
Java如何將Excel資料轉化為樹狀結構?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-08 08:49:072456瀏覽
前言
今天收到一個導入的任務,要求將excel資料保存到資料庫中,不同於普通的導入,這個導入的資料是一個樹形結構,如下圖:
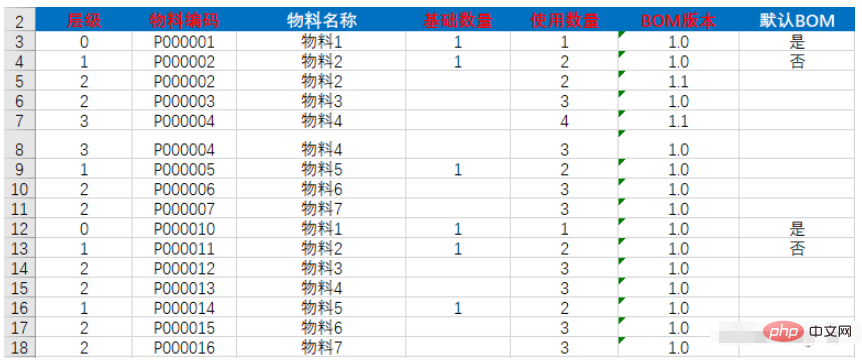
透過觀察資料中的層級列我們發現表格資料由2棵樹組成,分別是第3,4,5,6,7,8,9,10,11和12 ,13,14,15,16,17,18,它們由0作樹的根節點,1為0的子節點,2為相鄰1的子節點,由此得出第一顆樹的結構為:
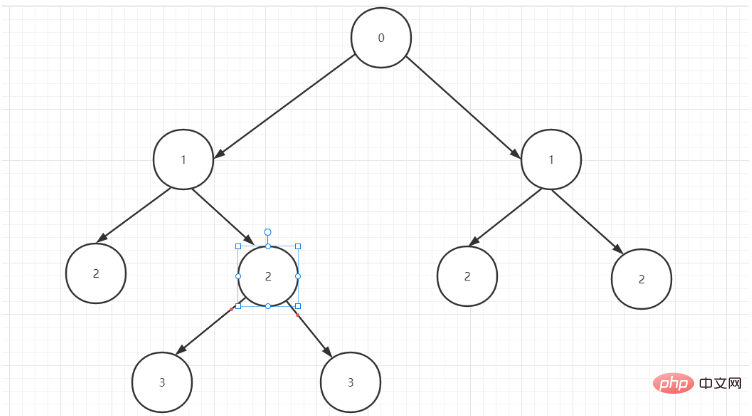
分割原始資料
1.建立實體類別
建立vo接收解析資料,在這裡,我們只關心層級屬性
@Excel(name = "层级")
private String hierarchy;
@Excel(name = "物料编码")
private String materialCode;
@Excel(name = "物料名称")
private String materialName;
@Excel(name = "基础数量")
private BigDecimal materialNum;
@Excel(name = "使用数量")
private BigDecimal useAmount;
@Excel(name = "BOM版本")
private String version;
@Excel(name = "默认BOM")
private String isDefaults;2.處理資料
將資料來源拆分為若干棵樹的資料集
程式碼如下(範例):
/**
* 将集合对象按指定元素分割存储
*
* @param materialVos 原始集合
* @param s 分割元素(这里是当集合对象层级为0时则分割,也就是树的根节点为0)
* @return 每棵树的结果集
*/
private List<List<MatMaterialBomImportVo>> subsection(List<MatMaterialBomImportVo> materialVos, String s) {
List<List<MatMaterialBomImportVo>> segmentedData = new ArrayList<>();
if (materialVos != null) {
//获取指定元素的数量,判断出最终将拆分为多少段
List<MatMaterialBomImportVo> collect = materialVos.stream().filter(bom -> s.equals(bom.getHierarchy())).collect(Collectors.toList());
int count = 0;
for (int i = 0; i < collect.size(); i++) {
List<MatMaterialBomImportVo> bomImportVo = new ArrayList<>();
boolean num = false;
//遍历数据源
for (; count < materialVos.size(); count++) {
//第一个必然为树的根节点,直接获取并跳过
if (count == 0) {
bomImportVo.add(materialVos.get(count));
continue;
}
//当数据源第n个等于根节点并且已经成功添加过数据时判断为一段数据的结束,跳出循环,
if (s.equals(materialVos.get(count).getHierarchy()) && num) {
break;
}
bomImportVo.add(materialVos.get(count));
num = true;
}
segmentedData.add(bomImportVo);
}
}
return segmentedData;
}手動設置每棵樹每個節點的id以及父id
程式碼如下(範例):
for (List<MatMaterialBomImportVo> segmentedDatum : subsection(materialVos, "0")) {
//设置id以及父id
int i = 0;
for (MatMaterialBomImportVo vo : segmentedDatum) {
BeanTrim.beanAttributeValueTrim(vo);
vo.setPrimaryKey(i);
getParentId(vo, segmentedDatum);
i++;
}
}
/**
* 设置父id
*
* @param vo
* @param segmentedDatum
*/
private void getParentId(MatMaterialBomImportVo vo, List<MatMaterialBomImportVo> segmentedDatum) {
for (int j = vo.getPrimaryKey(); j >= 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
break;
}
if (j == 0) {
vo.setForeignKey(-1);
}
}
}說明:拆分為若干棵樹後設定每個資料的虛擬id為自己的索引,每棵樹的id互相隔離,
根據表格資料規律得出子節點只可能存在於自己節點以下,以及下一個相同節地以上,根據這個規律設定每個節點的父id
遞歸封裝為樹結構
程式碼如下(範例):
/**
* 递归遍历为树形结构
*
* @param vo 当前处理的元素
* @param segmentedDatum 每棵树的数据集
*/
private void treeData(MatMaterialBomImportVo vo, List<MatMaterialBomImportVo> segmentedDatum) {
for (int i = vo.getPrimaryKey(); i < segmentedDatum.size(); i++) {
if (i + 1 == segmentedDatum.size()) {
if (vo.getForeignKey() == null) {
getParentId(vo, segmentedDatum);
}
break;
}
int v = Integer.parseInt(vo.getHierarchy());
int vs = Integer.parseInt(segmentedDatum.get(i + 1).getHierarchy());
if (vs == v + 1) {
if (v > 1) {
vo.setForeignKey(segmentedDatum.get(i).getPrimaryKey());
for (int j = vo.getPrimaryKey(); j > 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
}
}
}
vo.getImportVoList().add(segmentedDatum.get(i + 1));
}
if (vs <= v) {
if (vo.getForeignKey() == null) {
for (int j = vo.getPrimaryKey(); j > 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
break;
}
}
}
break;
}
}
if (vo.getImportVoList() != null && vo.getImportVoList().size() > 0) {
for (MatMaterialBomImportVo matMaterialBomImportVo : vo.getImportVoList()) {
treeData(matMaterialBomImportVo, segmentedDatum);
}
}
}說明:我這裡傳進來的vo是沒有設定id和父id的,只對資料來源做了樹拆分處理,因為業務需求,後面並沒有使用這套遞歸的方法組裝為樹,所以遞歸代碼可能有點誤差,僅供參考
以上是Java如何將Excel資料轉化為樹狀結構?的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:yisu.com。如有侵權,請聯絡admin@php.cn刪除