
「ChatGPT剋星」升級:老師可以把全班作業丟進去檢測了!華人作者:免費用

- 王林轉載
- 2023-05-04 19:25:041137瀏覽
“ChatGPT剋星”,升級了!
沒錯,就是之前華人小哥Edward Tian打造出來的那個GPTZero,幾秒內就能摸清文字是人類還是AI寫的。

而時隔近一個月,小哥所推出的版本名叫GPTZeroX,他也說:
這是專門為教育工作者打造的AI模型。
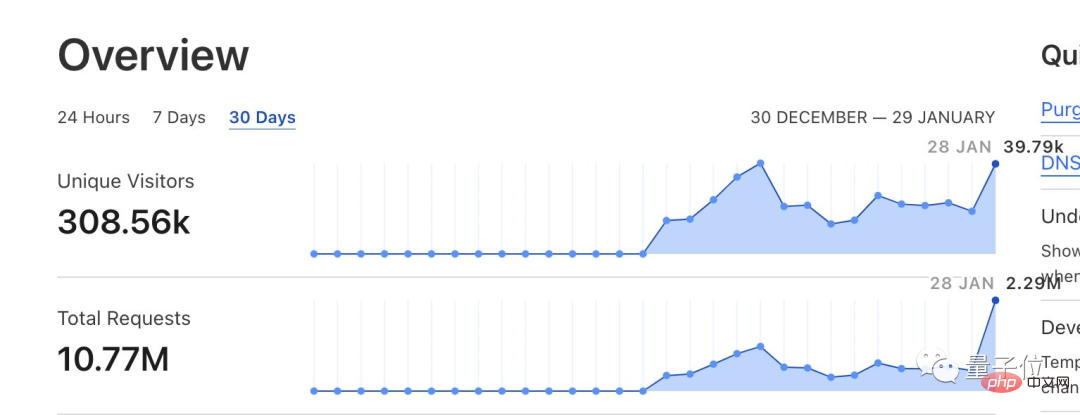
消息一出,立即吸引了大批網友湧入,一天之內便有40萬的訪問量和220萬的服務請求。
那麼這次,這位「ChatGPT剋星」又帶來了哪些新能力?
混合也能測,還支援Word等格式
#升級的一大特點,就是GPTZeroX可以偵測出來「人類 AI」混合的文字內容。
例如我們先把一段人類寫的新聞丟進去檢測:

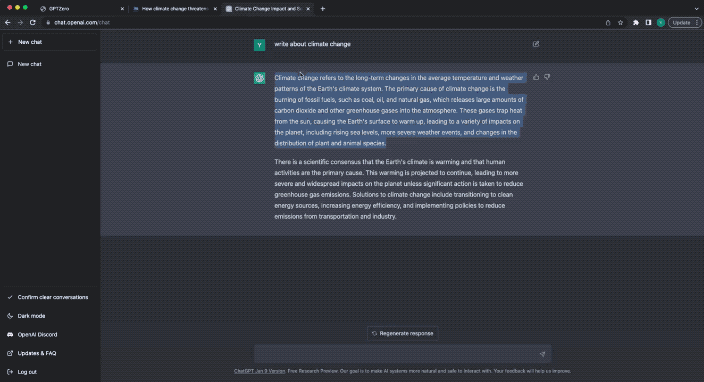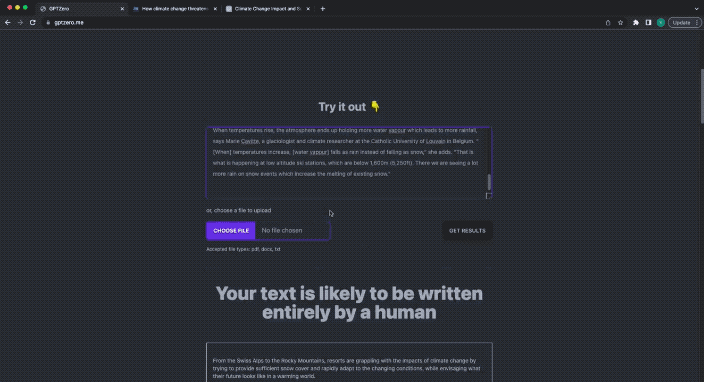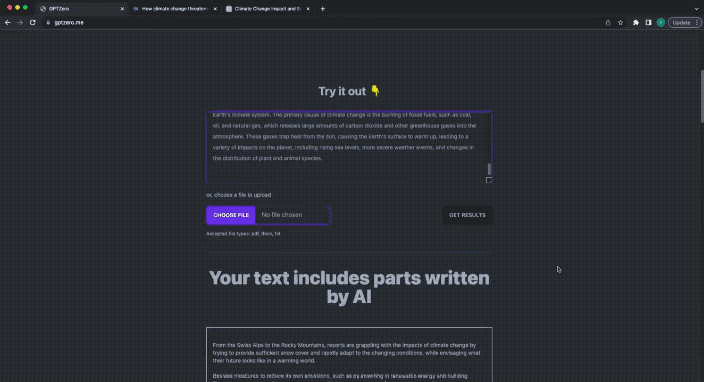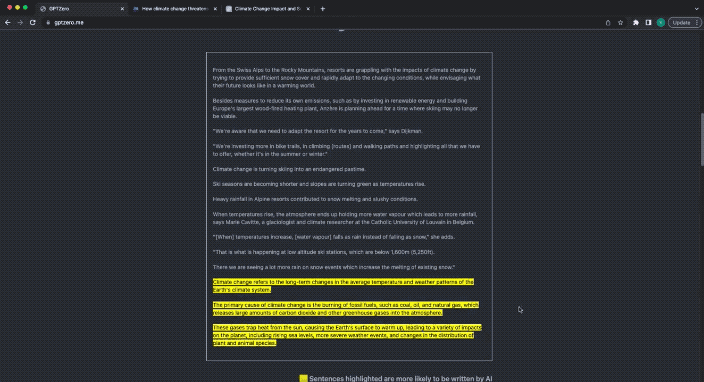
#GPTZeroX在短短幾秒鐘內,非常迅速的給出了答案:
Your text is likely to be written entirely by a human.
你的文字很可能完全是由人寫的。
接下來,我們再把一段ChatGPT寫的文字,丟進剛才那段新聞的後邊,來一場混合檢測:
這次,GPTZero給出的答案是:
Your text includes parts written by AI.
你的文字一部分是由AI編寫的。
並且ChatGPT產生的內容也會用黃色高亮標記出來。

小哥對此表示:
這是教育工作者一直想要的關鍵功能。
但老師們檢查學生作業的時候,一段一段的把文字複製貼上進來也相當繁瑣的工作了。
於是乎,這位小哥還貼心地推出了另一個新功能——可批量導入文件,支援Word、PDF和TXT等格式。
並且網站在介紹這個功能時,是這麼描述的

#:

除此之外,為了防止服務發生崩潰,小哥還搞了一個Python API,是已經完成壓力測試的那種。

最後,小哥還貼心地說了一句:
我承諾,本網站對個別教師和教育工作者,保持免費!
怎麼做到的?
它主要靠“perplexity”,即文本的“困惑度”作為指標來判斷所給內容到底是誰寫的。
NLP領域的朋友都知道,這個指標就是用來評價一個語言模型的好壞的。
在這裡,每當你餵給GPTZero一段測試內容,它就會分別計算出:
#1、文字總困惑度
這個值越高,就越可能出自人類之手。

2、所有句子的平均困惑度
句子越長,這個值通常就越低。

3、每個句子的困惑度
透過長條圖的方式呈現,滑鼠懸浮到各個方塊就可以查看對應的句子是什麼(這裡就兩塊,因為我此時輸入的測驗內容就倆句子)。
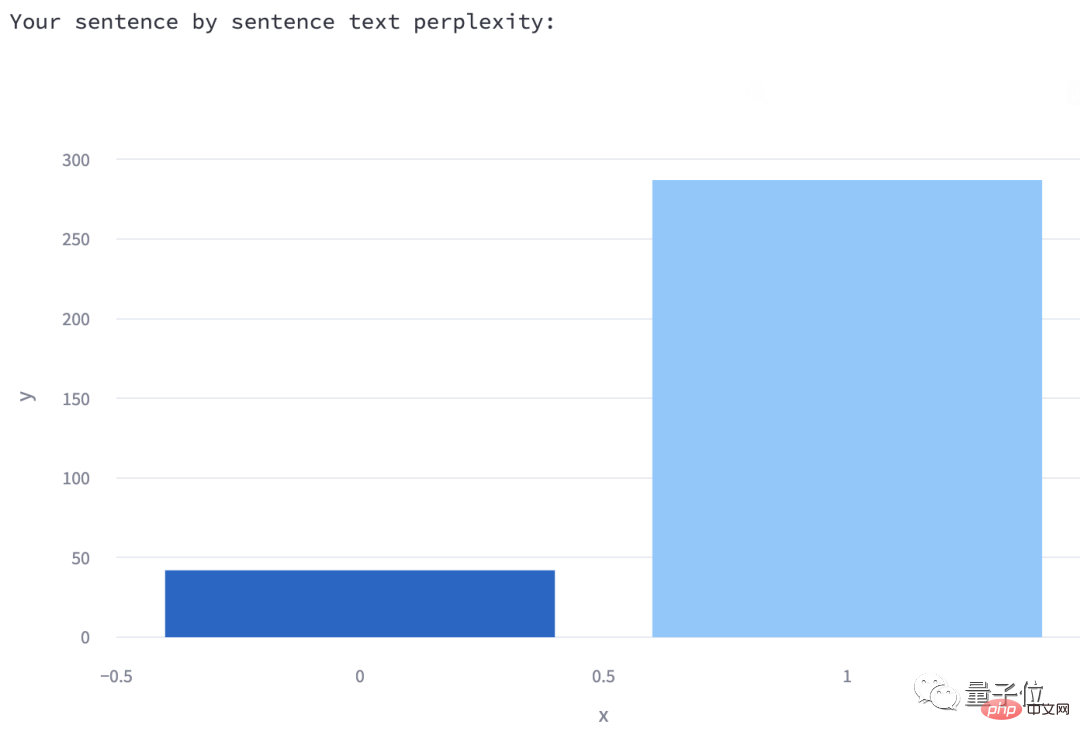
之所以要繪製這樣的長條圖,作者也做出了解釋:
根據最新的一些研究:人類書寫的一些句子可能具有較低的困惑度(前面說過,人類的困惑度是比較高的),但隨著繼續寫,困惑度勢必會出現峰值。
相反,用機器產生的文本,其困惑度是均勻分佈的,並且總是很低。
除此之外,GPTZero還會挑出困惑度最高的那個句子(也就是最像人寫的):

反ChatGPT之風正盛
正所謂道高一尺魔高一丈,在ChatGPT盡顯十八般武藝之際,諸如小哥GPTZero一樣「用魔法打敗魔法」的工具、研究也在層出不窮。
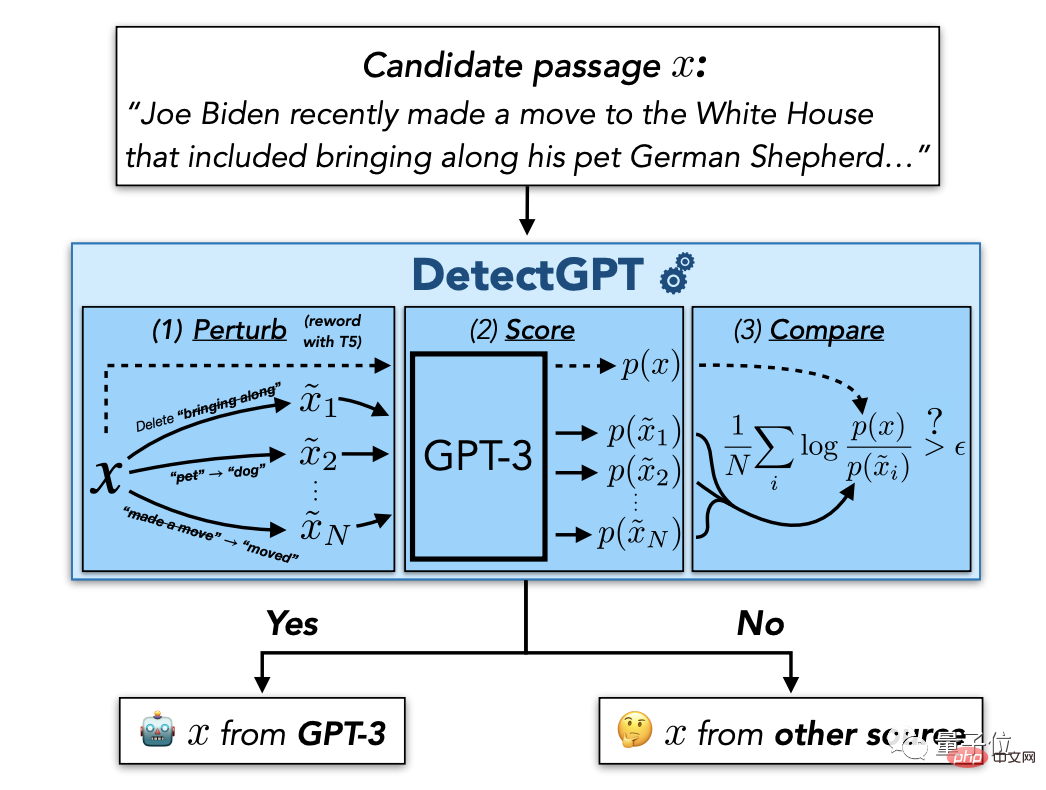
例如最近史丹佛大學為了不讓學生借助ChatGPT之力來寫論文或作弊,推出了「反偵察」神器-DetectGPT。

這種方法既不需要訓練單獨的分類器,也不需要收集真實或生成的段落的資料集,是一種基於機率曲率的零樣本方法。
除此之外,就連OpenAI自己也聯合哈佛等大學機構共同打造了一款偵測器:GPT-2 Output Detector。

作者們先是發布了一個「GPT-2生成內容」和WebText(專門從國外貼吧Reddit上扒下來的)資料集,讓AI理解「AI語言」和「人話」之間的差異。
隨後,用這個資料集對RoBERTa模型進行微調,就得到了這個AI偵測器。其中人話一律被辨識為True,AI生成的內容則一律被辨識為Fake。
(RoBERTa是BERT的改進版。原始的BERT使用了13GB大小的資料集,但RoBERTa使用了包含6300萬條英文新聞的160GB資料集。)
…
嗯,看來ChatGPT在大步向前邁的同時,順便也推動了「反ChatGPT」研究的發展。
參考連結:[1] https://twitter.com/edward_the6/status/1619874139954905090[2] https://arxiv.org/abs/2301.11305
以上是「ChatGPT剋星」升級:老師可以把全班作業丟進去檢測了!華人作者:免費用的詳細內容。更多資訊請關注PHP中文網其他相關文章!