
飛槳面向異構場景下的自動並行設計與實踐

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-09 15:28:181052瀏覽

一、背景介紹
在介紹自動並行之前,我們先思考為什麼需要自動並行?一方面現在有著不同的模型結構,另一方面還有各種平行策略,兩者之間的一般是多對多的映射關係。假設我們能實現一個統一的模型結構來滿足各種任務需求,那麼我們的平行策略是不是在這種統一的模型結構上實現收斂?
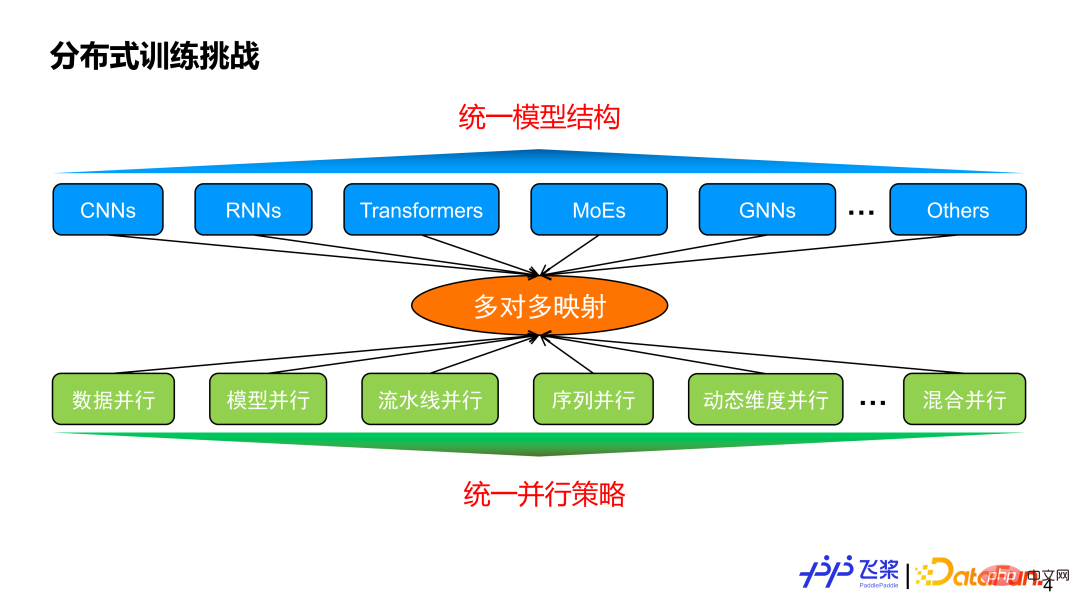
#答案是否定的,因為平行策略不只跟模型結構相關,也跟模型的規模以及實際使用的機器資源息息相關。這就體現出自動並行的價值,它的目標是:用戶給定一個模型和所使用的機器資源後,能夠自動地幫用戶選擇一個比較好或最優的並行策略來高效執行。
這裡羅列了個人感興趣的一些工作,不一定完整,想跟大家討論一下自動並行的現狀和歷史。大概分了幾個維度:第一個維度是自動並行的程度,分為全自動和半自動;第二個維度是並行粒度,分別是針對每個Layer 來提供並行策略,或者是針對每一個算子或張量來提供平行策略;第三個是表示能力,這裡簡化為SPMD(Single Program Multiple Data)並行和Pipeline 並行兩大類;第四個是特色,這裡列出了個人覺得相關工作比較有特色的地方;第五個是支援硬件,主要寫出相關工作所支援最大規模的硬體類型和數量。其中,標紅部分主要是對飛槳自動並行研發有啟發性的點。
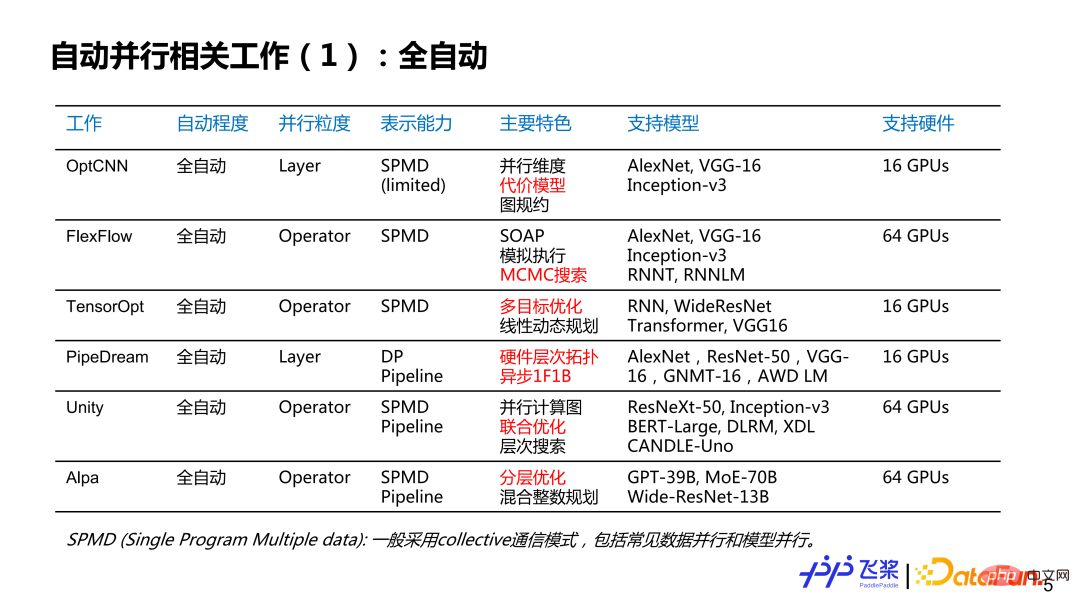
#對於全自動並行來說,我們可以看到並行粒度,是由粗粒度到細粒度的發展過程;表示能力是從比較簡單的SPMD 到非常通用的SPMD 與Pipeline 的方式;支持的模型是從簡單的CNN 到RNN 再到比較複雜的GPT;雖然支援多機多卡,但整體規模不是特別大。
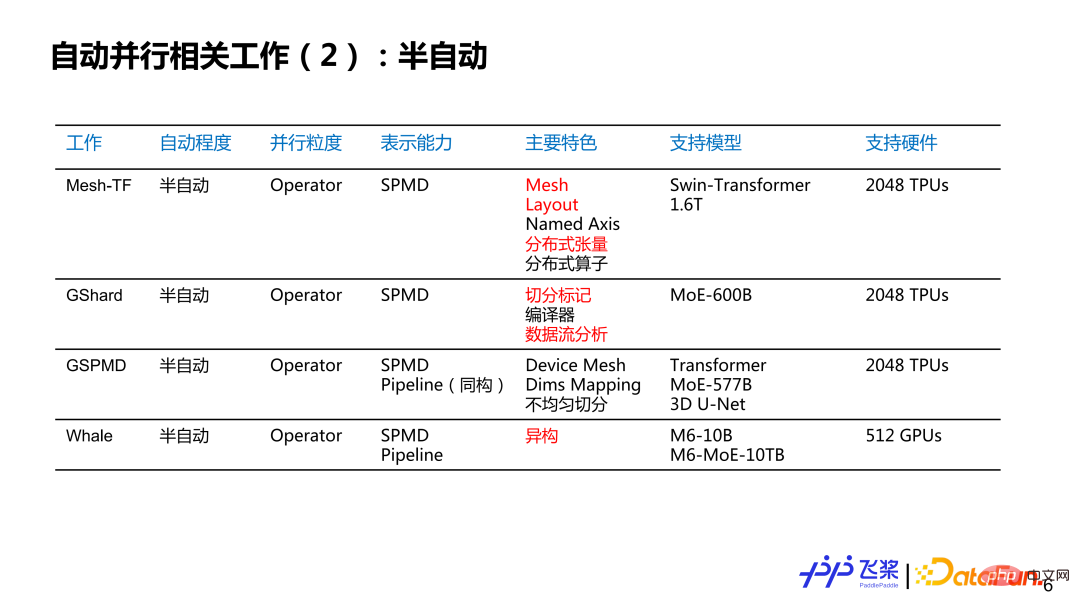
#對於半自動並行來說,並行粒度基本上都是以算符為粒度的,而表示能力從簡單的 SPMD 到完備的SPMD 加上Pipeline 的並行策略,模型支援規模達到千億和萬億量級,所使用的硬體數量達到千卡量級。
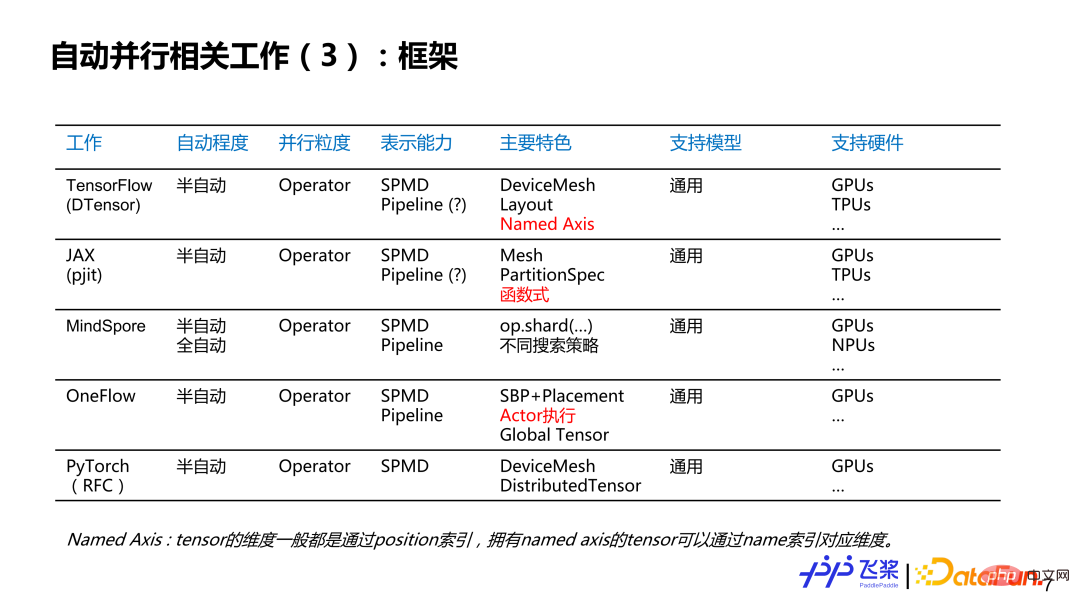
#再從框架角度來看,我們可以看到現有的框架基本上已經支援或計劃支援半自動這種模式,而並行粒度也發展到算子粒度,表示能力基本上都採用SPMD 加上Pipeline 的完備表示,都面向各種模型和各種硬體。

#這裡總結個人的一些思考:
#① 第一點,分散式策略在底層表示上逐漸統一。
② 第二點,半自動會逐漸成為框架的一種分散式程式設計範式,而全自動會結合特定的場景和經驗規則去探索落地。
#③ 第三點,實現一個極致端到端效能,需要採用平行策略與最佳化策略聯合調優來實現。
二、架構設計
一般完整分散式訓練包含 4 個具體的流程。首先是模型切分,無論是手動並行或自動並行都需要將模型切分為多個可以並行的任務;其次是資源獲取,可以透過自己搭建或從平台申請來準備好我們訓練所需的設備資源;然後是任務放置(或任務映射),也就是將切分後的任務放置到對應資源上;最後是分散式執行,就是各個設備上的任務並行執行,並透過訊息通訊來進行同步和互動。
現在一些主流的解決方案存在一些問題:一方面可能只考慮分散式訓練中的部分流程,或只專注於部分流程;第二個就是過度依賴專家的經驗規則,例如模型切分和資源分配;最後是在整個訓練的過程中,缺乏對任務和資源的感知能力。
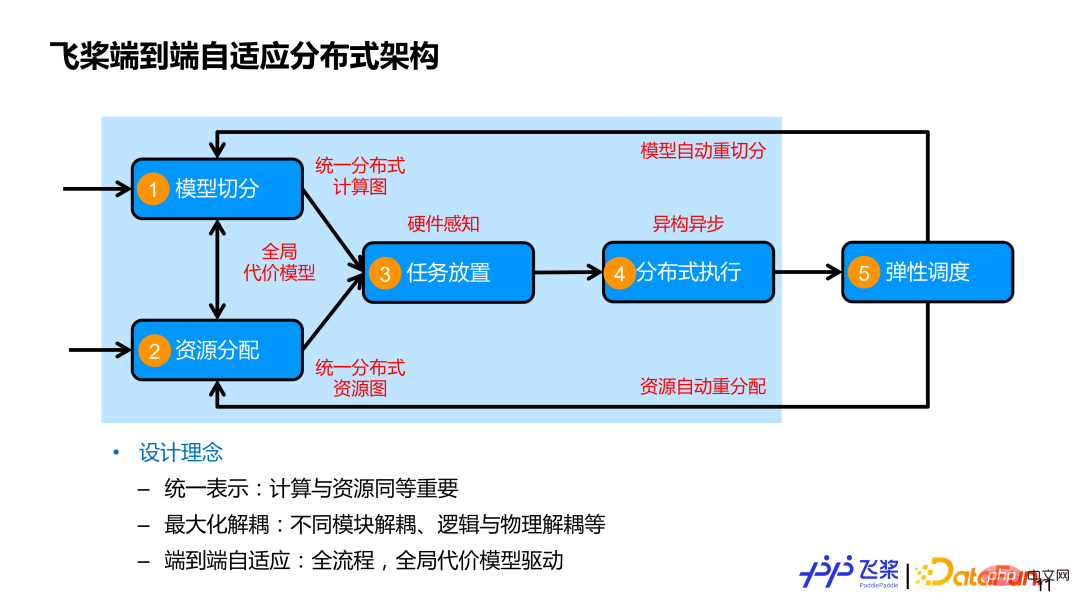
而飛槳所設計的端對端自適應分散式訓練架構,在全面考慮4 個流程基礎上,又加入第五個流程,即彈性調度。我們核心設計理念主要包括這 3 點:
第一,計算和資源統一表示,並且計算和資源同等重要。往往大家比較關心怎麼切分模型,但是對資源關注度比較少。我們一方面用統一的分散式計算圖來表示各種各樣的平行策略;另一方面,我們用統一的分散式資源圖來建模各種各樣的機器資源,既能表示同構的,又能表示異質的資源連結關係,也包括資源本身的運算和儲存能力。
第二,最大化解耦,除了模組之間解耦外,我們還將邏輯切分跟物理放置以及分佈式執行等進行解耦,這樣能夠更好地實現不同模型在不同集群資源高效執行。
第三,端到端自適應,涵蓋分散式訓練所涉及的全面流程,並採用一個全局的代表模型來驅動並行策略或資源放置的自適應決策,來盡可能取代人工定制化決策。 上圖淺藍色框住的部分就是本次報告所介紹的自動並行相關工作。
1、統一分散式計算圖
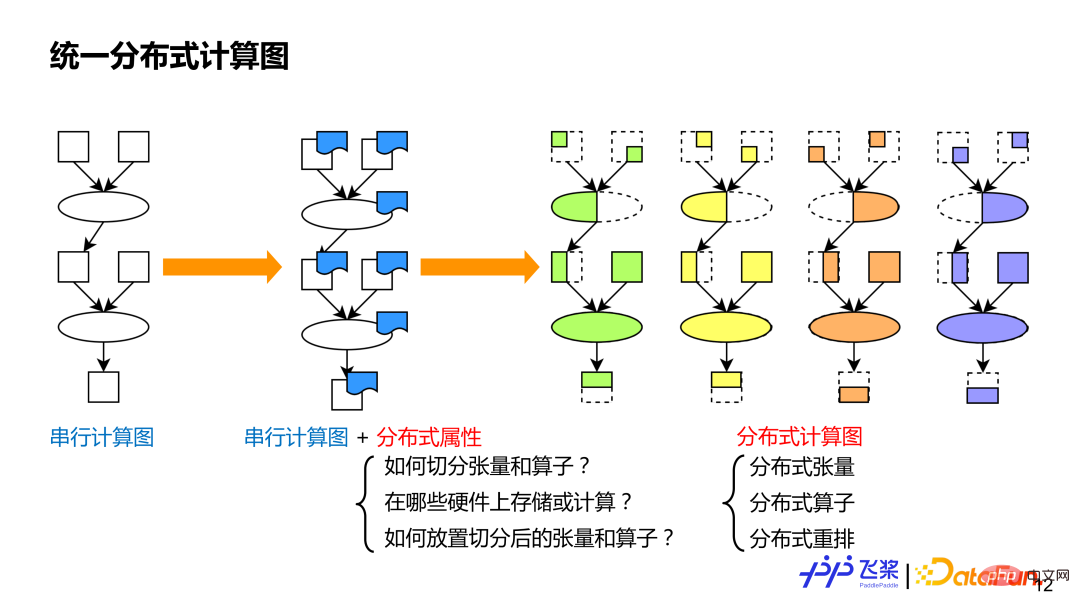
##首先是統一的分散式計算圖。統一目的是便於我們採用統一方式來表示現有的各種各樣的平行策略,這樣利於做自動化處理。眾所周知,串行計算圖能表示各種各樣的模型,類似地,我們在串行計算圖的基礎上,對每個算子和張量加上分佈式屬性來作為分佈式計算圖,這種細粒度方式能表示現有並行策略,且語意會更豐富且通用,還能表示新的平行策略。分散式計算圖中的分散式屬性主要包括三個面向資訊:1)需要表示張量怎麼切分或算子怎麼切分;2)需要表示在哪些資源進行分散式計算;3)如何將切分後的張量或算子會對應到資源上。比較串列計算圖,分散式計算圖有3 個基礎組成概念:分散式張量,類似串列的張量;分散式算子,類似串列的算符;分散式重排,分佈式計算圖獨有。
(1)分散式張量
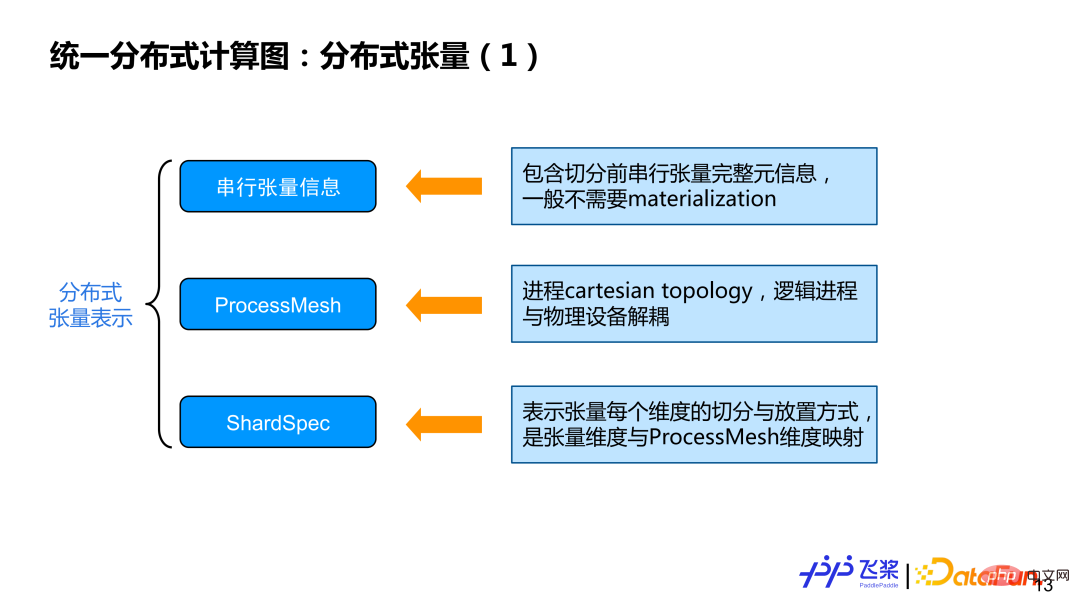
#首先,介紹分散式張量所包含的三個面向資訊:
#① 串列張量資訊:######### ####主要包含張量shape、dtype 等一些元信息,一般實際計算不需要對串行張量進行實例化。 ##########② ProcessMesh:程式的cartesion topology 表示,有別於DeviceMesh,我們之所以採用ProcessMesh,主要希望邏輯的進程跟著物理設備進行一個解耦,這樣便於做更有效率任務映射。
③ ShardSpec:#用來表示序列張量每個維度用ProcessMesh 哪個維度進行切分,具體可看下圖範例。
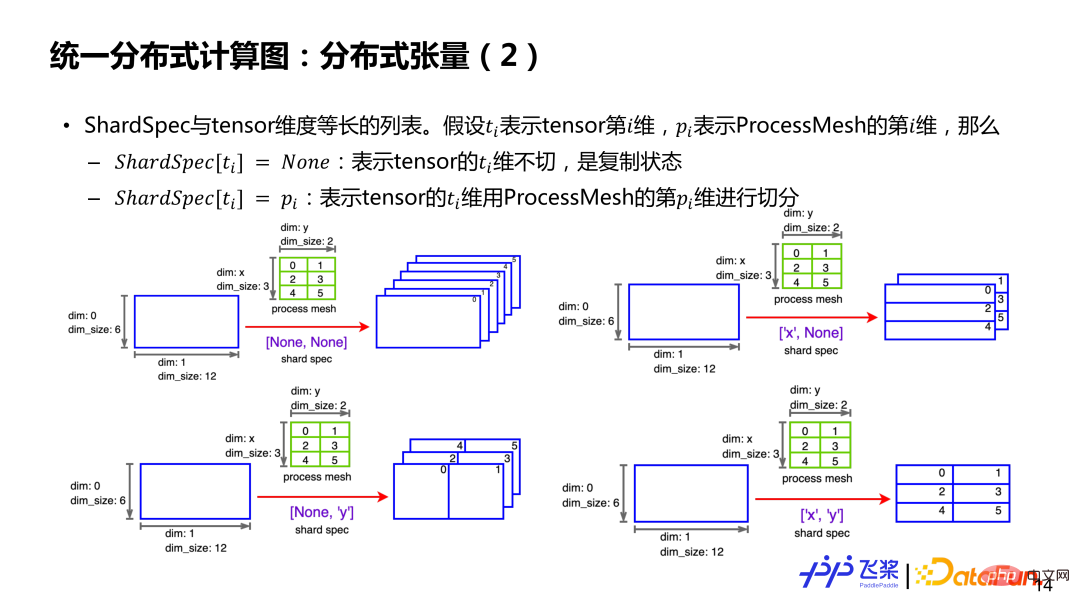
假如有一個二維的6*12 張量和一個3*2 的ProcessMesh(第一個維度是x,第二維是y,元素是進程ID)。如果 ShardSpec 是 [None,None],就表示張量第 0 維和第 2 維都切分,每個行程上都有一個全量張量。如果ShardSpec是['x', 'y'],表示用ProcessMesh 的x 軸去切張量第0 維,用ProcessMesh 的y 軸去切張量第1 維,這樣每個進程都有一個2*6大小的Local 張量。總之,透過 ProcessMesh 和 ShardSpec 以及張量未切分前的串列訊息,就能夠表示一個張量在相關進程上切分情況。
(2)分散式運算子
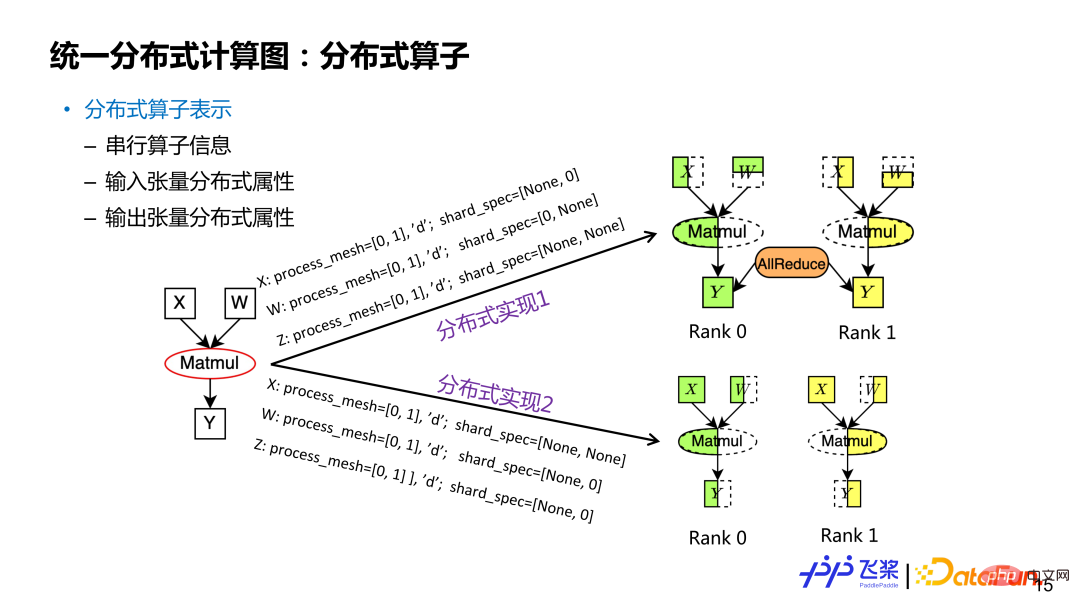
#分散式運算子表示是基於分佈式張量的,包括串行算子信息,輸入和輸出張量的分佈式屬性。類似一個分散式張量可能對應多種切分方式,分散式算符裡面的分佈式屬性不一樣,對應著不同切分。以矩形乘 Y=X*W 算符為例,如果輸入和輸出分佈式屬性不同,就對應不同的分散式算子實作(分佈屬性包括 ProcessMesh 和 ShardSpec)。對於分散式算子來說,其輸入和輸出張量的 ProcessMesh 相同。
(3)分散式重排
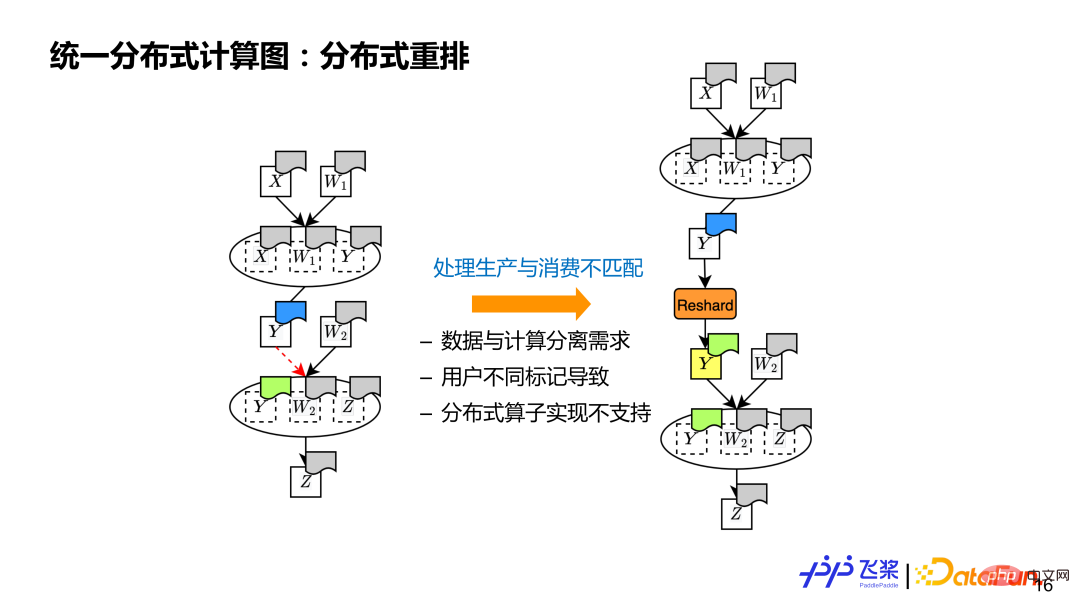
最後一個是分散式重排,這是分散式計算圖所必須具有的概念,用來處理源張量和目的張量分佈式屬性不同的情況。例如有2 個算子的計算,上一個算子產生y,跟下一個算子使用y 分佈式屬性不同(圖中用不同顏色表示),這時我們需要插入額外的一個Reshard 操作來透過通訊進行張量分散式重排,本質就是處理生產和消費不匹配問題。
導致不匹配的原因主要有三個面向:1)支援支援資料和計算分離,所以對張量和使用它的算符有不同的分佈式屬性;2)支援使用者自訂標記分佈式屬性,使用者可能對張量和使用它的算子標記不同的分佈式屬性;3)分散式運算子底層實作有限,如果出現了輸入或輸出分佈式屬性不支援的情況,也需要透過分散式重排。
2、統一分散式資源圖
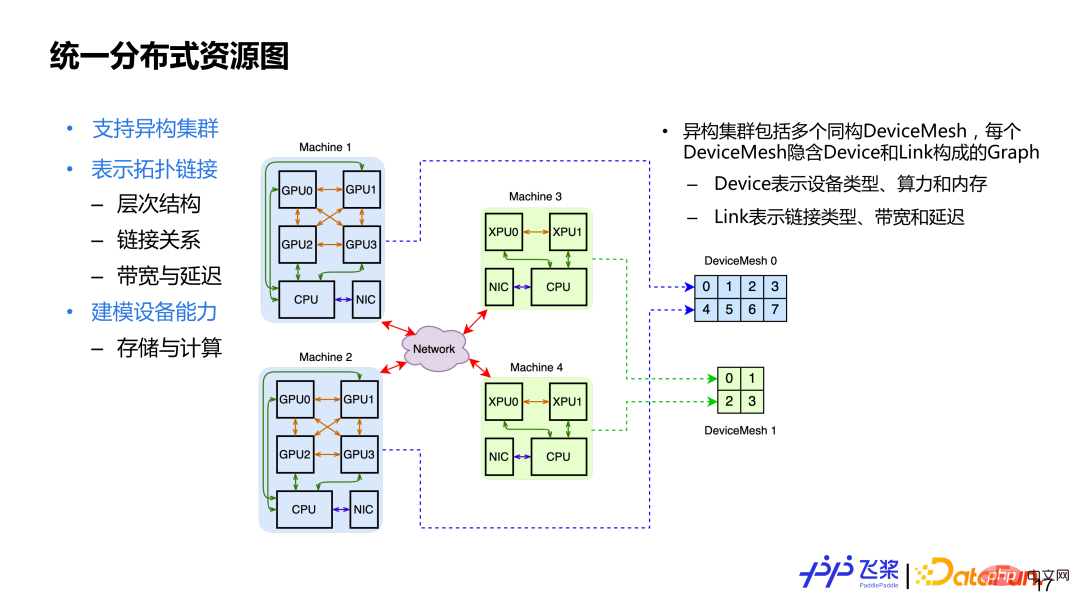
#介紹完統一的分佈計算圖三個基本概念後,再看統一的分佈式資源圖,主要設計的考量:1)支援異構集群,異質集群就是集群中可能有CPU、GPU、XPU 資源;2)表示拓樸連接,這裡面涵蓋了叢集的層次結構連接關係,包括連接能力的量化,例如頻寬或延遲;3)設備本身建模,包括一個設備的儲存和運算能力。為了滿足上面設計需求,我們用Cluster來表示分散式資源,它包含多個同構 DeviceMesh。每個 DeviceMesh 內會隱含一個由 Device 連結組成的 Graph。 ##########
這裡舉個例子,上圖可以看到有 4 台機器,包括 2 個 GPU 機器和 2 個 XPU 機器。對於 2 台 GPU 機器,會用一個同構的 DeviceMesh 表示,而對於 2 台 XPU 機器,會用另一個同構的 DeviceMesh 表示。對於一個固定叢集來說,它的 DeviceMesh 是固定不變的,而使用者操作的是 ProcessMesh,可以理解是 DeviceMesh 的抽象,使用者可以隨意 Reshape 和 Slice,最後會統一地將 ProcessMesh 進程對應到 DeviceMesh 裝置上。
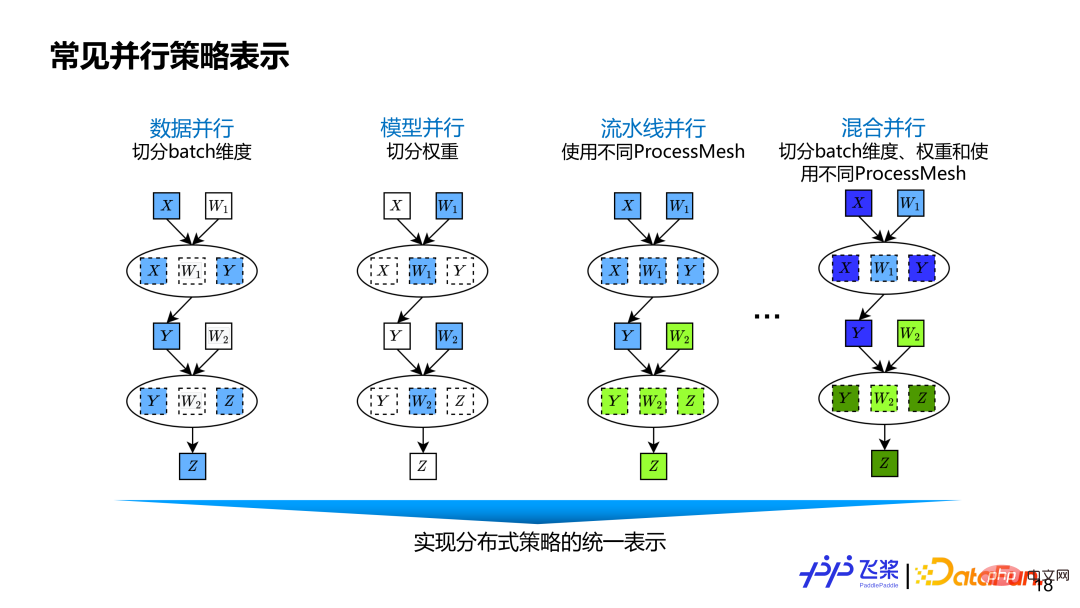
#採用前面基於張量和運算子細粒度的分散式計算圖表示,能涵蓋現有並行策略以及未來可能會出現新的並行策略。資料並行就是將資料張量的 Batch 維度進行切分。模型並行對權重相關維度進行切分。管線並行使用不同 ProcessMesh 來表示,它可以表示為更靈活 Pipeline 並行,例如一個 Pipeline Stage 可以連接多個 Pipeline Stage,而且不同 Stage 使用 ProcessMesh 的 shape 可以不同。其他有些框架的管線並行是透過 Stage Number 或 Placement 來實現,不夠靈活通用。混合並行就是資料並行,張量模型並行和管線並行三者混合。
三、關鍵實作
#前面是飛槳自動並行架構設計和一些抽象概念介紹。基於前面的基礎,以下我們透過 2 層 FC 網路例子,來介紹飛槳自動並行內部實作流程。
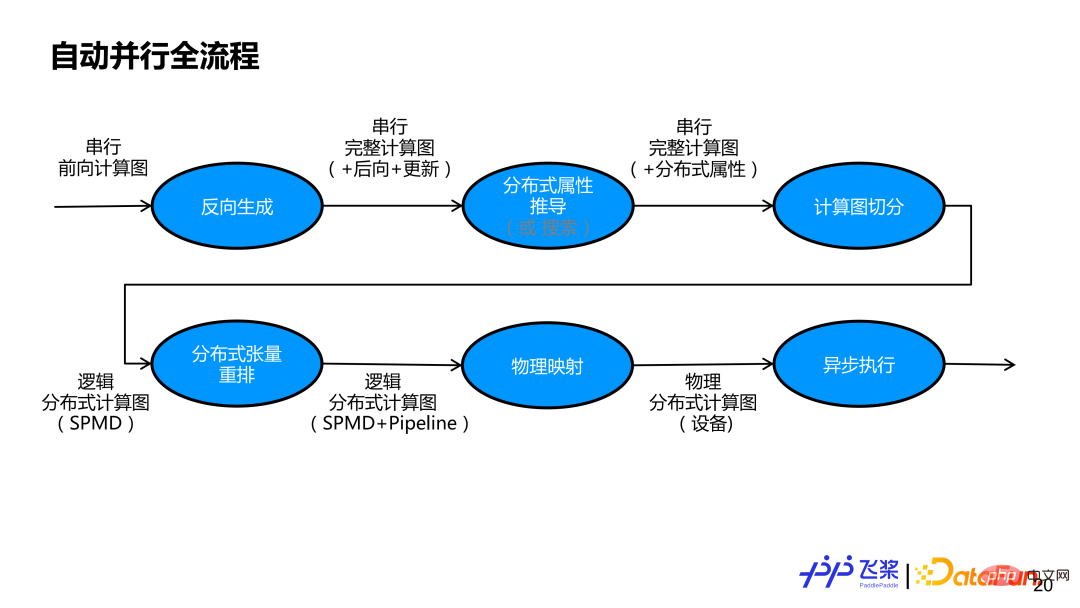
上圖是飛槳整個自動並行的流程圖。首先我們會基於一個串列前向計算圖,進行反向生成,取得包含前向、後向和更新子圖的完整計算圖。然後,需要明確組網中每個張量和每個算子的分佈式屬性。既可以採用半自動的推導方式,也可以採用全自動搜尋方式。本報告主要講解半自動推導方式,即基於使用者少量標記來推導其他未標記張量和算子的分散屬性。透過分散式屬性推導後,串行計算圖中每個張量和每個算子都有自己的分佈式屬性。基於分散式屬性,先透過自動切分模組,將串列計算圖變成支援 SPMD 平行的邏輯分散式計算圖,再透過分散式重排,實現支援 Pipeline 並行的邏輯分散式計算圖。產生的邏輯分散式計算圖會透過物理映射,變成物理分散式計算圖,目前只支援一個流程和一個裝置的一一映射。最後,將實體分散式計算圖變成一個實際任務依賴圖交給非同步執行器進行實際執行。
1、分散式屬性推導
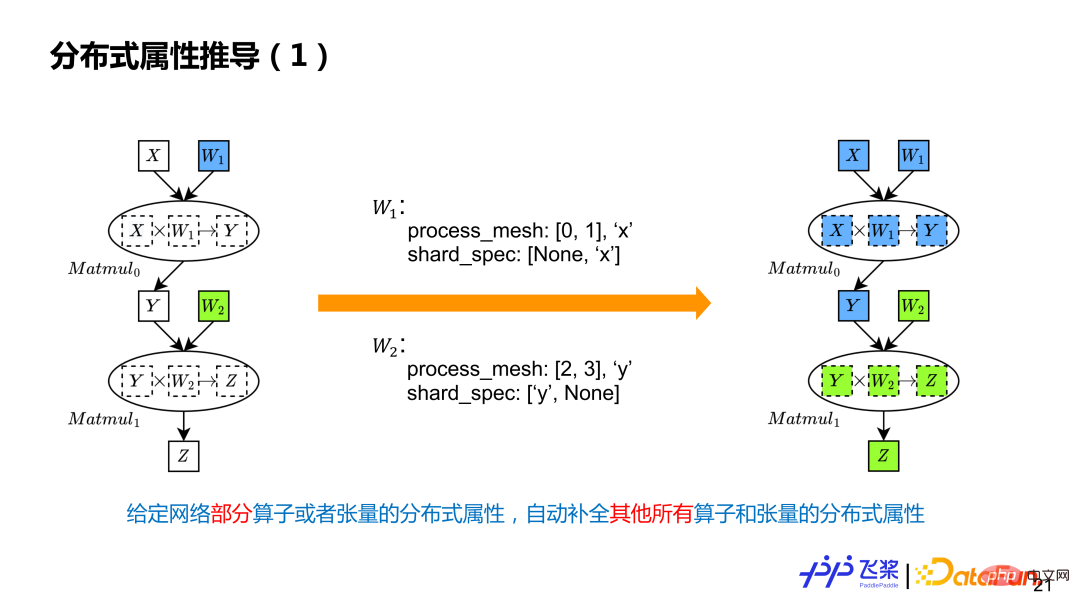
分散式屬性推導就是給定計算圖中部分張量和算符的分佈式屬性,自動補全其他所有的張量和算符的分佈式屬性。例子是兩個Matmul 計算,使用者只標記了兩個參數分佈式屬性,表示W1 在0,1 進程上進行列切,W2 是在2,3 個進程上進行行切,這裡有兩個不同ProcessMesh,用不同的顏色表示。
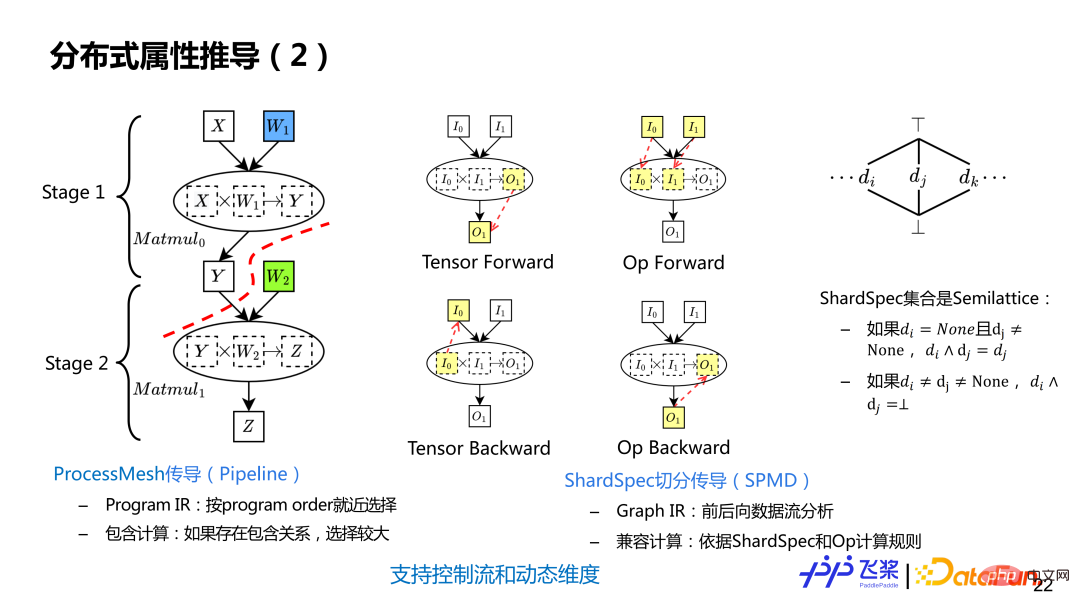
分散式屬性推導分為兩個步驟:1)先進行 ProcessMesh 傳導,實現 Pipeline 切分;2)再進行 ShardSpec 傳導,實現一個 Stage 內的 SPMD 切分。 ProcessMesh 推導利用了飛槳線性 Program lR, 按靜態 Program Order 採用就近選擇策略進行推導,支援包含計算,即如果兩個 ProcessMesh,一個大一個小,就選較大作為最終 ProcessMesh。而 ShardSpec 推導利用飛槳 SSA Graph IR 進行前向和後向資料流分析進行推導,之所以可以用資料流分析,是因為 ShardSpec 語義,滿足資料流分析的 Semilattice 性質。數流分析理論上能確保收斂,透過結合前向和後向分析,能夠將計算圖任何一個位置標記資訊傳播到整個計算圖,而不是只能單方向傳播。
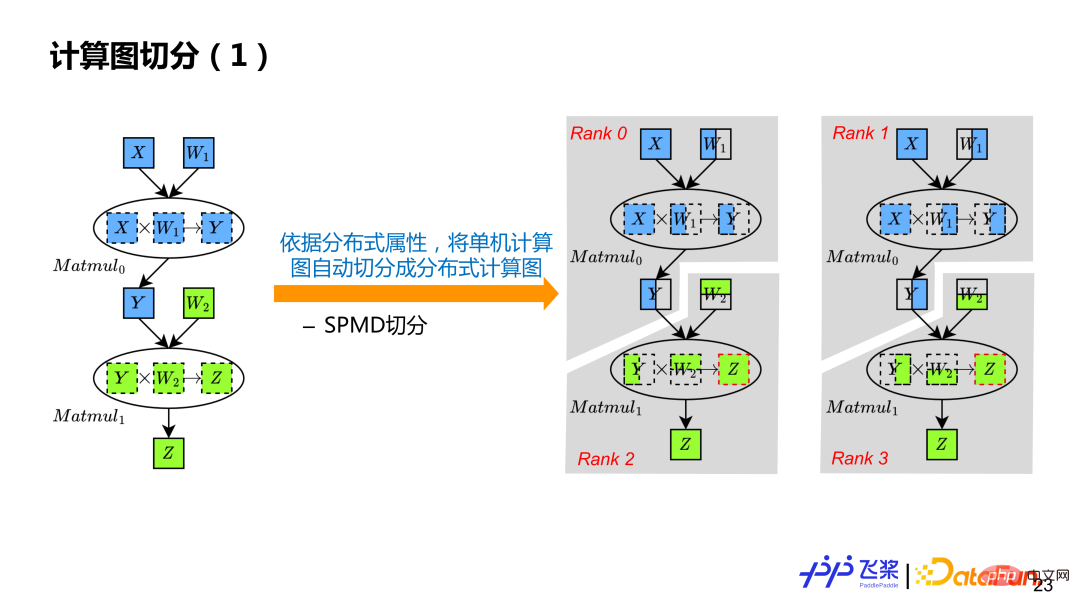
#基於分散式屬性推導,序列計算圖中的每個張量和算子都擁有自己的分散式屬性,這樣就可以基於分散式屬性進行計算圖的自動切分。依照例子來說,就是把單機串列計算圖,變成 Rank0、Rank1,Rank2、Rank3 四個計算圖。
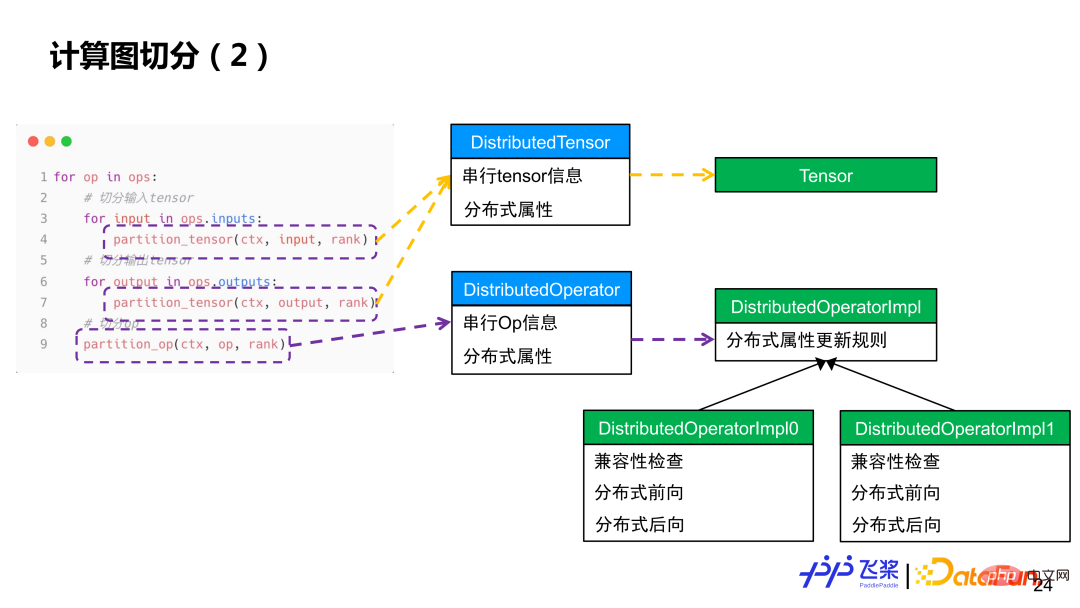
#簡單來說,會遍歷每個算子,先將算子輸入和輸出進行張量切分,然後再對每個算子進行計算切分。張量切分會透過Distributed Tensor 物件來建構Local Tensor 對象,而算子切分會透過Distributed Operator 物件來基於實際輸入和輸出的分佈屬性來選擇對應分散式實現,類似於單機框架的算子到Kernel 的分發過程。
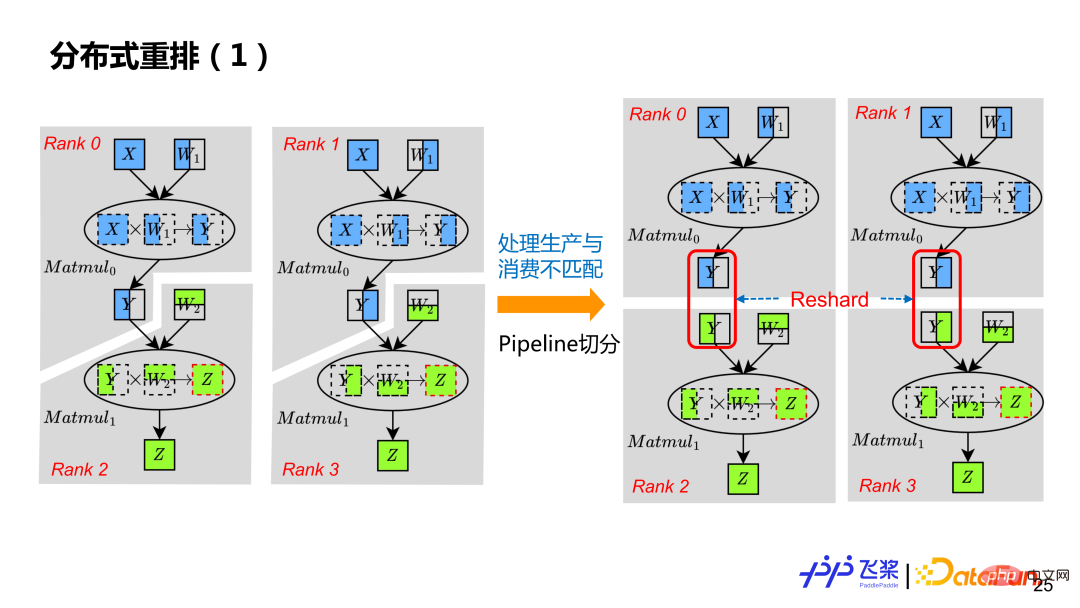
#透過前面自動切分,只能得到支援SPMD 並行的分散式運算圖。為了支援 Pipeline 並行,還需要透過分散式重排來處理,這樣透過插入一個適當的 Reshard 操作,例子中每個 Rank 都有自己真正獨立計算圖。雖然左圖 Rank0 的 Y 跟 Rank2 的 Y,切分一樣,但是由於他們在不同 ProcessMesh 上,導致了生產消費分佈式屬性不匹配,所以也需要插入 Reshard。
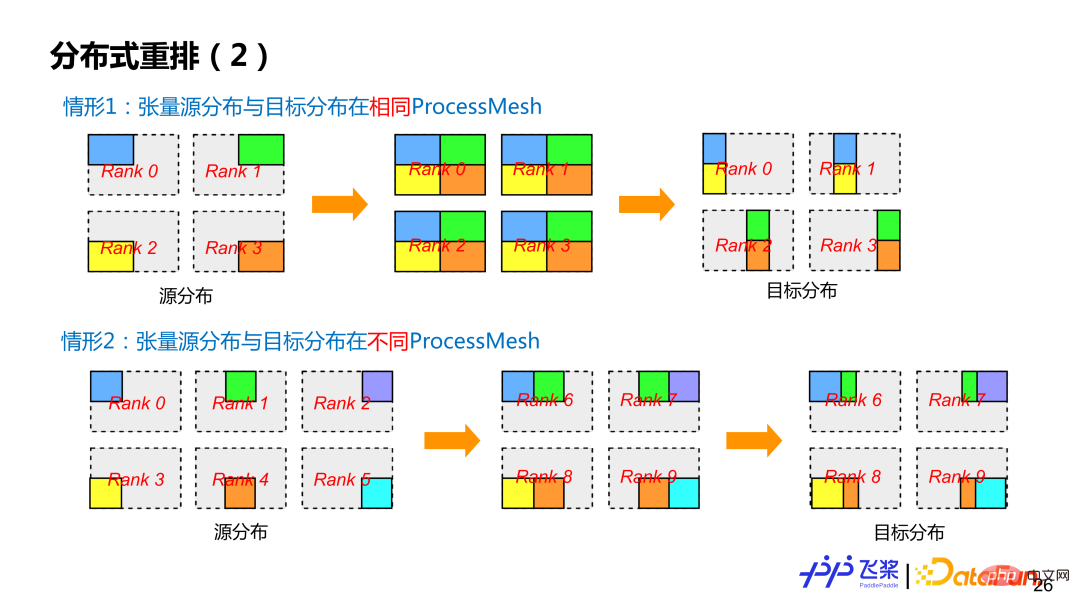
#飛槳目前支援兩類分散式重排。第一類,是比較常見源張量分佈跟目標張量分佈都在同一個 ProcessMesh 上,但是源張量分佈和目標張量分佈所使用切分方式不一樣(即 ShardSpec 不一樣)。第二類,是源張量分佈和目標張量分佈在不同的 ProcessMesh 上,而且 ProcessMesh 大小可以不一樣,比如圖中情形 2 中的 0-5 進程和 6-9 進程。為了盡可能減少通信,飛槳也對 Reshard 操作進行相關優化。
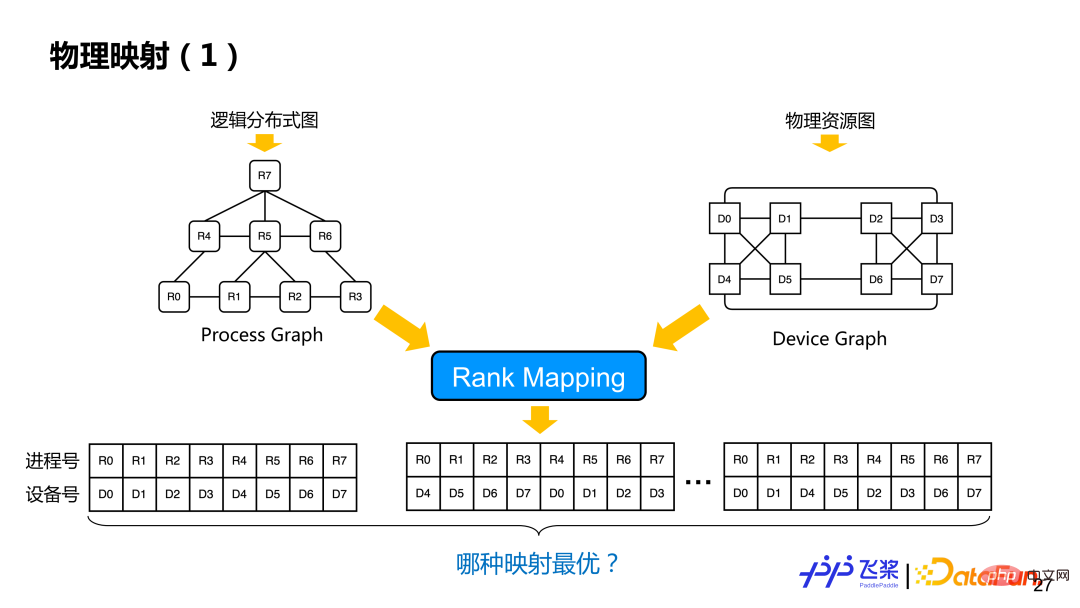
經過分散式重排後,得到一個邏輯上的分散式計算圖,這個時候還沒有決定進程和具體設備映射。基於邏輯的分散式計算圖和前面統一的資源表示圖,會進行物理映射操作,也就是Rank Mapping,就是從多種映射方案(一個進程具體跟哪個設備進行映射)中找到一個最優的映射方案。
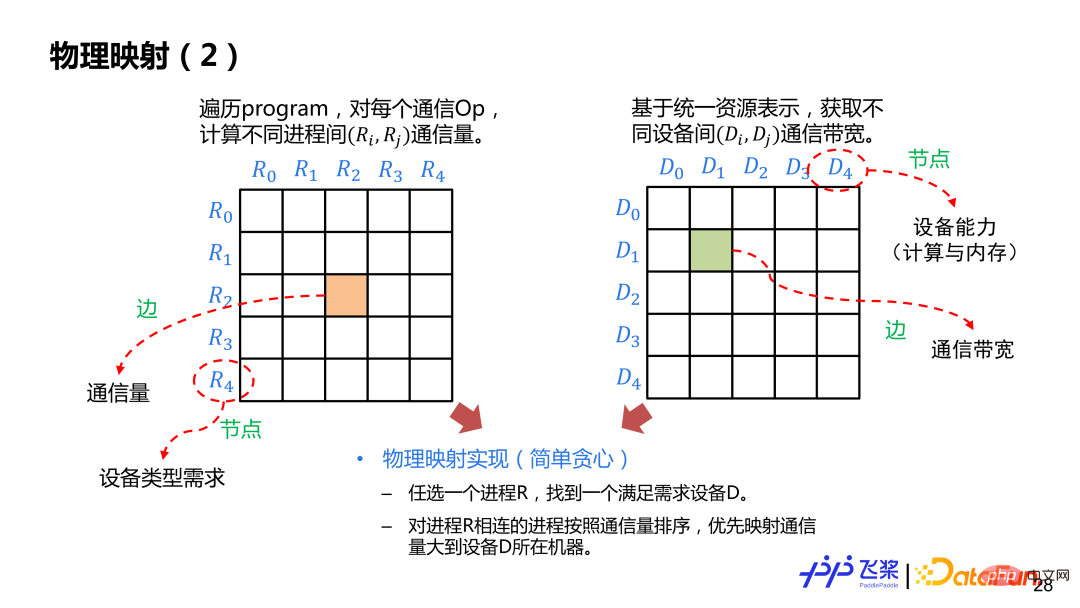
這裡介紹一個比較簡單基於貪心規則的實作。先建構進程與進程間通訊量的鄰接表,邊表示通訊量,節點表示設備需求,再建構設備與設備之間的鄰接表,邊表示通訊頻寬,節點表示設備計算與記憶體。我們會選擇性一個進程 R 放置到滿足需求的設備 D 上,放置後,選擇與 R 通訊量最大的進程放到 D 所在機器其他設備上,按照這種方式直到完成所有進程映射。在映射過程中,需要判斷所選的設備與進程圖所需求的設備類型以及所需計算量和記憶體是否匹配。
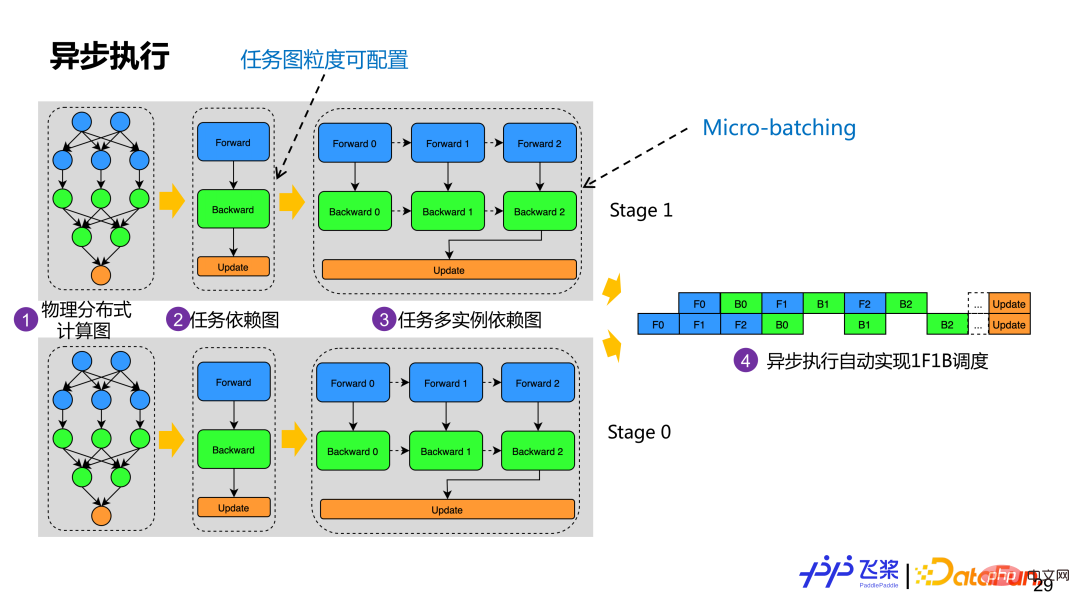
#透過物理映射後,我們會根據所獲得的物理分佈式組網構建實際任務依賴圖。圖中範例是基於計算圖的前向、後向和更新角色來建立任務依賴圖,相同角色的算子會組成一個任務。為了支援 Micro-batching 最佳化,一個任務依賴圖會產生多個任務實例依賴圖,每個範例雖然計算邏輯一樣,但使用不同記憶體。目前飛槳會自動地根據計算圖角色去建立任務圖,但使用者可以根據適當粒度自訂任務建構。每個行程有了任務多實例依賴圖後就會基於 Actor 模式進行非同步執行,透過訊息驅動方式就可以自動地實現 1F1B 執行調度。
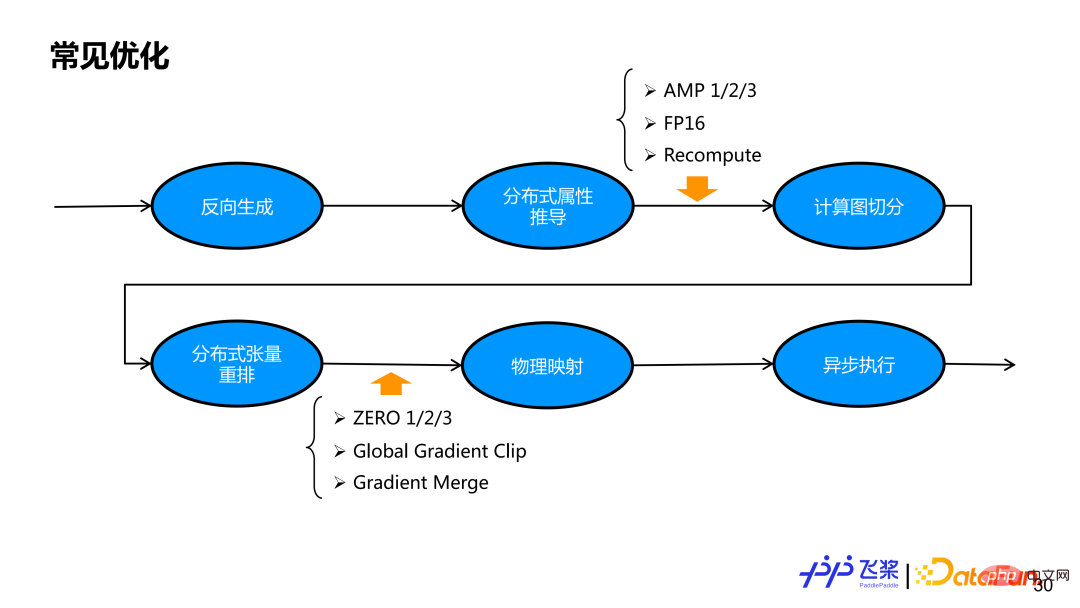
#基於上面整個流程,我們已經實作一個功能比較完備的自動並行。但只有並行策略還無法獲得一個比較好的端到端效能,所以我們還需要加入對應的最佳化策略。對飛槳自動並行,我們會在一個自動切分之前和組網切分之後加一些優化策略,這是因為一些優化在串行邏輯上實現比較自然,有一些優化在切分後比較容易實現,透過統一的最佳化Pass 管理機制,我們能夠確保飛槳自動並行中並行策略與最佳化策略自由結合。
四、應用實作
#下面介紹應用實作。
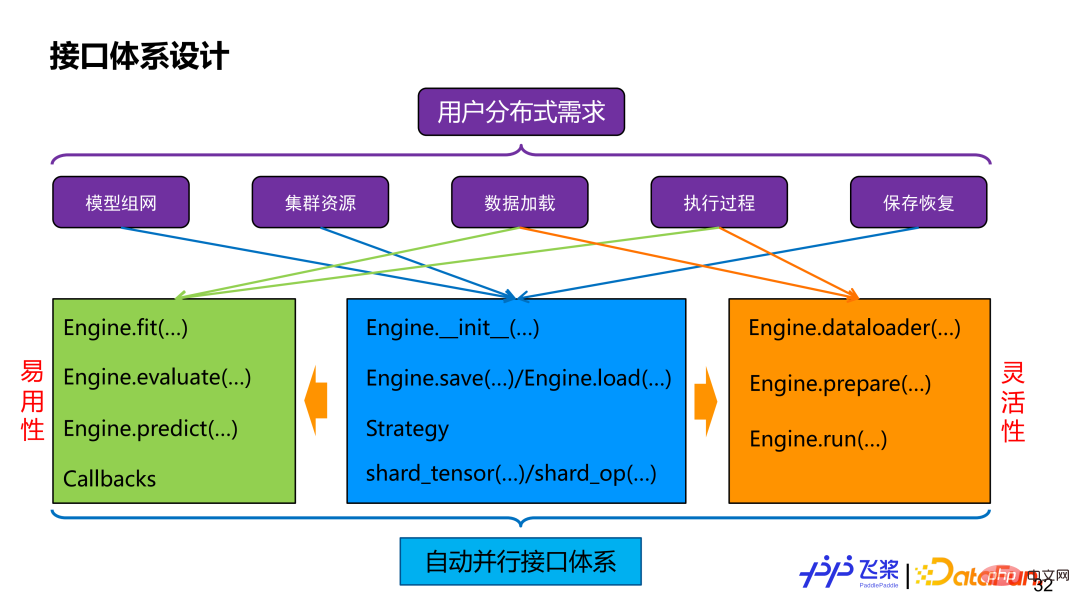
#首先是接口,不管如何實現,使用者最終還是透過介面來使用我們所提供的自動並行能力。如果對使用者分散式需求進行拆解,包括模型群組網切分,資源表示,資料分散式加載,分散式執行過程控制和分散式保存和恢復等。為了滿足這些需求,我們提供了一個 Engine 類,它同時兼顧易用性和靈活性。易用性方面,它提供了高階 API,能支援自訂 Callback,分散式流程對使用者透明。靈活性方面,它提供了低階 API,包括分散式 dataloader 構建,自動並行切圖和執行等接口,使用者可以進行更細微控制。兩者會共用 shard_tensor、shard_op 以及 save 和 load 等介面。
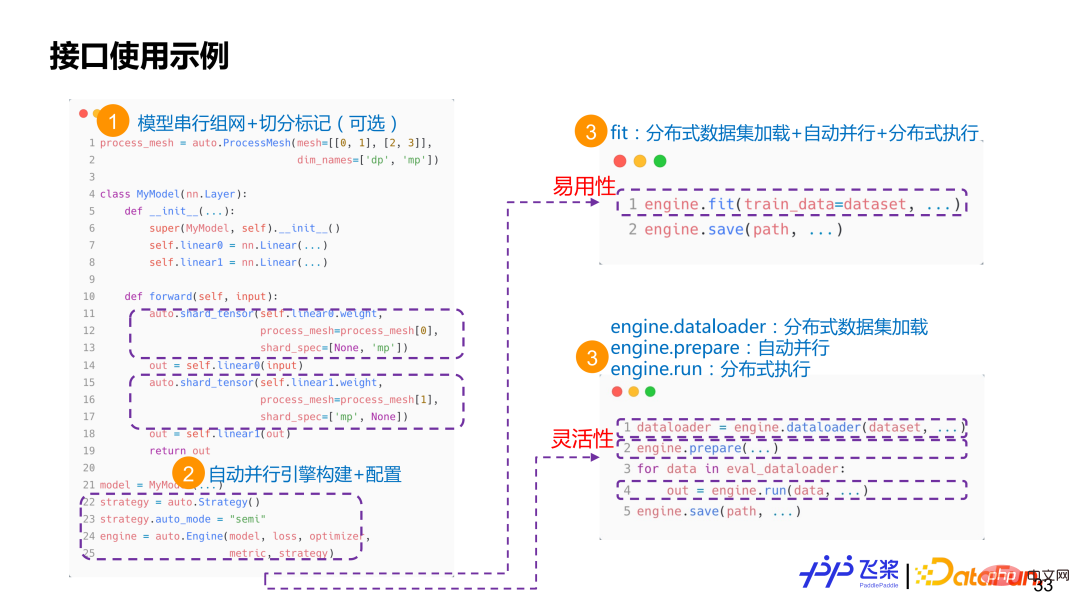
這裡有兩個標記介面 shard_op 和 shard_tensor。其中,shard_op 既可以標記單一算子,也可以對整個 Module 進行標記,是函數式。上圖是一個非常簡單的使用範例。首先,使用飛槳已有 API 進行一個串列組網,在其中,我們會使用 shard_tensor 或 shard_op 進行非侵入式分散式屬性標記。然後,建立一個自動並行 Engine,傳入模型相關資訊和配置。這時候使用者有兩個選擇,一個選擇是直接使用 fit /evaluate/predict 高階接口,另一個選擇是使用 dataloader prepare run 接口。如果選擇 fit 接口,使用者只需要傳遞 Dataset,框架會自動進行分散式資料集加載,自動並行過程編譯和分散式訓練執行。如果選擇 dataloader prepare run 接口,使用者可以將分散式資料載入、自動並行編譯和分散式執行進行解耦,能更好進行單步調試。
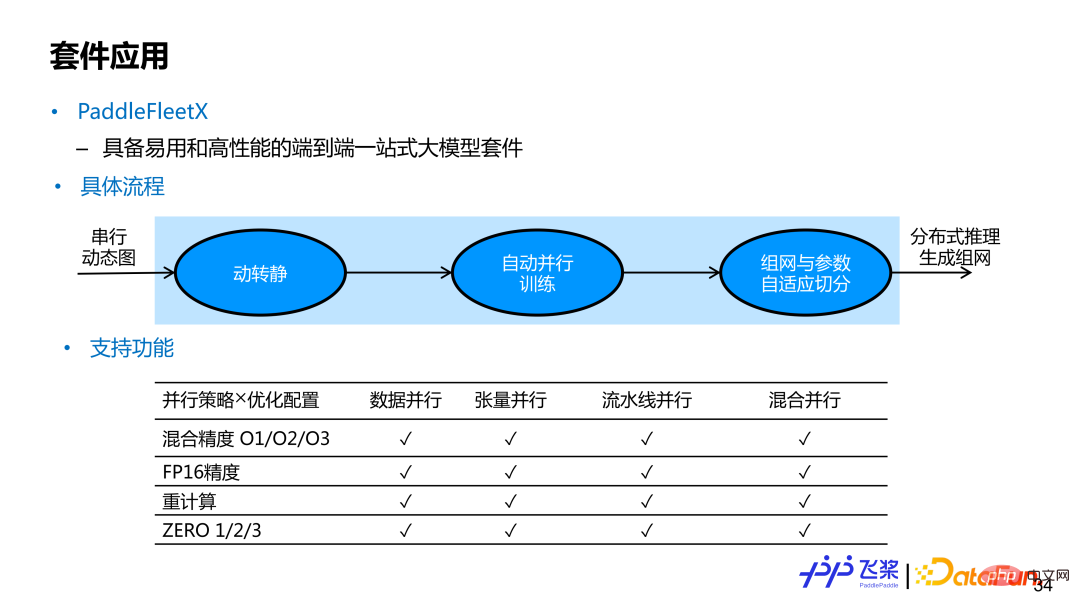
#PaddleFleetX 是具備易用性和高效能的一個端到端的一站式大模型套件,支援自動並行功能。使用者若想呼叫飛槳自動並行端到端功能,只需要提供串列動態圖模型組網即可。在取得使用者動態圖串列群組網後,內部實作會利用飛槳動轉靜模組,將動態圖單卡組網變成靜態圖單卡組網,然後透過自動並行編譯,最後再進行分散式訓練。在推理生成時候,使用的機器資源可能與訓練時使用的資源不太一樣,內部實作也會進行參數和組網的自適應參數切分。目前 PaddleFleetX 中的自動並行涵蓋了大家常用的平行策略和最佳化策略,並支援兩者任意組合,對生成任務來說,也支援 While 控制流的自動切分。
五、總結展望

#飛槳自動並行還有很多工作在開展中,目前的特色可以總結為以下幾方面:
#首先,統一的分散式計算圖,能夠支持完整的SPMD 和Pipeline 的分散式策略,能夠支援儲存與運算的分離式表示;
第二,統一的分散式資源圖,能夠支援異質資源的建模和表示;
第三,支援平行策略和最佳化策略的有機結合;
第四,提供了比較完備的介面體系;
#最後,作為關鍵組成,支撐飛槳端到端的自適應分散式架構。
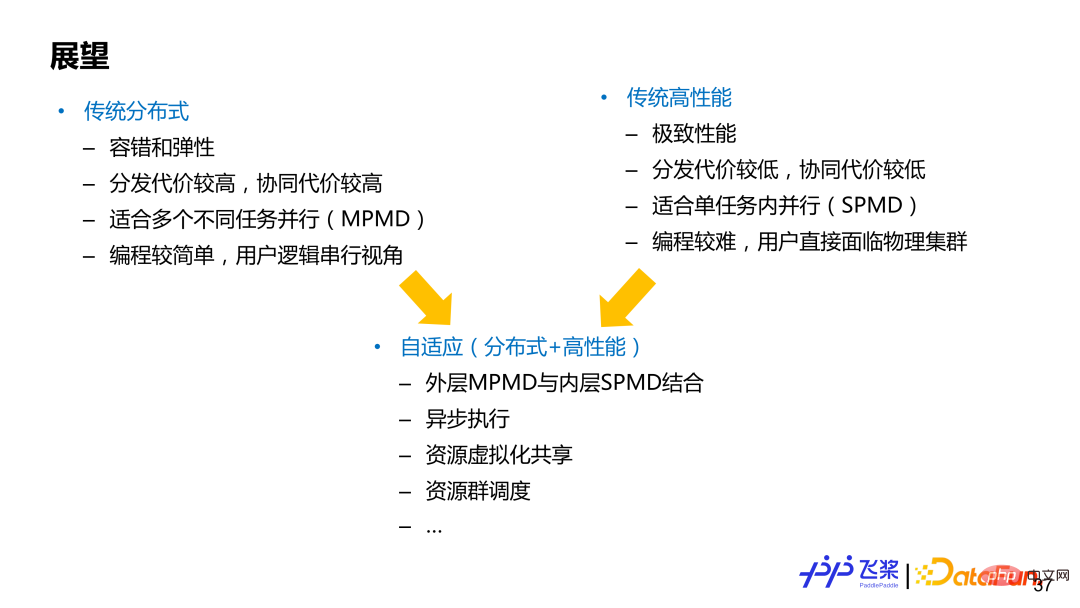
#並行一般可以分成兩個領域(沒有明確分界),一個是傳統的分散式運算,一個是傳統高效能運算,兩者各有優劣。基於傳統分散式運算的框架代表是TensorFlow,它著重MPMD(Multiple Program-Multiple Data)並行模式,能夠很好支援彈性和容錯,分散式運算的使用者體驗會好一些,程式設計較簡單,使用者一般是以一個串行全局視角進行編程;基於傳統高效能的計算的框架代表是PyTorch,更側重SPMD(Single Program-Multiple Data)模式,追求極致性能,用戶需要直接面臨物理集群進行編程,自己負責切分模型和插入合適通信,對使用者要求較高。而自動並行或自適應分散式計算,可以看作兩者結合。當然不同架構設計重點不一樣,需要根據實際需求進行權衡,我們希望飛槳自適應架構能兼顧兩個領域的優勢。
#以上是飛槳面向異構場景下的自動並行設計與實踐的詳細內容。更多資訊請關注PHP中文網其他相關文章!