
ChatGPT:強大模型、注意力機制和強化學習的融合

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-08 18:16:091363瀏覽
本文主要介紹為ChatGPT提供動力的機器學習模型,將從大型語言模型的介紹開始,深入探討使GPT-3得到訓練的革命性的自註意機制,然後深入到從人類反饋強化學習,這是使ChatGPT出類拔萃的新技術。
大型語言模型
ChatGPT是一類機器學習自然語言處理進行推論的模型,稱為大型語言模型(LLM)。 LLM消化了大量的文本數據,並推斷出文本中單字之間的關係。在過去的幾年裡,隨著運算能力的進步,這些模型也在不斷發展。隨著輸入資料集和參數空間大小的增加,LLM的能力也增加。
語言模型的最基本的訓練涉及預測一連串詞彙中的一個單字。最常見的是,這被觀察為下一個標記預測和屏蔽語言模型。
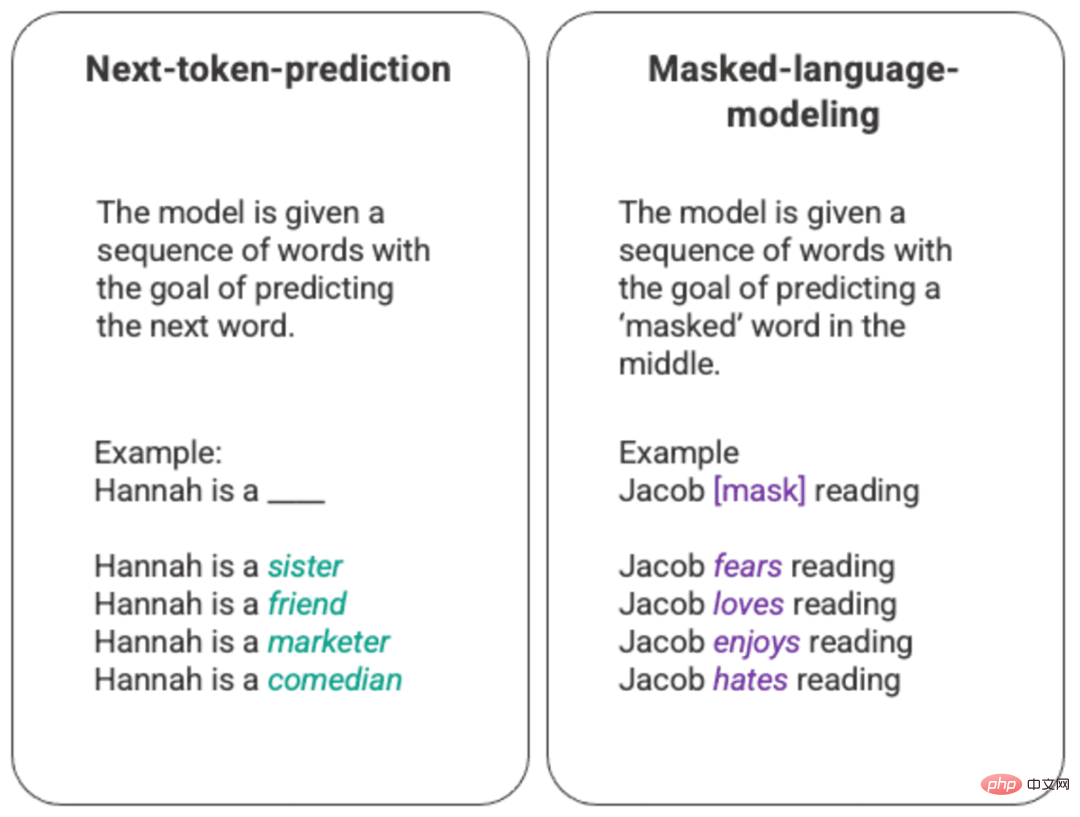
產生的下一個標記預測和屏蔽語言模型的任意範例
在這種基本的排序技術中,通常是透過長短記憶(LSTM )模型來部署的,模型是在給定環境和上下文的情況下,用統計上最有可能的詞來填補空白。這種順序建模結構有兩個主要限制。
- 該模型無法對周圍的一些單字比其他單字更重視。在上面的例子中,雖然“閱讀”可能最常與“討厭”聯繫在一起,但在資料庫中,“雅各布”可能是一個狂熱的讀者,模型應該更重視“雅各布”而不是“閱讀”,並選擇“愛”而不是“討厭”。
- 輸入的資料是單獨且依序處理的,而不是作為一個整體語料庫。這意味著當訓練LSTM時,上下文的視窗是固定的,只在序列中的幾個步驟的單一輸入之外延伸。這限制了詞與詞之間關係的複雜性以及可以得出的含義。
為了回應這個問題,2017年,Google Brain的一個團隊引進了轉換器。與LSTM不同,轉換器可以同時處理所有輸入資料。利用自我注意機制,該模型可以相對於語言序列的任何位置為輸入資料的不同部分賦予不同的權重。這項特性使得在向LLM注入意義方面有了大規模的改進,並且能夠處理更大的資料集。
GPT和Self-Attention
#生成式預訓練轉換器(GPT)模型於2018年首次由OpenAI推出,名為GPT -1。這些模型在2019年的GPT-2、2020年的GPT-3以及最近的2022年的InstructGPT和ChatGPT中繼續發展。在將人類回饋整合到系統中之前,GPT模型演化的最大進步是由計算效率的成就所推動的,這使得GPT-3能夠在比GPT-2多得多的資料上進行訓練,使其擁有更多樣化的知識基礎和執行更廣泛任務的能力。

GPT-2(左)與GPT-3(右)的比較。
所有的GPT模型都利用了轉換器結構,這意味著它們有一個編碼器來處理輸入序列,一個解碼器來產生輸出序列。編碼器和解碼器都具有多頭的自我注意機制,允許模型對序列的各個部分進行不同的加權,以推斷出意義和背景。此外,編碼器利用屏蔽語言模型來理解單字之間的關係,並產生更易於理解的反應。
驅動GPT的自註意機制的工作原理,是透過將標記(文字片段,可以是一個字、一個句子或其他文字分組)轉換為代表該標記在輸入序列中的重要性的向量。為了做到這一點,該模型:
- 1.为输入序列中的每个标记创建一个
query,key,和value向量。 - 2.通过取两个向量的点积,计算步骤1中的
query向量与其他每个标记的key向量之间的相似性。 - 3.通过将第2步的输出输入一个
softmax函数中来生成归一化的权重。 - 4.通过将步骤3中产生的权重与每个标记的
value向量相乘,产生一个最终向量,代表该序列中标记的重要性。
GPT使用的“multi-head”注意机制是自我注意的一种进化。该模型不是一次性执行第1-4步,而是并行地多次迭代这一机制,每次都会生成一个新的query,key,和value向量的线性投影。通过以这种方式扩展自我注意,该模型能够掌握输入数据中的子含义和更复杂的关系。

从ChatGPT生成的屏幕截图。
尽管GPT-3在自然语言处理方面引入了显著的进步,但它在与用户意图保持一致的能力方面是有限的。例如,GPT-3可能会产生以下输出结果:
- 缺乏帮助性,意味着它们不遵循用户的明确指示。
- 含有反映不存在的或不正确的事实的幻觉。
- 缺乏可解释性,使人类难以理解模型是如何得出一个特定的决定或预测的。
- 包含有害或有冒犯性的内容以及传播错误信息的有害或偏见内容。
在ChatGPT中引入了创新的训练方法,以抵消标准LLM的一些固有问题。
ChatGPT
ChatGPT是InstructGPT的衍生产品,它引入了一种新颖的方法,将人类反馈纳入训练过程,使模型的输出与用户的意图更好地结合。来自人类反馈的强化学习(RLHF)在openAI的2022年论文《Training language models to follow instructions with human feedback》中得到了深入的描述,并在下面进行了简单讲解。
第1步:监督微调(SFT)模型
第一次开发涉及微调GPT-3模型,雇用40个承包商来创建一个有监督的训练数据集,其中输入有一个已知的输出供模型学习。输入或提示是从开放API的实际用户输入中收集的。然后,标签人员对提示编写适当的响应,从而为每个输入创建一个已知的输出。然后,GPT-3模型使用这个新的、有监督的数据集进行微调,以创建GPT-3.5,也称为SFT模型。
为了最大限度地提高提示信息数据集的多样性,只有200条提示信息可以来自任何给定的用户ID,并且删除了共享长通用前缀的任何提示信息。最后,删除了包含个人身份信息(PII)的所有提示。
在匯總了OpenAI API的提示資訊後,也要求標籤人員建立提示資訊樣本,以填補那些只有極少真實樣本資料的類別。所關注的類別包括:
- 普通提示:任何任意的詢問。
- 少量的提示:包含多個查詢/回答對的指令。
- 基於使用者的提示:對應於為OpenAI API請求的特定用例。
在產生回應時,請標籤人員盡力推斷出使用者的指令是什麼。該文件描述了提示請求資訊的三種主要方式。
- 直接:「告訴我關於...」
- #寥寥數語:給出這兩個故事的例子,再寫一個關於同一主題的故事。
- 續寫:給出一個故事的開頭,完成它。
對來自OpenAI API的提示和標籤人員手寫的提示進行彙編,產生了13,000個輸入/輸出樣本,用於監督模型的使用。
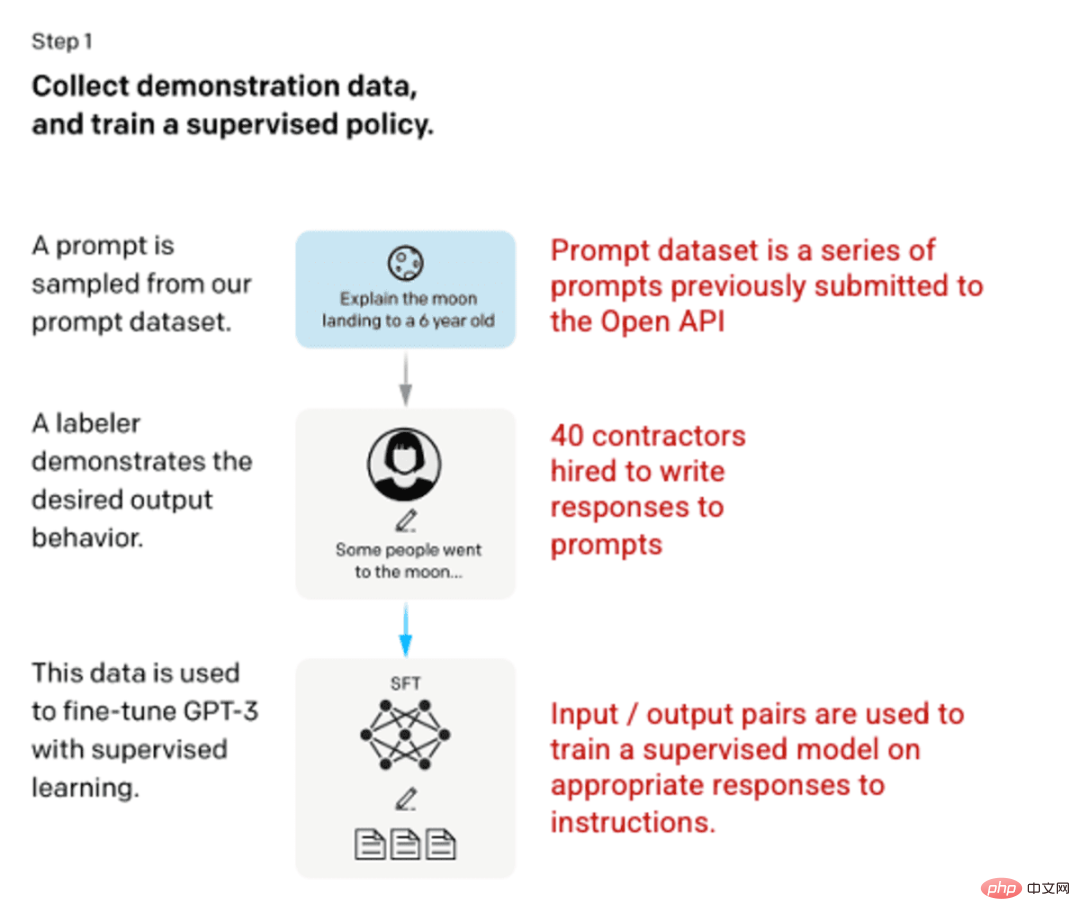
圖片(左)插入自「Training language models to follow instructions with human feedback」 OpenAI等,2022 https://arxiv.org/pdf/2203.02155.pdf。 (右)用紅色添加的其他上下文。
第2步:獎勵模型
在步驟1中訓練了SFT模型後,該模型對使用者的提示產生了更好的、一致的反應。下一個改進是以訓練獎勵模型的形式出現的,其中模型的輸入是一系列的提示和響應,而輸出是一個標度值,稱為獎勵。為了利用強化學習(Reinforcement Learning),獎勵模型是必要的,在強化學習中,模型會學習產生輸出以最大化其獎勵(見步驟3)。
為了訓練獎勵模型,標籤人員對單一的輸入提示提供4到9個SFT模型輸出。他們被要求將這些輸出從最好的到最糟糕的進行排序,創建輸出排序的組合,如下所示:

響應排序組合的範例。
將每個組合作為一個單獨的數據點納入模型,會導致過度擬合(無法推斷出所見數據之外的內容)。為了解決這個問題,模型是利用每組排名作為一個單獨的批次資料點來建立的。
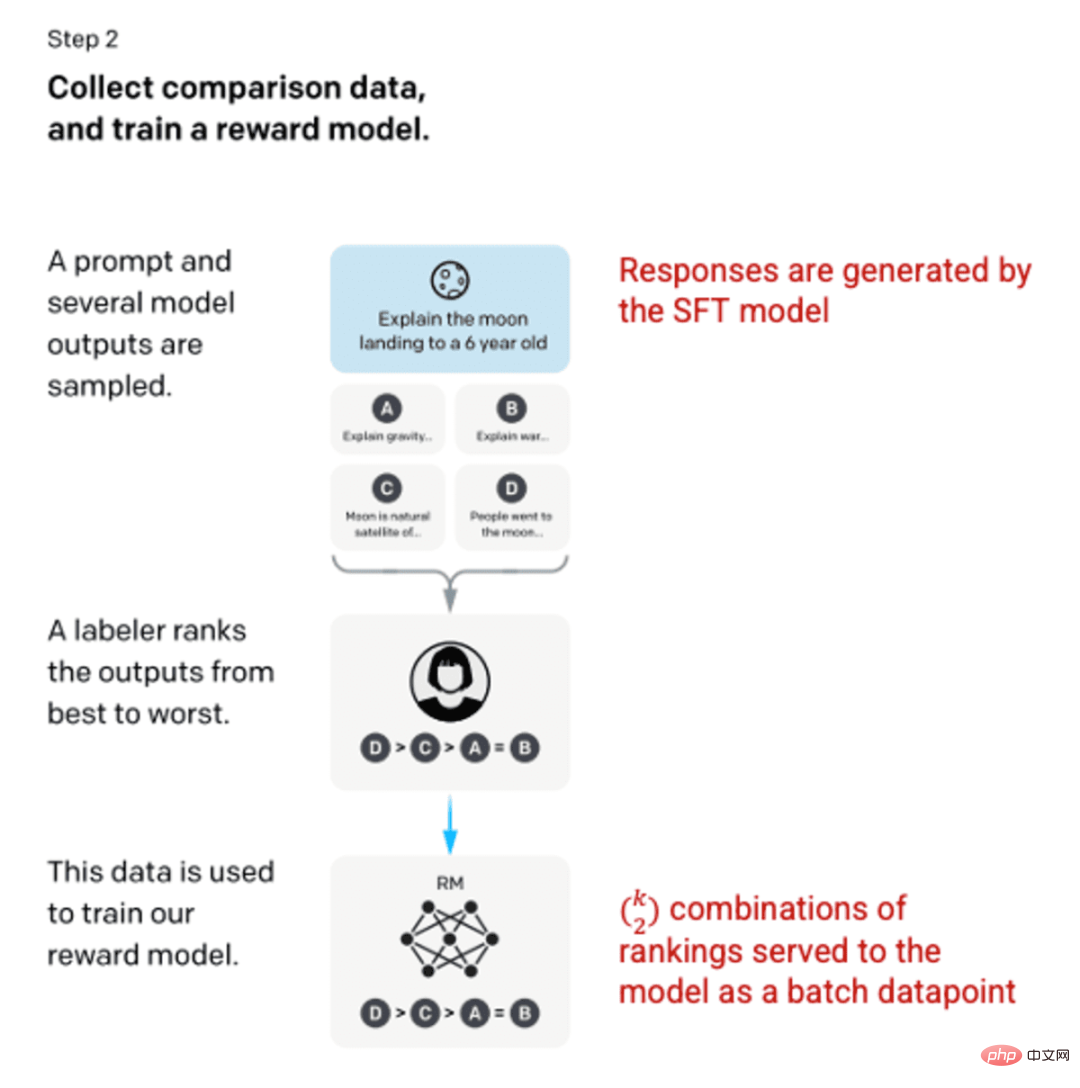
圖片(左)插入自「Training language models to follow instructions with human feedback」 OpenAI等,2022 https://arxiv.org/pdf/2203.02155.pdf。 (右)用紅色添加的其他上下文。
第3步:強化學習模型
在最後階段,向模型提出一個隨機提示並回傳一個反應。反應是使用模型在第2步學到的「策略」 產生的。該策略代表機器已經學會用於實現其目標的策略;在這種情況下,就是將其獎勵最大化。基於步驟2中開發的獎勵模型,然後為提示和回應對確定一個標度獎勵值。然後,獎勵會回饋到模型中以發展策略。
2017年,Schulman等人引入了近端策略優化(PPO),該方法用於在生成每個響應時更新模型的策略。 PPO納入了SFT模型中的Kullback-Leibler(KL)懲罰。 KL散度測量兩個分佈函數的相似性,並對極遠距離進行懲罰。在這種情況下,使用KL懲罰可以減少響應與步驟1中訓練的SFT模型輸出的距離,以避免過度優化獎勵模型並與人類意圖資料集發生太大偏差。
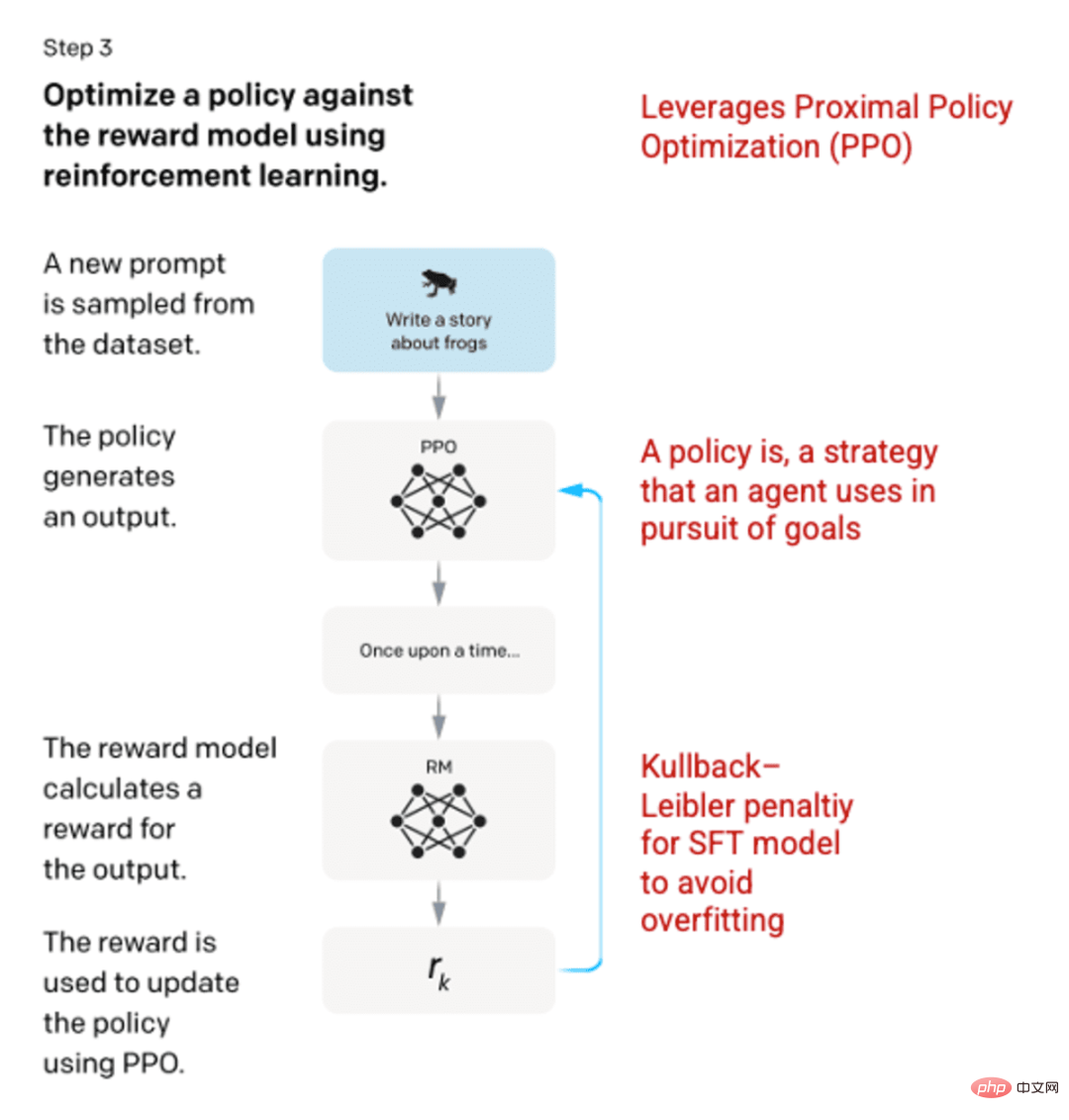
圖片(左)插入自「Training language models to follow instructions with human feedback」 OpenAI等,2022 https://arxiv.org/pdf/2203.02155.pdf。 (右)用紅色添加的其他上下文。
這個過程的第2和第3步可以重複迭代,儘管在實踐中還沒有廣泛地進行。

從ChatGPT產生的螢幕截圖。
模型的評估
對模型的評估是透過在訓練期間預留一個模型未見過的測試集來進行的。在測試集上,進行一系列的評估,以確定模型是否比其前身GPT-3表現更好。
有用性:模型推論和遵循使用者指令的能力。標籤人員在85±3%的時間裡喜歡InstructGPT的輸出,而不是GPT-3。
真實性:模型出現幻覺的傾向。在使用TruthfulQA資料集進行評估時,PPO模型產生的輸出在真實性和資訊量方面都有小幅增加。
無害性:模型避免不適當的、貶低的和詆毀的內容的能力。無害性是使用RealToxicityPrompts資料集來測試的。該測試在三種條件下進行。
- 指示提供尊重的反應:導致有害反應的明顯減少。
- 指示提供反應,沒有任何關於尊重的設定:有害性沒有明顯變化。
- 指導提供有害的反應:反應實際上比GPT-3模型的有害性明顯增加。
關於創建ChatGPT和InstructGPT所使用方法的更多信息,請閱讀OpenAI發表的原始論文“Training language models to follow instructions with human feedback”,2022 https://arxiv .org/pdf/2203.02155.pdf。
從ChatGPT產生的螢幕截圖。
以上是ChatGPT:強大模型、注意力機制和強化學習的融合的詳細內容。更多資訊請關注PHP中文網其他相關文章!