



線性迴歸
1.線性迴歸函數

#似然函數的定義:給定聯合樣本值X下關於(未知)參數
的函數
 的函數
的函數

似然函數:什麼樣本的參數跟我們的資料組合後面剛好是真實值
2.線性迴歸似然函數
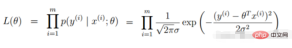
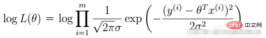
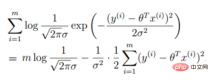
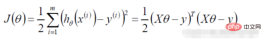
##邏輯迴歸是在線性迴歸的結果外加一層Sigmoid函數
 1.邏輯迴歸函數
1.邏輯迴歸函數
##2.邏輯迴歸似然函數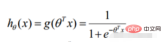
對數似然:
引入 轉變為梯度下降任務,邏輯迴歸目標函數
轉變為梯度下降任務,邏輯迴歸目標函數
梯度下降法解
def sigmoid(z):
return 1 / (1 + np.exp(-z))
預測函式def model(X, theta):
return sigmoid(np.dot(X, theta.T))目標函數
##
def cost(X, y, theta):
left = np.multiply(-y, np.log(model(X, theta)))
right = np.multiply(1 - y, np.log(1 - model(X, theta)))
return np.sum(left - right) / (len(X))
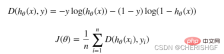
##lili 月函數
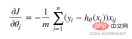
def gradient(X, y, theta):
grad = np.zeros(theta.shape)
error = (model(X, theta)- y).ravel()
for j in range(len(theta.ravel())): #for each parmeter
term = np.multiply(error, X[:,j])
grad[0, j] = np.sum(term) / len(X)
return grad梯度下降停止策略
STOP_ITER = 0
STOP_COST = 1
STOP_GRAD = 2
def stopCriterion(type, value, threshold):
# 设定三种不同的停止策略
if type == STOP_ITER: # 设定迭代次数
return value > threshold
elif type == STOP_COST: # 根据损失值停止
return abs(value[-1] - value[-2]) < threshold
elif type == STOP_GRAD: # 根据梯度变化停止
return np.linalg.norm(value) < threshold樣本重新洗牌
import numpy.random
#洗牌
def shuffleData(data):
np.random.shuffle(data)
cols = data.shape[1]
X = data[:, 0:cols-1]
y = data[:, cols-1:]
return X, y梯度下降求解
def descent(data, theta, batchSize, stopType, thresh, alpha):
# 梯度下降求解
init_time = time.time()
i = 0 # 迭代次数
k = 0 # batch
X, y = shuffleData(data)
grad = np.zeros(theta.shape) # 计算的梯度
costs = [cost(X, y, theta)] # 损失值
while True:
grad = gradient(X[k:k + batchSize], y[k:k + batchSize], theta)
k += batchSize # 取batch数量个数据
if k >= n:
k = 0
X, y = shuffleData(data) # 重新洗牌
theta = theta - alpha * grad # 参数更新
costs.append(cost(X, y, theta)) # 计算新的损失
i += 1
if stopType == STOP_ITER:
value = i
elif stopType == STOP_COST:
value = costs
elif stopType == STOP_GRAD:
value = grad
if stopCriterion(stopType, value, thresh): break
return theta, i - 1, costs, grad, time.time() - init_time完整程式碼
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import numpy.random
import time
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def model(X, theta):
return sigmoid(np.dot(X, theta.T))
def cost(X, y, theta):
left = np.multiply(-y, np.log(model(X, theta)))
right = np.multiply(1 - y, np.log(1 - model(X, theta)))
return np.sum(left - right) / (len(X))
def gradient(X, y, theta):
grad = np.zeros(theta.shape)
error = (model(X, theta) - y).ravel()
for j in range(len(theta.ravel())): # for each parmeter
term = np.multiply(error, X[:, j])
grad[0, j] = np.sum(term) / len(X)
return grad
STOP_ITER = 0
STOP_COST = 1
STOP_GRAD = 2
def stopCriterion(type, value, threshold):
# 设定三种不同的停止策略
if type == STOP_ITER: # 设定迭代次数
return value > threshold
elif type == STOP_COST: # 根据损失值停止
return abs(value[-1] - value[-2]) < threshold
elif type == STOP_GRAD: # 根据梯度变化停止
return np.linalg.norm(value) < threshold
# 洗牌
def shuffleData(data):
np.random.shuffle(data)
cols = data.shape[1]
X = data[:, 0:cols - 1]
y = data[:, cols - 1:]
return X, y
def descent(data, theta, batchSize, stopType, thresh, alpha):
# 梯度下降求解
init_time = time.time()
i = 0 # 迭代次数
k = 0 # batch
X, y = shuffleData(data)
grad = np.zeros(theta.shape) # 计算的梯度
costs = [cost(X, y, theta)] # 损失值
while True:
grad = gradient(X[k:k + batchSize], y[k:k + batchSize], theta)
k += batchSize # 取batch数量个数据
if k >= n:
k = 0
X, y = shuffleData(data) # 重新洗牌
theta = theta - alpha * grad # 参数更新
costs.append(cost(X, y, theta)) # 计算新的损失
i += 1
if stopType == STOP_ITER:
value = i
elif stopType == STOP_COST:
value = costs
elif stopType == STOP_GRAD:
value = grad
if stopCriterion(stopType, value, thresh): break
return theta, i - 1, costs, grad, time.time() - init_time
def runExpe(data, theta, batchSize, stopType, thresh, alpha):
# import pdb
# pdb.set_trace()
theta, iter, costs, grad, dur = descent(data, theta, batchSize, stopType, thresh, alpha)
name = "Original" if (data[:, 1] > 2).sum() > 1 else "Scaled"
name += " data - learning rate: {} - ".format(alpha)
if batchSize == n:
strDescType = "Gradient" # 批量梯度下降
elif batchSize == 1:
strDescType = "Stochastic" # 随机梯度下降
else:
strDescType = "Mini-batch ({})".format(batchSize) # 小批量梯度下降
name += strDescType + " descent - Stop: "
if stopType == STOP_ITER:
strStop = "{} iterations".format(thresh)
elif stopType == STOP_COST:
strStop = "costs change < {}".format(thresh)
else:
strStop = "gradient norm < {}".format(thresh)
name += strStop
print("***{}\nTheta: {} - Iter: {} - Last cost: {:03.2f} - Duration: {:03.2f}s".format(
name, theta, iter, costs[-1], dur))
fig, ax = plt.subplots(figsize=(12, 4))
ax.plot(np.arange(len(costs)), costs, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title(name.upper() + ' - Error vs. Iteration')
return theta
path = 'data' + os.sep + 'LogiReg_data.txt'
pdData = pd.read_csv(path, header=None, names=['Exam 1', 'Exam 2', 'Admitted'])
positive = pdData[pdData['Admitted'] == 1]
negative = pdData[pdData['Admitted'] == 0]
# 画图观察样本情况
fig, ax = plt.subplots(figsize=(10, 5))
ax.scatter(positive['Exam 1'], positive['Exam 2'], s=30, c='b', marker='o', label='Admitted')
ax.scatter(negative['Exam 1'], negative['Exam 2'], s=30, c='r', marker='x', label='Not Admitted')
ax.legend()
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')
pdData.insert(0, 'Ones', 1)
# 划分训练数据与标签
orig_data = pdData.values
cols = orig_data.shape[1]
X = orig_data[:, 0:cols - 1]
y = orig_data[:, cols - 1:cols]
# 设置初始参数0
theta = np.zeros([1, 3])
# 选择的梯度下降方法是基于所有样本的
n = 100
runExpe(orig_data, theta, n, STOP_ITER, thresh=5000, alpha=0.000001)
runExpe(orig_data, theta, n, STOP_COST, thresh=0.000001, alpha=0.001)
runExpe(orig_data, theta, n, STOP_GRAD, thresh=0.05, alpha=0.001)
runExpe(orig_data, theta, 1, STOP_ITER, thresh=5000, alpha=0.001)
runExpe(orig_data, theta, 1, STOP_ITER, thresh=15000, alpha=0.000002)
runExpe(orig_data, theta, 16, STOP_ITER, thresh=15000, alpha=0.001)
from sklearn import preprocessing as pp
# 数据预处理
scaled_data = orig_data.copy()
scaled_data[:, 1:3] = pp.scale(orig_data[:, 1:3])
runExpe(scaled_data, theta, n, STOP_ITER, thresh=5000, alpha=0.001)
runExpe(scaled_data, theta, n, STOP_GRAD, thresh=0.02, alpha=0.001)
theta = runExpe(scaled_data, theta, 1, STOP_GRAD, thresh=0.002 / 5, alpha=0.001)
runExpe(scaled_data, theta, 16, STOP_GRAD, thresh=0.002 * 2, alpha=0.001)
# 设定阈值
def predict(X, theta):
return [1 if x >= 0.5 else 0 for x in model(X, theta)]
# 计算精度
scaled_X = scaled_data[:, :3]
y = scaled_data[:, 3]
predictions = predict(scaled_X, theta)
correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y)]
accuracy = (sum(map(int, correct)) % len(correct))
print('accuracy = {0}%'.format(accuracy))邏輯迴歸的優缺點
優點
#形式簡單,模型的可解釋性非常好。從特徵的權重可以看到不同的特徵對最後結果的影響,某個特徵的權重值比較高,那麼這個特徵最後對結果的影響會比較大。
模型效果不錯。在工程上是可以接受的(作為baseline),如果特徵工程做的好,效果不會太差,並且特徵工程可以大家並行開發,大大加快開發的速度。
訓練速度較快。分類的時候,計算量僅僅只和特徵的數目相關。且邏輯迴歸的分散式最佳化sgd發展比較成熟,訓練的速度可以透過堆機器進一步提高,這樣我們可以在短時間內迭代好幾個版本的模型。
資源佔用小,尤其是記憶體。因為只需要儲存各個維度的特徵值。
方便輸出結果調整。邏輯迴歸可以很方便的得到最後的分類結果,因為輸出的是每個樣本的機率分數,我們可以很容易的對這些機率分數進行cutoff,也就是劃分閾值(大於某個閾值的是一類,小於某個閾值的是一類)。
缺點
準確率不是很高。因為形式非常的簡單(非常類似線性模型),很難去擬合資料的真實分佈。
很難處理資料不平衡的問題。舉個例子:如果我們對於一個正負樣本非常不平衡的問題例如正負樣本比 10000:1.我們把所有樣本都預測為正也能讓損失函數的值比較小。但是作為一個分類器,它對正負樣本的區分能力不會很好。
處理非線性資料較麻煩。邏輯迴歸在不引入其他方法的情況下,只能處理線性可分的數據,或者進一步說,處理二分類的問題 。
邏輯迴歸本身無法篩選特徵。有時候,我們會用gbdt來篩選特徵,然後再上邏輯回歸。
以上是python如何實現梯度下降求解邏輯迴歸的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 學習Python:2小時的每日學習是否足夠?Apr 18, 2025 am 12:22 AM
學習Python:2小時的每日學習是否足夠?Apr 18, 2025 am 12:22 AM每天學習Python兩個小時是否足夠?這取決於你的目標和學習方法。 1)制定清晰的學習計劃,2)選擇合適的學習資源和方法,3)動手實踐和復習鞏固,可以在這段時間內逐步掌握Python的基本知識和高級功能。
 Web開發的Python:關鍵應用程序Apr 18, 2025 am 12:20 AM
Web開發的Python:關鍵應用程序Apr 18, 2025 am 12:20 AMPython在Web開發中的關鍵應用包括使用Django和Flask框架、API開發、數據分析與可視化、機器學習與AI、以及性能優化。 1.Django和Flask框架:Django適合快速開發複雜應用,Flask適用於小型或高度自定義項目。 2.API開發:使用Flask或DjangoRESTFramework構建RESTfulAPI。 3.數據分析與可視化:利用Python處理數據並通過Web界面展示。 4.機器學習與AI:Python用於構建智能Web應用。 5.性能優化:通過異步編程、緩存和代碼優
 Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AM
Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AMPython在開發效率上優於C ,但C 在執行性能上更高。 1.Python的簡潔語法和豐富庫提高開發效率。 2.C 的編譯型特性和硬件控制提升執行性能。選擇時需根據項目需求權衡開發速度與執行效率。
 python在行動中:現實世界中的例子Apr 18, 2025 am 12:18 AM
python在行動中:現實世界中的例子Apr 18, 2025 am 12:18 AMPython在現實世界中的應用包括數據分析、Web開發、人工智能和自動化。 1)在數據分析中,Python使用Pandas和Matplotlib處理和可視化數據。 2)Web開發中,Django和Flask框架簡化了Web應用的創建。 3)人工智能領域,TensorFlow和PyTorch用於構建和訓練模型。 4)自動化方面,Python腳本可用於復製文件等任務。
 Python的主要用途:綜合概述Apr 18, 2025 am 12:18 AM
Python的主要用途:綜合概述Apr 18, 2025 am 12:18 AMPython在數據科學、Web開發和自動化腳本領域廣泛應用。 1)在數據科學中,Python通過NumPy、Pandas等庫簡化數據處理和分析。 2)在Web開發中,Django和Flask框架使開發者能快速構建應用。 3)在自動化腳本中,Python的簡潔性和標準庫使其成為理想選擇。
 Python的主要目的:靈活性和易用性Apr 17, 2025 am 12:14 AM
Python的主要目的:靈活性和易用性Apr 17, 2025 am 12:14 AMPython的靈活性體現在多範式支持和動態類型系統,易用性則源於語法簡潔和豐富的標準庫。 1.靈活性:支持面向對象、函數式和過程式編程,動態類型系統提高開發效率。 2.易用性:語法接近自然語言,標準庫涵蓋廣泛功能,簡化開發過程。
 Python:多功能編程的力量Apr 17, 2025 am 12:09 AM
Python:多功能編程的力量Apr 17, 2025 am 12:09 AMPython因其簡潔與強大而備受青睞,適用於從初學者到高級開發者的各種需求。其多功能性體現在:1)易學易用,語法簡單;2)豐富的庫和框架,如NumPy、Pandas等;3)跨平台支持,可在多種操作系統上運行;4)適合腳本和自動化任務,提升工作效率。
 每天2小時學習Python:實用指南Apr 17, 2025 am 12:05 AM
每天2小時學習Python:實用指南Apr 17, 2025 am 12:05 AM可以,在每天花費兩個小時的時間內學會Python。 1.制定合理的學習計劃,2.選擇合適的學習資源,3.通過實踐鞏固所學知識,這些步驟能幫助你在短時間內掌握Python。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

記事本++7.3.1
好用且免費的程式碼編輯器

