
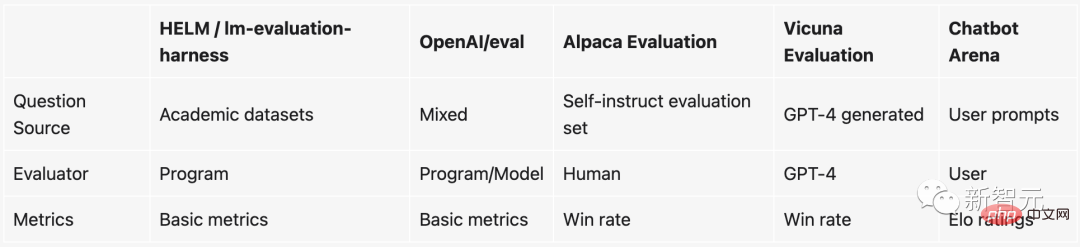
UC伯克利發布大語模型排行榜! Vicuna奪冠,清華ChatGLM進前5

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-04 23:04:091587瀏覽
最近,來自LMSYS Org(UC柏克萊主導)的研究人員又搞了個大新聞-大語言模型版排位賽!
顧名思義,「LLM排位賽」就是讓一群大語言模型隨機進行battle,並根據它們的Elo得分進行排名。
然後,我們就能一眼看出,某個聊天機器人到底是「嘴強王者」還是「最強王者」。
劃重點:團隊也計畫把國內和國外的這些「閉源」模型都搞進來,是騾子是馬溜溜就知道了! (GPT-3.5現在就已經在匿名競技場裡了)

#匿名聊天機器人競技場長下面這樣:
很明顯,模型B回答正確,拿下這局;而模型A連題都沒讀懂…
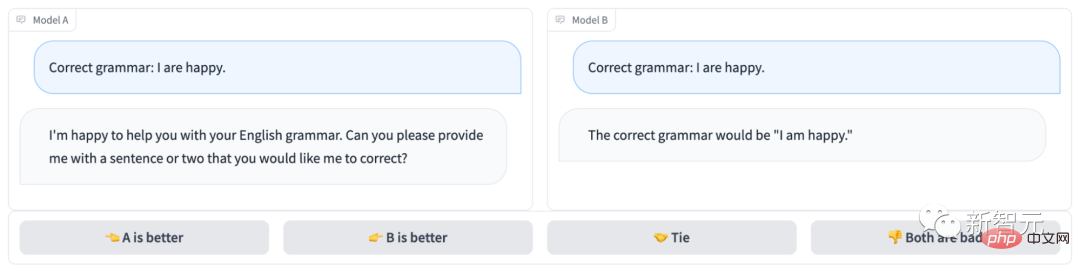
#專案網址:https://arena.lmsys.org/
在目前的排行榜中,130億參數的Vicuna以1169分穩居第一,同樣130億參數的Koala則排名第二,LAION的Open Assistant則排在第三。
清華提出的ChatGLM,雖然只有60億參數,但依然衝進了前五,只比130億參數的Alpaca落後了23分。
相比之下,Meta原版的LLaMa只排到了第八(倒數第二),而Stability AI的StableLM則獲得了唯一的800 分,排名倒數第一。
團隊表示,之後不僅會定期更新排位賽榜單,還會優化演算法和機制,並根據不同的任務類型提供更加細化的排名。

目前,所有的評估程式碼以及資料分析都已公佈。
拉著LLM打排位
在這次的評估中,團隊選擇了目前比較有名的9個開源聊天機器人。
每次1v1對戰,系統都會隨機拉兩個上場PK。使用者則需要同時和這兩個機器人聊天,然後決定哪個聊天機器人聊的更好。
可以看到,頁面下方有4個選項,左邊(A)比較好,右邊(B)比較好,一樣好,或是都很差。
當使用者提交投票之後,系統就會顯示模型的名稱。這時,使用者可以繼續聊天,或是選擇新的模型重新開啟一輪對戰。
不過,團隊在分析時,只會採用模型是匿名時的投票結果。在差不多一週的數據收集之後,團隊共收穫了4.7k個有效的匿名投票。
在開始之前,團隊先根據基準測試的結果,掌握了各個模型可能的排名。
根據這個排名,團隊會讓模型去優先選擇更合適的對手。
然後,再透過均勻取樣,來獲得對排名的更好整體覆蓋。
在排位賽結束時,團隊又引進了一個新模型fastchat-t5-3b。
以上這些操作最終導致了非均勻的模型頻率。
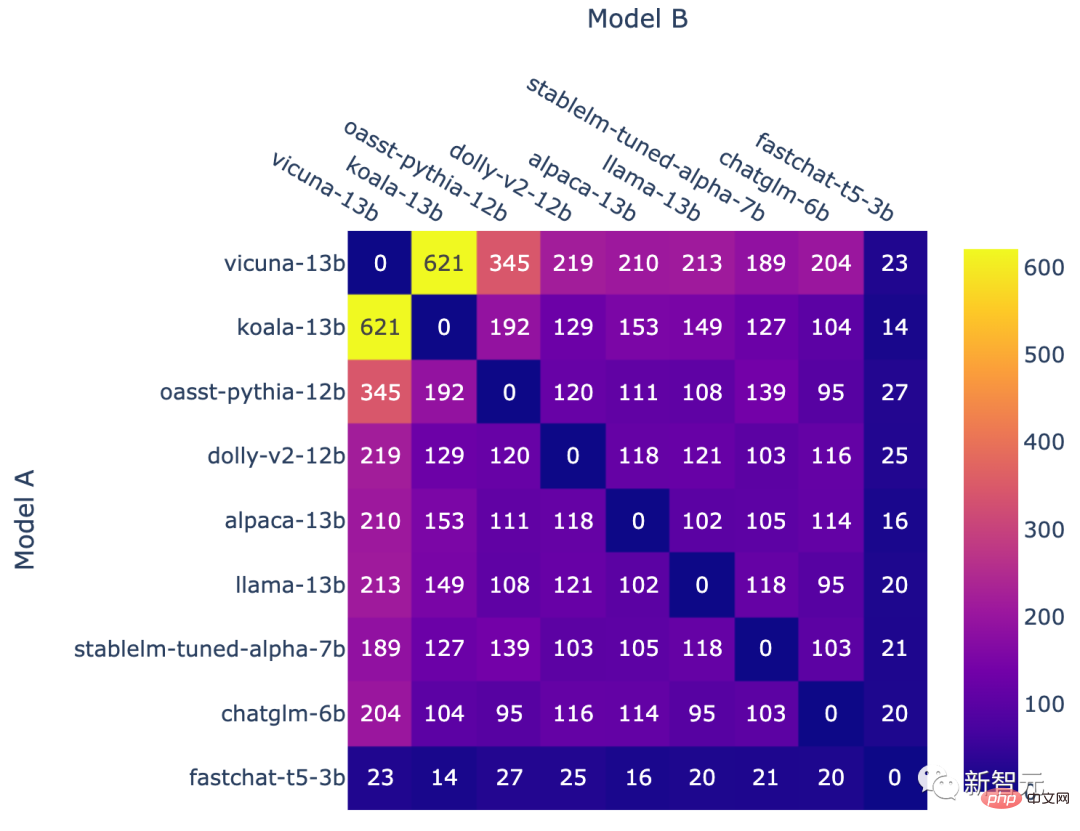
每個模型組合的對戰次數
從統計數據來看,大多數使用者所使用的都是英語,中文排在第二位。
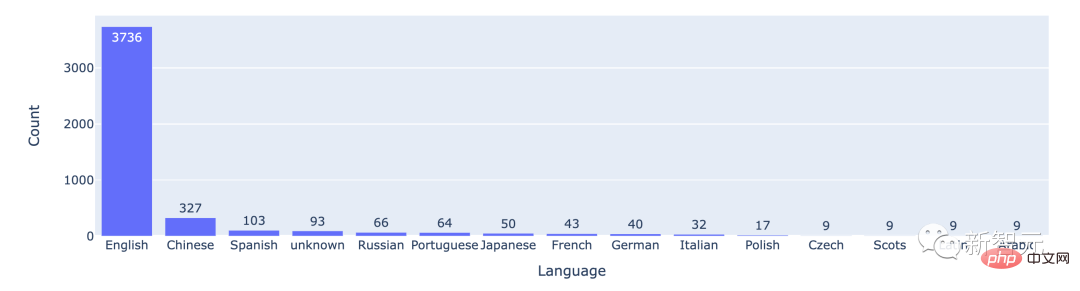
排名前15的語言的對戰次數
評估LLM,真的很難
自從ChatGPT爆火之後,經過指令跟隨微調的開源大語言模型如雨後春筍一般大量湧現。可以說,幾乎每週都有新的開源LLM在發布。
但問題是,評估這些大語言模型非常困難。
具體來說,目前用來衡量一個模型好不好的東西基本上都是基於一些學術的benchmark,例如在一個某個NLP任務上建立一個測試資料集,然後看測試資料集上準確率多少。
然而,這些學術benchmark(如HELM)在大模型和聊天機器人上就不好用了。原因在於:
1. 由於評判聊天機器人聊得好不好這件事是非常主觀的,因此現有的方法很難對其進行衡量。
2. 這些大模型在訓練的時候就幾乎把整個互聯網的資料都掃了一個遍,因此很難保證測試用的資料集沒有被看到過。甚至更進一步,用測試集直接對模型進行「特訓」,如此一來表現必然更好。
3. 理論上我們可以和聊天機器人聊任何事情,但很多話題或任務在現存的benchmark裡面根本就不存在。
那如果不想採用這些benchmark的話,其實還有一條路可以走──花錢請人給模型評分。
實際上,OpenAI就是這麼搞的。但是這個方法明顯很慢,而且更重要的是,太貴了…
為了解決這個棘手的問題,來自UC伯克利、UCSD、CMU的團隊發明了一種既好玩又實用的全新機制-聊天機器人競技場(Chatbot Arena)。
比較而言,基於對戰的基準系統具有以下優勢:
- 可擴展性(Scalability)
當不能為所有潛在的模型對收集足夠的資料時,系統應能擴展到盡可能多的模型。
- 增量性(Incrementality)
#系統應能使用相對較少的試驗次數評估新模型。
- 唯一順序(Unique order)
#系統應為所有模型提供唯一順序。給定任兩個模型,我們應該能夠判斷哪個排名較高或它們是否並列。
Elo評分系統
Elo等級分制度(Elo rating system)是一種計算玩家相對技能水平的方法,廣泛應用在競技遊戲和各類運動當中。其中,Elo評分越高,那就表示這個玩家越厲害。
例如英雄聯盟、Dota 2以及吃雞等等,系統給玩家進行排名的就是這個機制。
舉個例子,當你在英雄聯盟裡面打了很多場排位賽後,就會出現一個隱藏分數。這個隱藏分數不僅決定了你的段位,也決定了你打排位時碰到的對手基本上也是類似水平的。
而且,這個Elo評分的數值是絕對的。也就是說,當未來加入新的聊天機器人時,我們依然可以直接透過Elo的評分來判斷哪個聊天機器人比較厲害。
具體來說,如果玩家A的評分為Ra,玩家B的評分為Rb,玩家A獲勝機率的精確公式(使用以10為底的logistic曲線)為:

然後,玩家的評分會在每場對戰後線性更新。
假設玩家A(評分為Ra)預計會獲得Ea分,但實際獲得Sa分。更新該玩家評分的公式為:
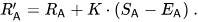
#1v1勝率
此外,作者也展示了排位賽中每個模型的對戰勝率以及使用Elo評分估算的預測對戰勝率。
結果顯示,Elo評分確實可以相對準確地進行預測
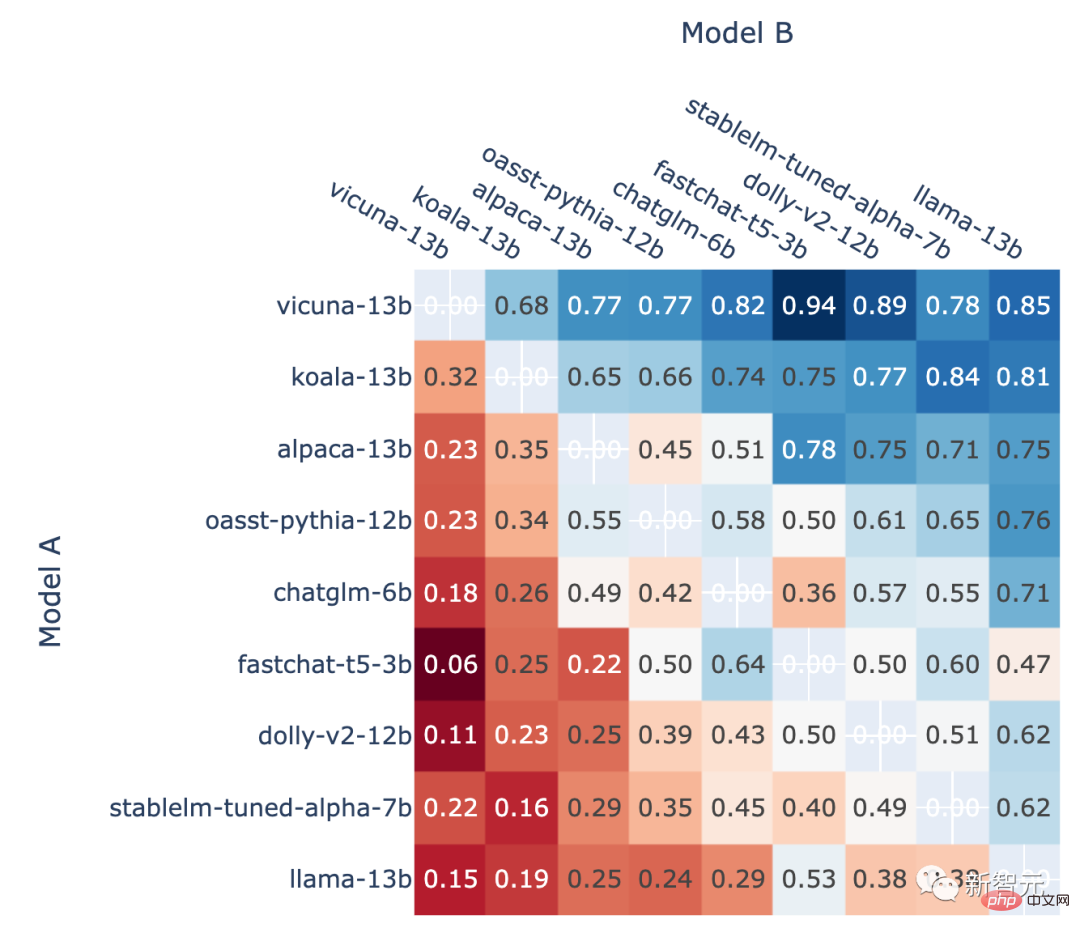
所有非平局A對B戰鬥中模型A勝利的比例
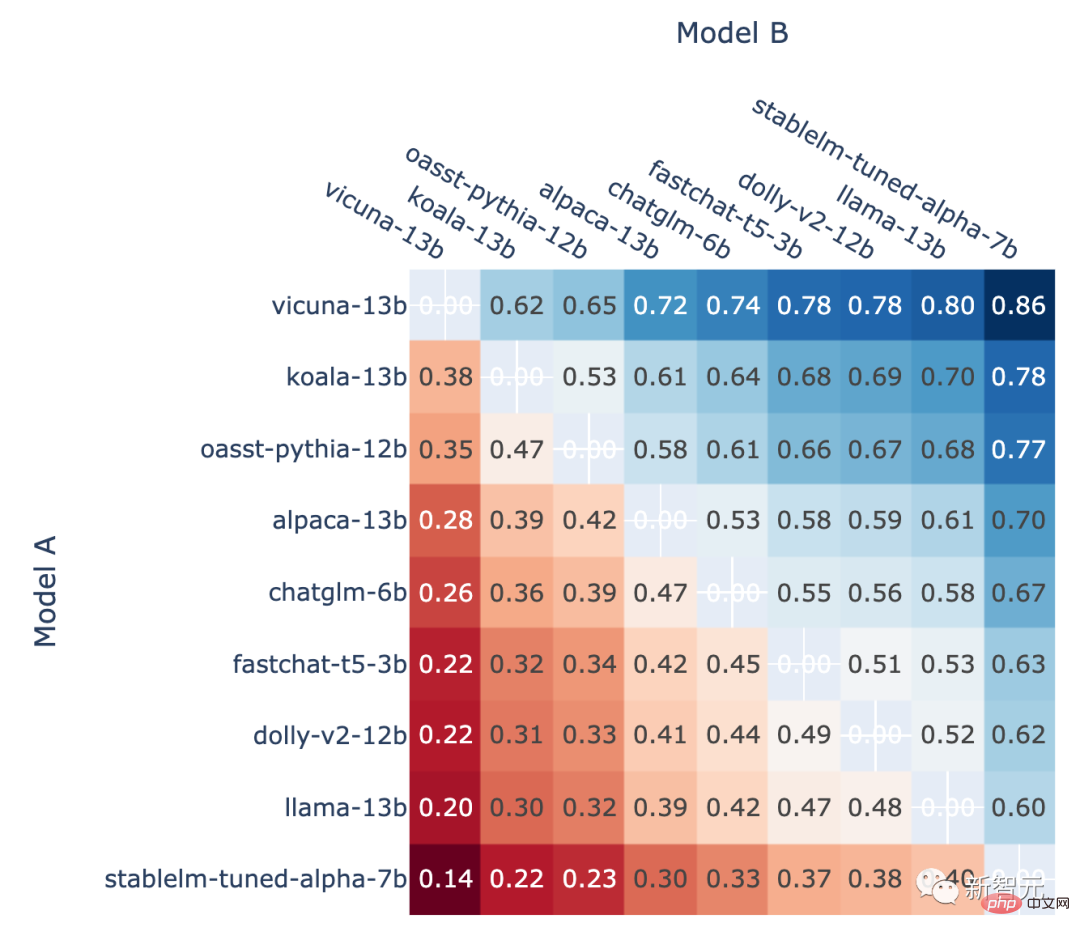
#在A對B戰鬥中,使用Elo評分預測的模型A的勝率
作者介紹
「聊天機器人競技場」由前小羊駝作者機構LMSYS Org發布。
該機構由UC伯克利博士Lianmin Zheng和UCSD準教授Hao Zhang創立,目標是透過共同開發開放的資料集、模型、系統和評估工具,使每個人都能獲得大型模型。
Lianmin Zheng
Lianmin Zheng是加州大學柏克萊分校EECS系的博士生,他的研究興趣包括機器學習系統、編譯器和分散式系統。
Hao Zhang
Hao Zhang目前是加州大學柏克萊分校的博士後研究員。他將於2023年秋季開始在加州大學聖地牙哥分校Halıcıoğlu資料科學研究所和電腦系擔任助理教授。
以上是UC伯克利發布大語模型排行榜! Vicuna奪冠,清華ChatGLM進前5的詳細內容。更多資訊請關注PHP中文網其他相關文章!