



python中jieba庫(中文分詞庫)使用安裝教學
介紹
jieba是優秀的中文分詞第三方函式庫。由於中文文本之間每個漢字都是連續書寫的,我們需要透過特定的手段來獲得其中的每個單詞,這種手段就叫分詞。而jieba是Python計算生態中非常優秀的中文分詞第三方函式庫,需要透過安裝來使用它。
jieba函式庫提供了三種分詞模式,但實際上要達到分詞效果只要掌握一個函數就夠了,非常的簡單有效。
安裝第三方函式庫需要使用pip工具,在命令列下執行安裝命令(不是IDLE)。注意:需要將Python目錄和其目錄下的Scripts目錄加到環境變數中。
使用指令pip install jieba安裝第三方函式庫,安裝之後會提示successfully installed,告知是否安裝成功。
分詞原理:簡單來說,jieba庫是透過中文詞庫的方式來辨識分詞的。它首先利用一個中文詞庫,透過詞庫計算漢字之間構成詞語的關聯機率,所以透過計算漢字之間的機率,就可以形成分詞的結果。當然,除了jieba自帶的中文詞庫,使用者也可以在其中增加自訂的詞組,從而使jieba的分詞更接近某些特定領域的使用。
jieba是python的一個中文分詞庫,下面介紹它的使用方法。
安裝
方式1: pip install jieba 方式2: 先下载 http://pypi.python.org/pypi/jieba/ 然后解压,运行 python setup.py install
功能
分詞
#jieba常用的三種模式:
- ##精確模式,試著將句子最精確地切開,適合文本分析;
- 全模式,把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義;
- 搜尋引擎模式,在精確模式的基礎上,對長詞再次切分,提高召回率,適合用於搜尋引擎分詞。
jieba.cut 和 jieba.cut_for_search 方法進行分詞,兩者所回傳的結構都是可迭代的generator ,可使用for 循環來獲得分詞後得到的每一個詞語(unicode),或直接使用 jieba.lcut 以及 jieba.lcut_for_search 返回list。
jieba.Tokenizer(dictionary=DEFAULT_DICT) :使用此方法可自訂分詞器,並可同時使用不同的字典。 jieba.dt 為預設分詞器,所有全域分詞相關函數都是該分詞器的對應。
jieba.cut 和 jieba.lcut 可接受的參數如下:
- 需要分詞的字串(unicode或UTF-8 字串、GBK 字串)
- cut_all:是否使用全模式,預設值為
False
- HMM:用來控制是否使用HMM 模型,預設值為
True
jieba.cut_for_search 和 jieba.lcut_for_search 接受2 個參數:
- 需要分詞的字串(unicode 或UTF-8 字串、GBK 字串)
- HMM:用來控制是否使用HMM 模型,預設值為
True
# 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']自訂字典#開發者可以指定自己自訂的字典,以便包含 jieba 字庫裡沒有的字。 用法: jieba.load_userdict(dict_path)
大學課程下面比較下精確匹配、全匹配和使用自訂字典的區別:深度學習
import jieba
test_sent = """
数学是一门基础性的大学课程,深度学习是基于数学的,尤其是线性代数课程
"""
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学', '课程', ',', '深度',
# '学习', '是', '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
words = jieba.cut(test_sent, cut_all=True)
print(list(words))
# ['\n', '数学', '是', '一门', '基础', '基础性', '的', '大学', '课程', '', '', '深度',
# '学习', '是', '基于', '数学', '的', '', '', '尤其', '是', '线性', '线性代数', '代数', '课程', '\n']
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
jieba.add_word("尤其是")
jieba.add_word("线性代数课程")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其是', '线性代数课程', '\n']從上面的例子可以看出,使用自訂字典與使用預設字典的差異。 jieba.add_word():在自訂字典中添加詞語關鍵字提取可以基於TF-IDF 演算法進行關鍵字提取,也可以基於TextRank 演算法。 TF-IDF 演算法與 elasticsearch 中使用的演算法是一樣的。 使用jieba.analyse.extract_tags() 函數進行關鍵字提取,其參數如下:jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=() )
- sentence 為待擷取的文字
- #topK 為傳回幾個TF/IDF 權重最大的關鍵字,預設值為20
- withWeight 為是否一併回傳關鍵字權重值,預設值為False
- allowPOS 僅包含指定詞性的詞,預設值為空,即不篩選
- jieba.analyse.TFIDF(idf_path=None) 新建TFIDF 實例,idf_path 為IDF 頻率檔
也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件。
基于 TF-IDF 算法和TextRank算法的关键词抽取:
import jieba.analyse file = "sanguo.txt" topK = 12 content = open(file, 'rb').read() # 使用tf-idf算法提取关键词 tags = jieba.analyse.extract_tags(content, topK=topK) print(tags) # ['玄德', '程远志', '张角', '云长', '张飞', '黄巾', '封谞', '刘焉', '邓茂', '邹靖', '姓名', '招军'] # 使用textrank算法提取关键词 tags2 = jieba.analyse.textrank(content, topK=topK) # withWeight=True:将权重值一起返回 tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True) print(tags) # [('玄德', 0.1038549799467099), ('程远志', 0.07787459004363208), ('张角', 0.0722532891360849), # ('云长', 0.07048801593691037), ('张飞', 0.060972692853113214), ('黄巾', 0.058227157790330185), # ('封谞', 0.0563904127495283), ('刘焉', 0.05470798376886792), ('邓茂', 0.04917692565566038), # ('邹靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招军', 0.04182041076757075)]
上面的代码是读取文件,提取出现频率最高的前12个词。
词性标注
词性标注主要是标记文本分词后每个词的词性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默认模式
seg_list = pseg.cut("今天哪里都没去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默认模式的输出结果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早饭 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早饭了",use_paddle=True)
"""
使用 paddle 模式的输出结果是:
我 r
今天 TIME
吃 v
早饭 n
了 xc
"""paddle模式的词性对照表如下:
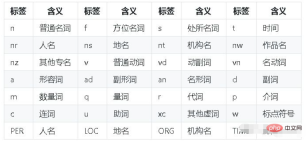
补充:Python中文分词库——jieba的用法
.使用说明
jieba分词有三种模式:精确模式、全模式和搜索引擎模式。
简单说,精确模式就是把一段文本精确的切分成若干个中文单词,若干个中文单词之间经过组合就精确的还原为之前的文本,其中不存在冗余单词。精确模式是最常用的分词模式。
进一步jieba又提供了全模式,全模式是把一段中文文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式或者有不同的角度来切分变成不同的词语,那么jieba在全模式下把这样的不同的组合都挖掘出来,所以如果用全模式来进行分词,分词的信息组合起来并不是精确的原有文本,会有很多的冗余。
而搜索引擎模式更加智能,它是在精确模式的基础上对长词进行再次切分,将长的词语变成更短的词语,进而适合搜索引擎对短词语的索引和搜索,在一些特定场合用的比较多。
jieba库提供的常用函数:
jieba.lcut(s)
精确模式,能够对一个字符串精确地返回分词结果,而分词的结果使用列表形式来组织。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家")
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 2.489 seconds.
Prefix dict has been built successfully.
['中国', '是', '一个', '伟大', '的', '国家']jieba.lcut(s,cut_all=True)
全模式,能够返回一个列表类型的分词结果,但结果存在冗余。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
['中国', '国是', '一个', '伟大', '的', '国家']jieba.lcut_for_search(s)
搜索引擎模式,能够返回一个列表类型的分词结果,也存在冗余。例如:
>>> import jieba
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']jieba.add_word(w)
向分词词库添加新词w
最重要的就是jieba.lcut(s)函数,完成精确的中文分词。
以上是如何用Python中的jieba函式庫?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 如何使用numpy創建多維數組?Apr 29, 2025 am 12:27 AM
如何使用numpy創建多維數組?Apr 29, 2025 am 12:27 AM使用NumPy創建多維數組可以通過以下步驟實現:1)使用numpy.array()函數創建數組,例如np.array([[1,2,3],[4,5,6]])創建2D數組;2)使用np.zeros(),np.ones(),np.random.random()等函數創建特定值填充的數組;3)理解數組的shape和size屬性,確保子數組長度一致,避免錯誤;4)使用np.reshape()函數改變數組形狀;5)注意內存使用,確保代碼清晰高效。
 說明Numpy陣列中'廣播”的概念。Apr 29, 2025 am 12:23 AM
說明Numpy陣列中'廣播”的概念。Apr 29, 2025 am 12:23 AM播放innumpyisamethodtoperformoperationsonArraySofDifferentsHapesbyAutapityallate AligningThem.itSimplifififiesCode,增強可讀性,和Boostsperformance.Shere'shore'showitworks:1)較小的ArraySaraySaraysAraySaraySaraySaraySarePaddedDedWiteWithOnestOmatchDimentions.2)
 說明如何在列表,Array.Array和用於數據存儲的Numpy數組之間進行選擇。Apr 29, 2025 am 12:20 AM
說明如何在列表,Array.Array和用於數據存儲的Numpy數組之間進行選擇。Apr 29, 2025 am 12:20 AMforpythondataTastorage,choselistsforflexibilityWithMixedDatatypes,array.ArrayFormeMory-effficityHomogeneousnumericalData,andnumpyArraysForAdvancedNumericalComputing.listsareversareversareversareversArversatilebutlessEbutlesseftlesseftlesseftlessforefforefforefforefforefforefforefforefforefforlargenumerdataSets; arrayoffray.array.array.array.array.array.ersersamiddreddregro
 舉一個場景的示例,其中使用Python列表比使用數組更合適。Apr 29, 2025 am 12:17 AM
舉一個場景的示例,其中使用Python列表比使用數組更合適。Apr 29, 2025 am 12:17 AMPythonlistsarebetterthanarraysformanagingdiversedatatypes.1)Listscanholdelementsofdifferenttypes,2)theyaredynamic,allowingeasyadditionsandremovals,3)theyofferintuitiveoperationslikeslicing,but4)theyarelessmemory-efficientandslowerforlargedatasets.
 您如何在Python數組中訪問元素?Apr 29, 2025 am 12:11 AM
您如何在Python數組中訪問元素?Apr 29, 2025 am 12:11 AMtoAccesselementsInapyThonArray,useIndIndexing:my_array [2] accessEsthethEthErlement,returning.3.pythonosezero opitedEndexing.1)usepositiveandnegativeIndexing:my_list [0] fortefirstElment,fortefirstelement,my_list,my_list [-1] fornelast.2] forselast.2)
 Python中有可能理解嗎?如果是,為什麼以及如果不是為什麼?Apr 28, 2025 pm 04:34 PM
Python中有可能理解嗎?如果是,為什麼以及如果不是為什麼?Apr 28, 2025 pm 04:34 PM文章討論了由於語法歧義而導致的Python中元組理解的不可能。建議使用tuple()與發電機表達式使用tuple()有效地創建元組。 (159個字符)
 Python中的模塊和包裝是什麼?Apr 28, 2025 pm 04:33 PM
Python中的模塊和包裝是什麼?Apr 28, 2025 pm 04:33 PM本文解釋了Python中的模塊和包裝,它們的差異和用法。模塊是單個文件,而軟件包是帶有__init__.py文件的目錄,在層次上組織相關模塊。
 Python中的Docstring是什麼?Apr 28, 2025 pm 04:30 PM
Python中的Docstring是什麼?Apr 28, 2025 pm 04:30 PM文章討論了Python中的Docstrings,其用法和收益。主要問題:Docstrings對於代碼文檔和可訪問性的重要性。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

SublimeText3漢化版
中文版,非常好用

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

