取決於我們對幕後發生的事情的了解程度。
重要的一點是,人工智慧不是魔術。因為它不是魔術,所以它是可以解釋的。
三、 什麼是機器學習
另一個與人工智慧經常相關聯的術語是機器學習。
機器學習:一種透過收集資料、形成模型,然後執行模型的方式來創建行為的方法。有時候,手動建立一堆if-then-else語句以捕捉某些複雜現象(例如語言)是很困難的。在這種情況下,我們嘗試找到大量數據,並使用能夠在數據中找到模式的演算法進行建模。
那麼什麼是模型呢?模型是某種複雜現象的簡化版本。例如,汽車模型是真實汽車的更小、更簡單版本,它具有真實汽車許多屬性,當然並不意味著要完全替代原始版本。模型汽車可能看起來很真實,在實驗的時候很有用。

就像我們可以製造一個更小、更簡單的汽車一樣,我們也可以製造一個更小、更簡單的人類語言模型。我們使用「大型語言模型」這個術語,因為這些模型從需要使用的記憶體(顯存)量的角度來看是非常大的。目前生產中最大的模型,例如ChatGPT、GPT-3和GPT-4,非常龐大,需要運行在資料中心伺服器上的超級電腦才能建立和運作。
四、什麼是神經網路
有很多方法可以透過資料來學習一個模型,其中神經網路就是其中一種方法。這種技術大致基於人腦的結構,人腦由一系列互通的神經元組成,神經元之間傳遞電訊號,使我們能夠完成各種任務。神經網路的基本概念在20世紀40年代就已經被發明了,如何訓練神經網路的基本概念則是在20世紀80年代發明的,當時神經網路非常低效,直到2017年左右電腦硬體升級,我們才可以大規模地使用它們。
但是,個人比較喜歡用電路的隱喻來模擬神經網路。透過電阻、電流經過電線的流動,我們可以模擬神經網路的工作。
想像一下我們想要製作一輛可以在高速公路上行駛的自動駕駛汽車。我們在車的前、後和兩側裝上了距離感知器。當有物體接近時,距離感測器會報告一個值為1的數值,而當附近沒有可偵測的物體時,感測器會報告一個值為0的數值。
我們也安裝了機器人操作方向盤,踩煞車和加速。當油門接收到1的數值時,它使用最大的加速度,而0的數值意味著沒有加速。同樣,發送給煞車機構的數值為1意味著緊急煞車,而0則意味著沒有煞車。轉向機構接受-1到 1之間的數值,負數表示向左轉,正數表示向右轉,而0表示保持直線行駛。
當然我們必須記錄駕駛的數據。當前方的道路清晰時,你會加速。當前方有汽車時,你會減速。當一輛汽車從左側靠得太近時,你會向右轉向並變換車道,當然,前提是右側沒有車。這個過程非常複雜,需要根據不同的感測器資訊組合進行不同的操作(向左或向右轉,加速或減速,煞車),因此需要將每個感測器連接到每個機器人機構。
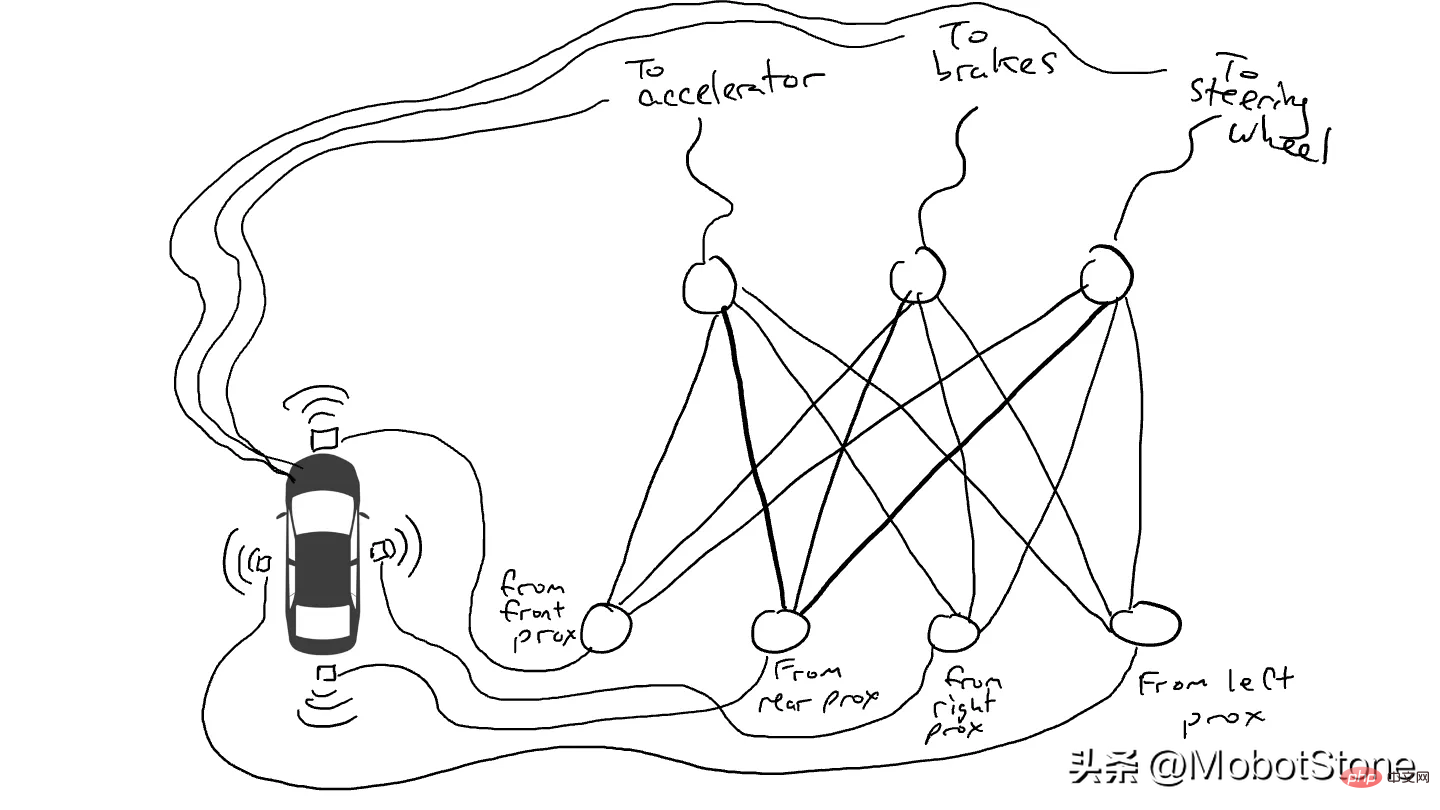
當你開車上路時會發生什麼事?電流從所有感測器流向所有機器人執行器,車輛同時向左轉、向右轉、加速和煞車。會形成一團亂麻。
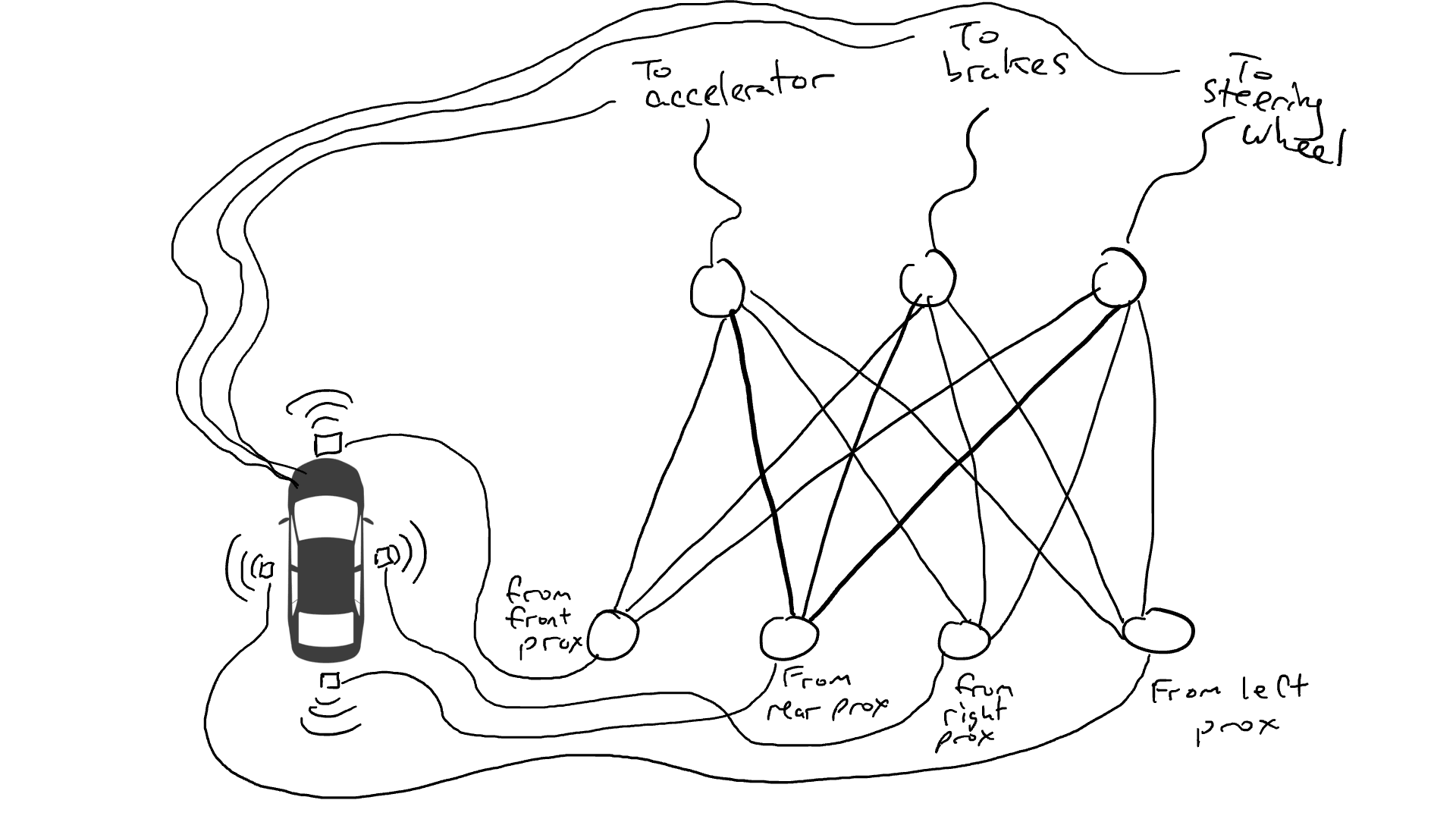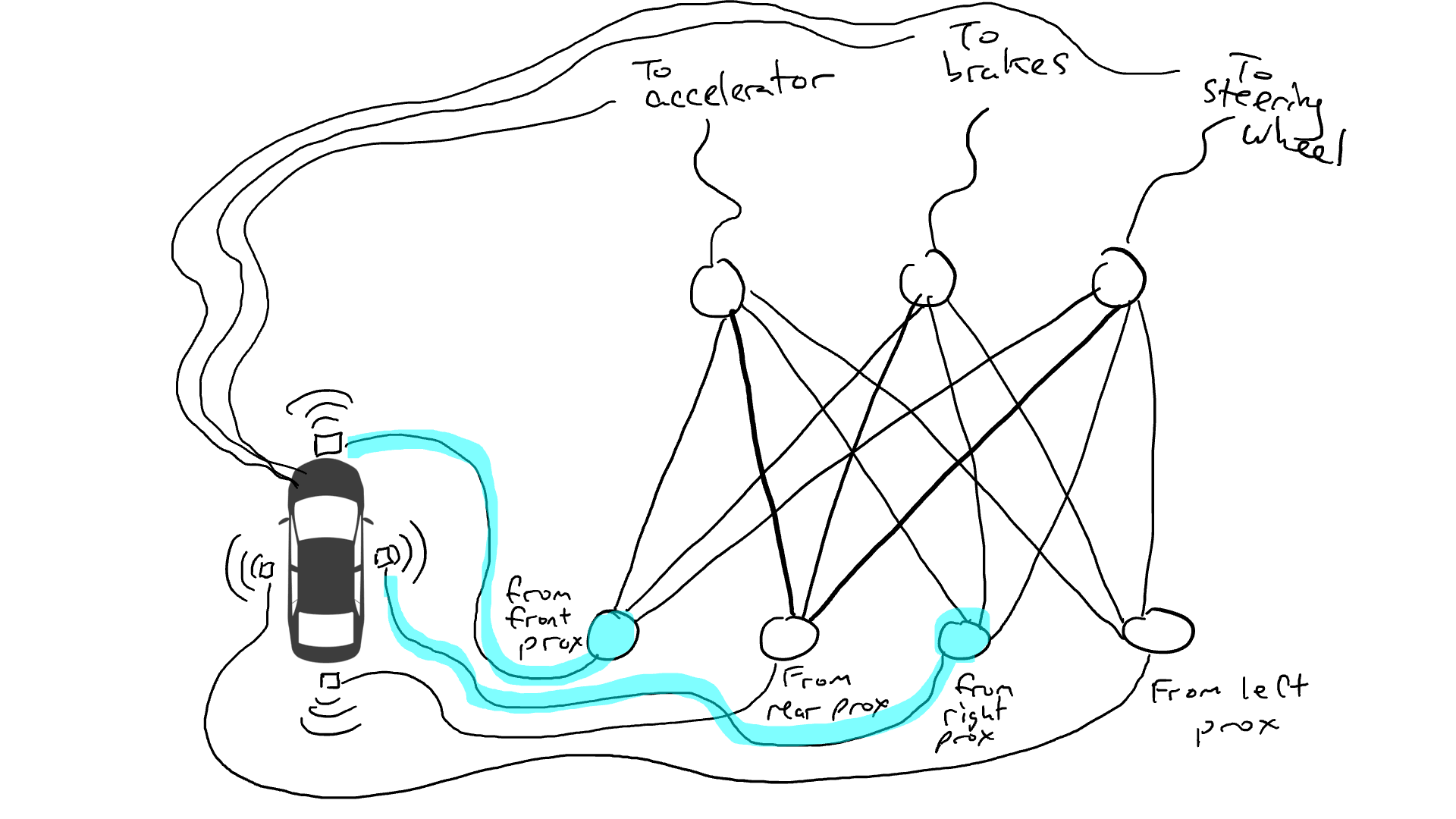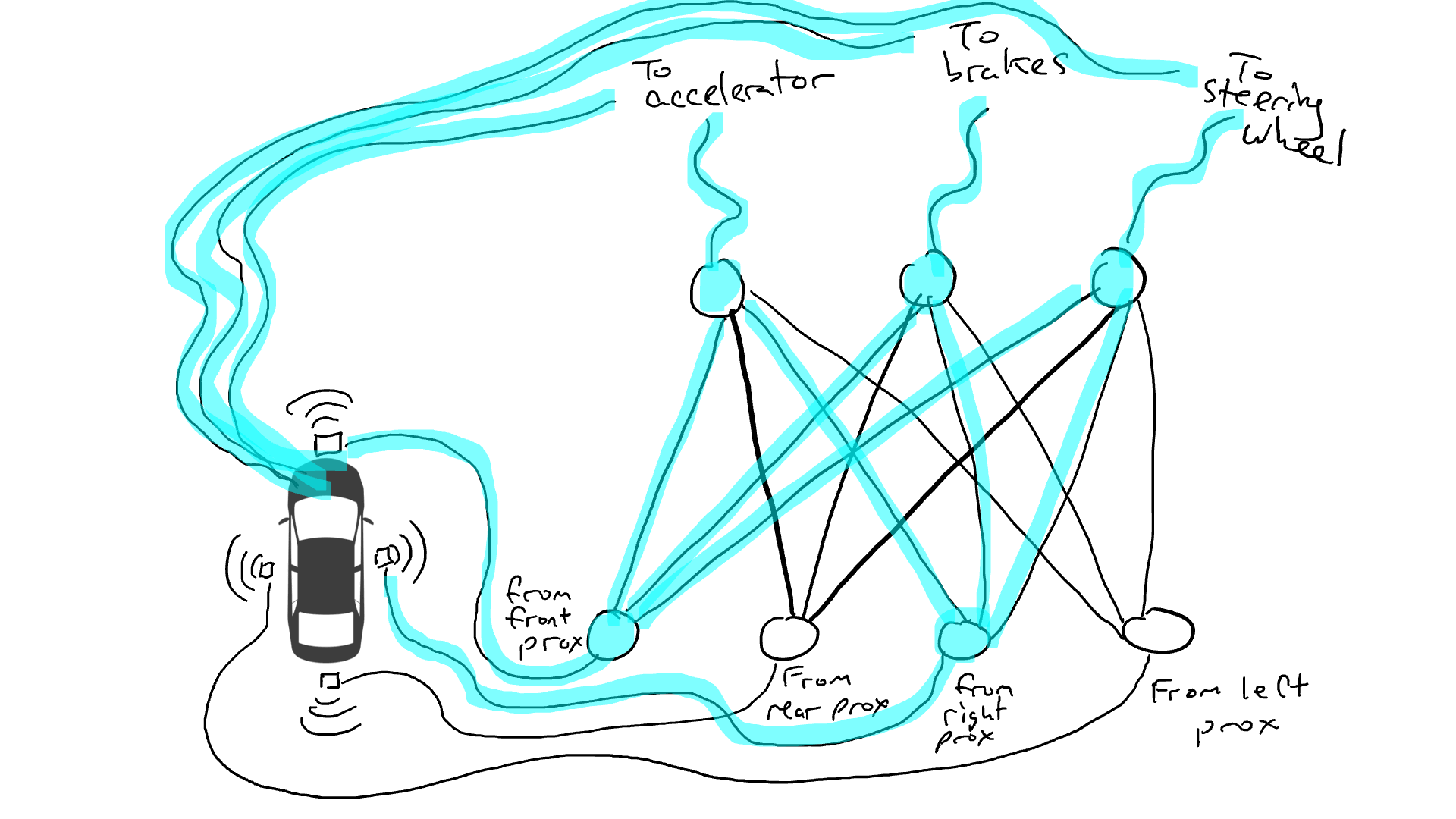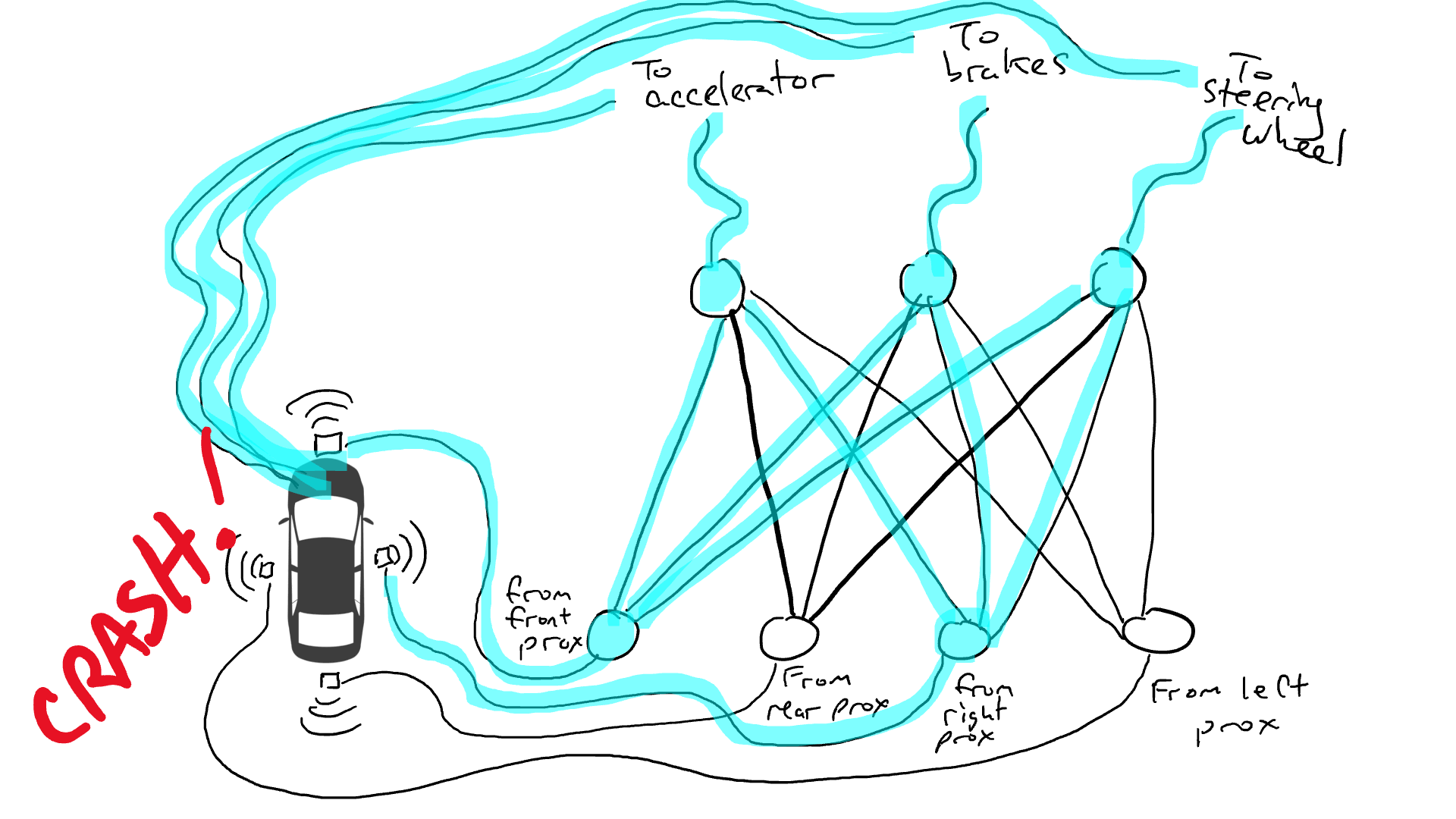
拿出電阻器並開始將它們放在電路的不同部分,以便電流可以在某些感測器和某些機械手臂之間更自由地流動。例如,我們希望電流能夠從前方接近感測器更自由地流向煞車而不是轉向機構。我們還安裝了稱為門的元件,直到足夠的電荷積累以觸發開關之前,電流才會停止流動(只有在前方和後方的接近感測器都報告高數字時才允許電流流動),或者僅在輸入電強度較低時向前發送電能(當前方接近感測器報告低值時向加速器發送更多電力)。
但是我們應該在哪裡放置這些電阻器和閘呢?我也不知道。隨機地將它們放在各個位置。然後再試一次。也許這次汽車開得更好,這意味著它有時會在數據顯示最好煞車和轉向等時煞車和轉向,但它並不是每次都正確。而有些事情它做得更糟(在數據顯示有時需要煞車時它加速了)。因此,我們不斷地隨機嘗試不同的電阻器和閘的組合。最終,我們會偶然發現一個足夠好的組合,那麼我們宣布成功。例如下面這個組合:
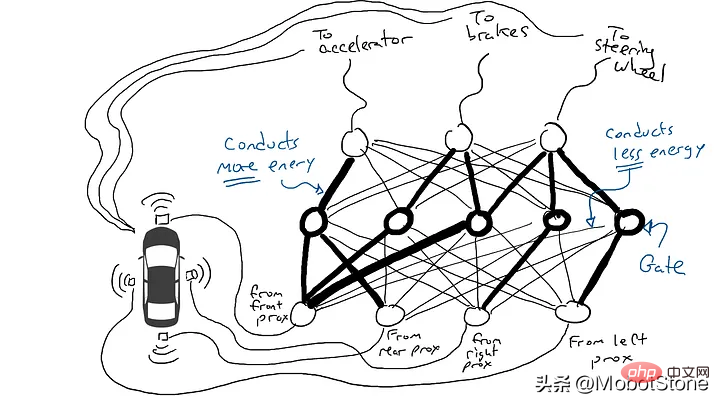
(實際上,我們不會添加或刪除門,但我們會修改門,使其可以以較低的能量從下方激活,或者需要更多的能量從下方輸出,或者只有在下方有非常少的能量時才釋放大量的能量。機器學習是純粹主義者,可能會對這種描述感到不舒服。技術上,這是透過調整門上的偏壓來完成的,這通常不會在此類圖示中顯示,但從電路隱喻的角度來看,它可以被認為是一個插入直接連接到電源的線纜,可以像所有其他線纜一樣進行修改。)
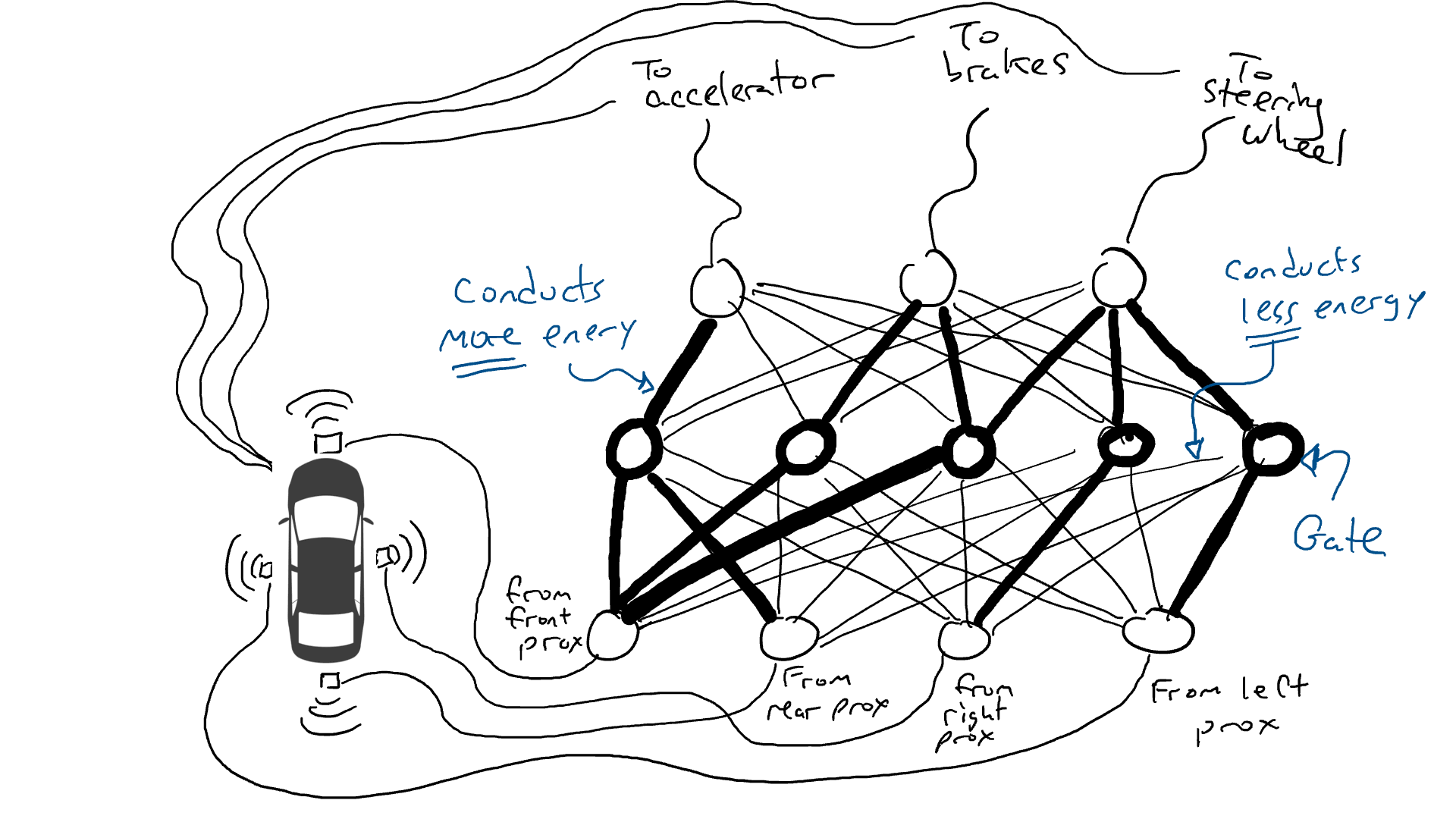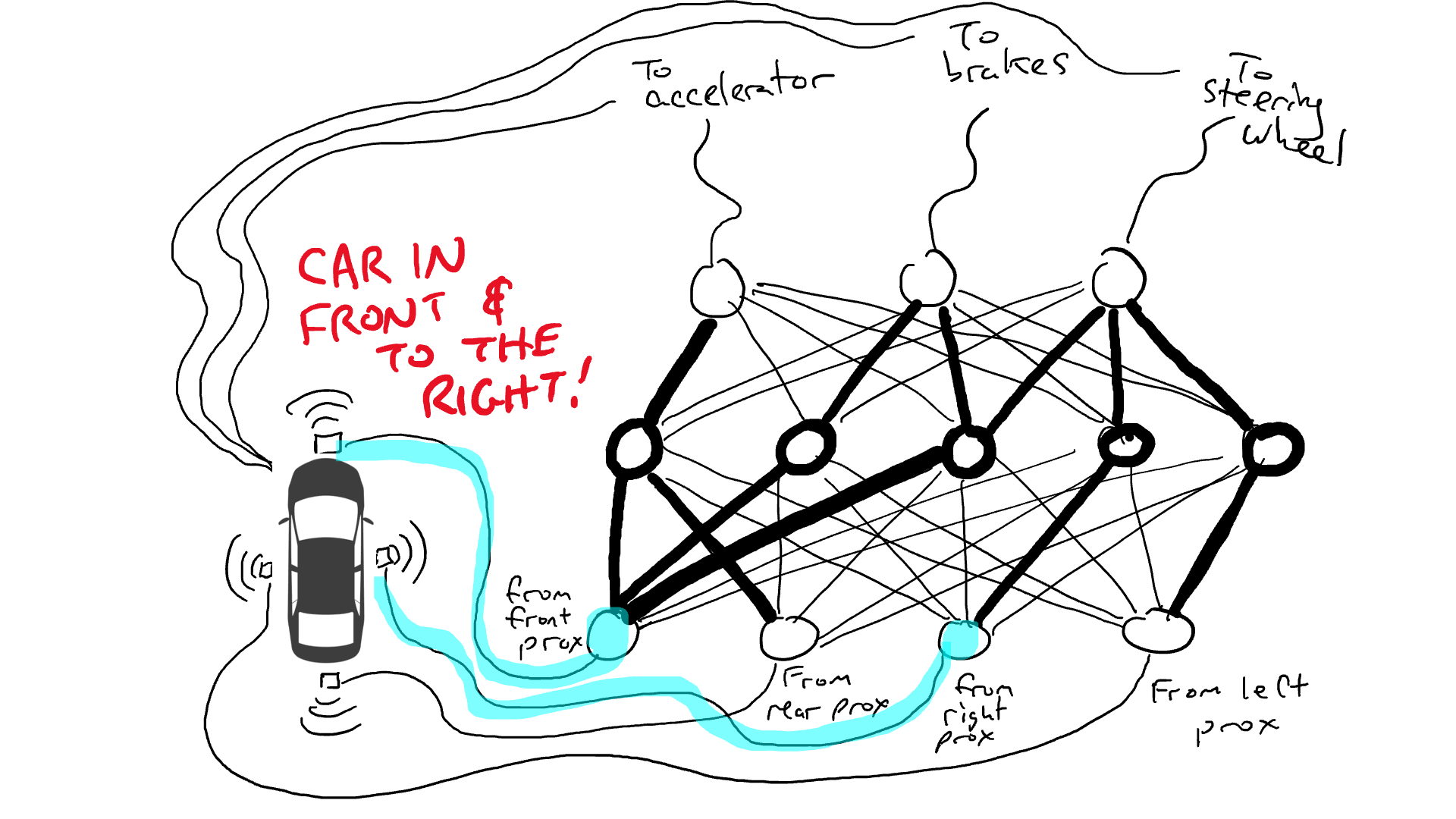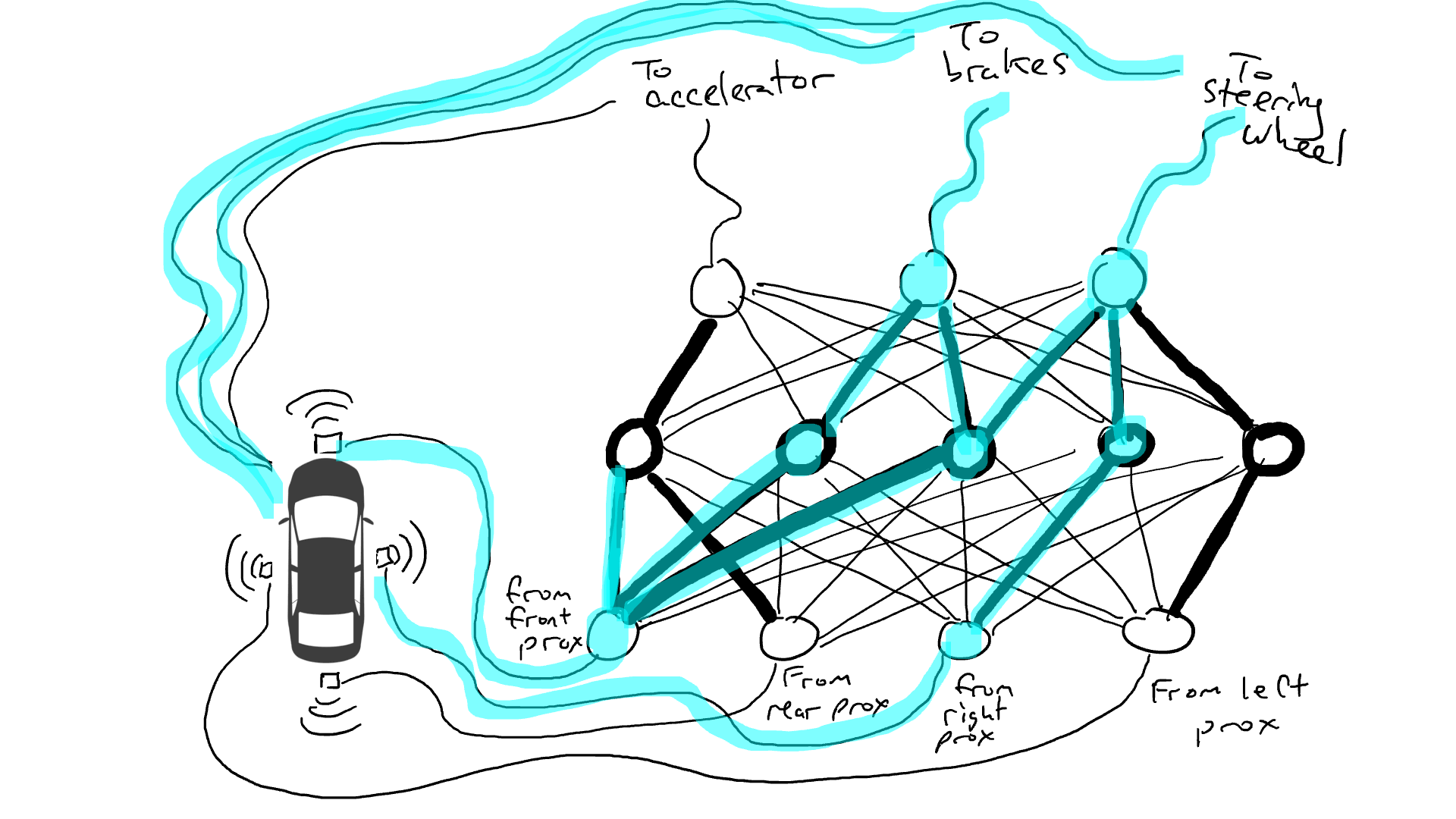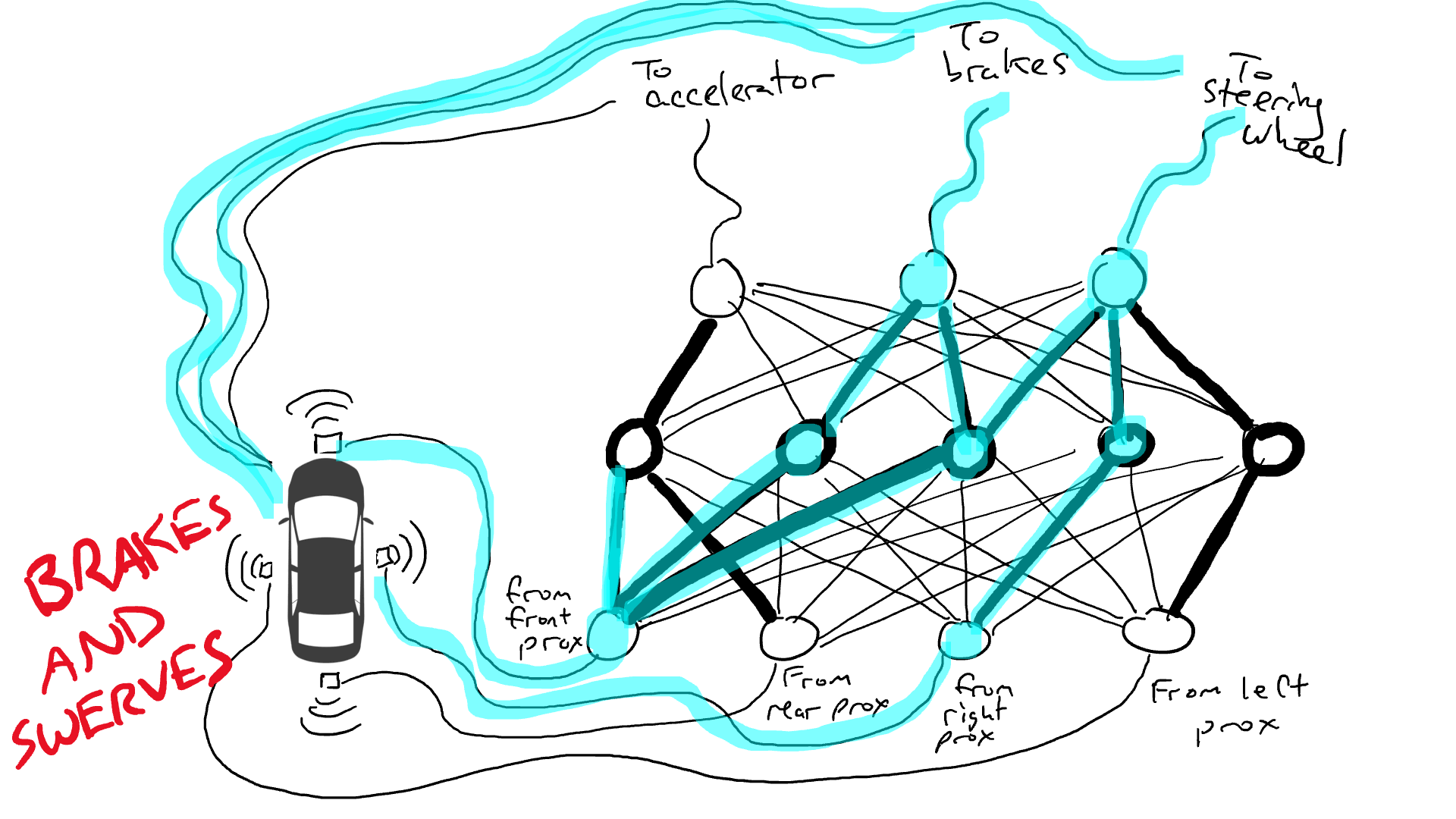
隨意嘗試並不好。一個名為反向傳播的演算法在改變電路配置方面具有相當不錯的猜測能力。演算法的細節並不重要,只需知道它會微調調整電路以使其行為更接近數據所建議的行為,經過成千上萬次的微調,最終可以獲得與數據相符的結果。
我們稱電阻器和閘為參數,因為實際上它們無所不在,而反向傳播演算法所做的是宣布每個電阻器更強或更弱。因此,如果我們知道電路的佈局和參數值,整個電路可以在其他汽車上複製。
以上是一種輕鬆且客觀介紹大模型方式,避免過度解讀的詳細內容。更多資訊請關注PHP中文網其他相關文章!