
Redis Java連線的方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-04 14:52:061409瀏覽
一、Java連線池連線(管道,lua)
加入以下依賴
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version></dependency>
1、Test
public class Test {public static void main(String[] args) {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPoolConfig.setMinIdle(5);// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.157.6", 6379, 3000, null);Jedis jedis = null;try {// 从redis连接池里拿出一个连接执行命令jedis = jedisPool.getResource();System.out.println(jedis.set("single", "zhuge"));System.out.println(jedis.get("single"));// 管道示例// 管道的命令执行方式:cat redis.txt | redis‐cli ‐h 127.0.0.1 ‐a password ‐ p 6379 ‐‐pipePipeline pl = jedis.pipelined();for (int i = 0; i < 10; i++) {pl.incr("pipelineKey");pl.set("zhuge" + i, "zhuge");}List<Object> results = pl.syncAndReturnAll();System.out.println(results);// lua脚本模拟一个商品减库存的原子操作// lua脚本命令执行方式:redis‐cli ‐‐eval /tmp/test.lua , 10jedis.set("product_count_10016", "15"); // 初始化商品10016的库存String script = " local count = redis.call('get', KEYS[1]) " +" local a = tonumber(count) "+" local b = tonumber(ARGV[1]) " +" if a >= b then " +" redis.call('set', KEYS[1], count‐b) "+" return 1 " +" end " +" return 0 ";System.out.println("script:"+script);Object obj = jedis.eval(script, Arrays.asList("product_count_10016"), Arrays.asList("10"));System.out.println(obj);} catch (Exception e) {e.printStackTrace();} finally {// 注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedis != null)jedis.close();}}}
2、管道(Pipeline)
客戶端可以一次發送多個請求而不用等待伺服器的回應,待所有命令都發送完後再一次性讀取服務的回應,這樣可以極大的降低多條命令執行的網路傳輸開銷,管道執行多條指令的網路開銷其實只相當於一次指令執行的網路開銷。需要注意到是用pipeline方式打包指令發送,redis必須在處理完所有指令前先緩存起所有指令的處理結果。打包的命令越多,快取消耗記憶體也越多。所以並不是打包的命令越多越好。 pipeline中發送的每個command都會被server立即執行,如果執行失敗,將會在此後的回應中得到訊息;也就是pipeline並不是表達「所有command都一起成功」的語義,管道中前面命令失敗,後面命令不會有影響,繼續執行。
範例參考如上。
3、Redis Lua腳本
Redis在2.6推出了腳本功能,讓開發者使用Lua語言編寫腳本傳到Redis中執行。使用腳本的好處如下:
1、減少網路開銷
原本5次網路請求的操作,可以用一個請求完成,原先5次請求的邏輯放在redis伺服器上完成。使用腳本,減少了網路往返延遲。這點跟管道類似。
2、原子運算
Redis會將整個腳本當作一個整體執行,中間不會被其他指令插入。管道不是原子的,不過redis的批次操作指令(類似mset)是原子的。
3、替代redis的事務功能
redis自帶的事務功能很雞肋,報錯不支援回滾,而redis的lua腳本幾乎現了常規的事務功能,支援報錯回滾操作,官方推薦如果要使用redis的事務功能可以用redis lua取代。
官網文檔上有這樣一段話:
A Redis script is transactional by definition, so everything you can do with a Redis transaction, you can also do with a script,and usually the script will be both simpler and faster.
從Redis2.6.0版本開始,透過內建的Lua解釋器,可以使用EVAL指令對Lua腳本進行求值。 EVAL指令的格
式如下:
EVAL script numkeys key [key ...] arg [arg ...]
script參數是一段Lua腳本程序,它會被運行在Redis伺服器上下文中,這段腳本不必(也不應該)定義為一
個Lua函數。 numkeys參數用於指定鍵名參數的個數。鍵名參數key [key …] 從EVAL的第三個參數開始算
起,表示在腳本中所用到的那些Redis鍵(key),這些鍵名參數可以在Lua中通過全域變數KEYS數組,以1
為基址的形式存取( KEYS[1] , KEYS[2] ,以此類推)。在命令的最後,那些不是鍵名參數的附加參數arg [arg …] ,可以在Lua中通過全局變量ARGV數組訪問,訪問的形式和KEYS變量類似( ARGV[1] 、 ARGV[2] ,諸如此類) 。例如
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second2 1) "key1"3 2) "key2"4 3) "first"5 4) "second"
其中「return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}」 是求值的Lua腳本,數字2指定了鍵名參數的數
量, key1和key2是鍵名參數,分別使用KEYS[1] 和KEYS[2] 訪問,而最後的first 和second 則是附加
參數,可以透過ARGV[1] 和ARGV[2 ] 訪問它們。在 Lua 腳本中,可以使用redis.call()函數來執行Redis指令
範例參考如上。
注意,不要在Lua腳本中出現死循環和耗時的運算,否則redis會阻塞,將不接受其他的命令, 所以使用
時要注意不能出現死循環、耗時的運算。 redis是單一進程、單執行緒執行腳本。管道不會阻塞redis。
二、哨兵的Jedis連接程式碼
public class Test2 {public static void main(String[] args) {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPoolConfig.setMinIdle(5);String masterName = "mymaster";Set<String> sentinels = new HashSet<String>();sentinels.add(new HostAndPort("192.168.157.6",26379).toString());sentinels.add(new HostAndPort("192.168.157.6",26380).toString());sentinels.add(new HostAndPort("192.168.157.6",26381).toString());// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数JedisSentinelPool jedisSentinelPool = new JedisSentinelPool(masterName, sentinels, jedisPoolConfig, 3000, null);Jedis jedis = null;try {// 从redis连接池里拿出一个连接执行命令jedis = jedisSentinelPool.getResource();while(true) {Thread.sleep(1000);try {System.out.println(jedis.set("single", "zhuge"));System.out.println(jedis.get("single"));} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}}} catch (Exception e) {e.printStackTrace();} finally {// 注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedis != null)jedis.close();}}}
三、哨兵的Spring Boot整合Redis連接
1、引入相關依賴
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring‐boot‐starter‐data‐redis</artifactId></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons‐pool2</artifactId></dependency>
2、springboot專案核心配置
server:port: 8080spring:redis:database: 0timeout: 3000sentinel: #哨兵模式master: mymaster #主服务器所在集群名称nodes: 192.168.0.60:26379,192.168.0.60:26380,192.168.0.60:26381lettuce:pool:max‐idle: 50min‐idle: 10max‐active: 100max‐wait: 1000
3、存取程式碼
@RestControllerpublic class IndexController {private static final Logger logger = LoggerFactory.getLogger(IndexController.class);@Autowiredprivate StringRedisTemplate stringRedisTemplate;/*** 测试节点挂了哨兵重新选举新的master节点,客户端是否能动态感知到* 新的master选举出来后,哨兵会把消息发布出去,客户端实际上是实现了一个消息监听机制,* 当哨兵把新master的消息发布出去,客户端会立马感知到新master的信息,从而动态切换访问的masterip* @throws InterruptedException*/@RequestMapping("/test_sentinel")public void testSentinel() throws InterruptedException {int i = 1;while (true){try {stringRedisTemplate.opsForValue().set("zhuge"+i, i+"");System.out.println("设置key:"+ "zhuge" + i);i++;Thread.sleep(1000);}catch (Exception e){logger.error("错误:", e);}}}}
4、StringRedisTemplate與RedisTemplate
spring 封裝了RedisTemplate 物件來進行對redis的各種操作,它支援所有的redis 原生的api。在
RedisTemplate中提供了幾個常用的介面方法的使用,分別是:
private ValueOperations<K, V> valueOps;private HashOperations<K, V> hashOps;private ListOperations<K, V> listOps;private SetOperations<K, V> setOps;private ZSetOperations<K, V> zSetOps;
RedisTemplate中定義了對5種資料結構操作
redisTemplate.opsForValue();//操作字符串redisTemplate.opsForHash();//操作hashredisTemplate.opsForList();//操作listredisTemplate.opsForSet();//操作setredisTemplate.opsForZSet();//操作有序set
StringRedisTemplate繼承自RedisTemplate,也一樣擁有上面這些操作。
StringRedisTemplate預設採用的是String的序列化策略,而保存的key和value都是採用此策略序列化來保存
的。 RedisTemplate預設採用的是JDK的序列化策略,保存的key和value都是採用此策略序列化保存的。
也就是若是用RedisTemplate儲存的內容,你在控制台打開看到會是很多編碼後的字符,比較難理解。
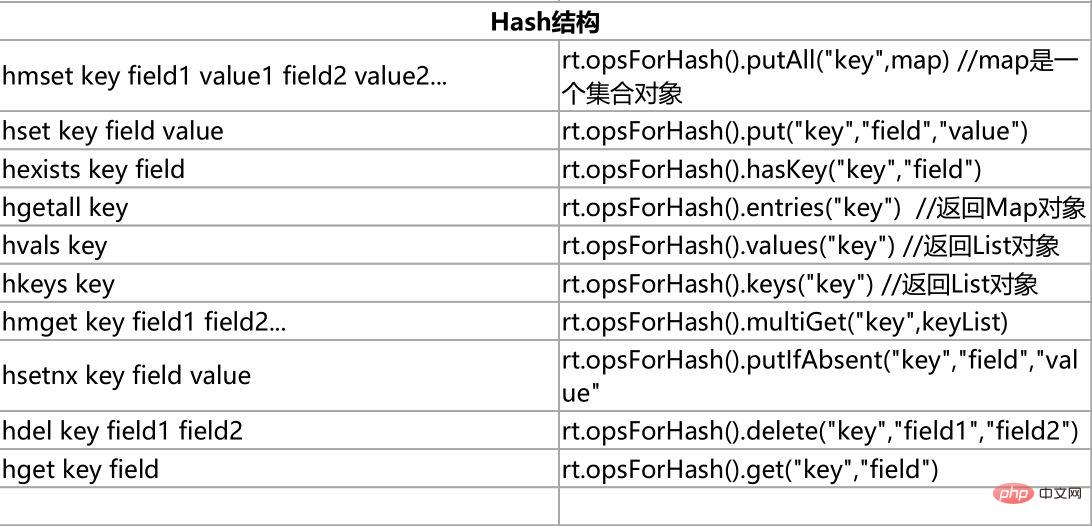
Redis客户端命令对应的RedisTemplate中的方法列表: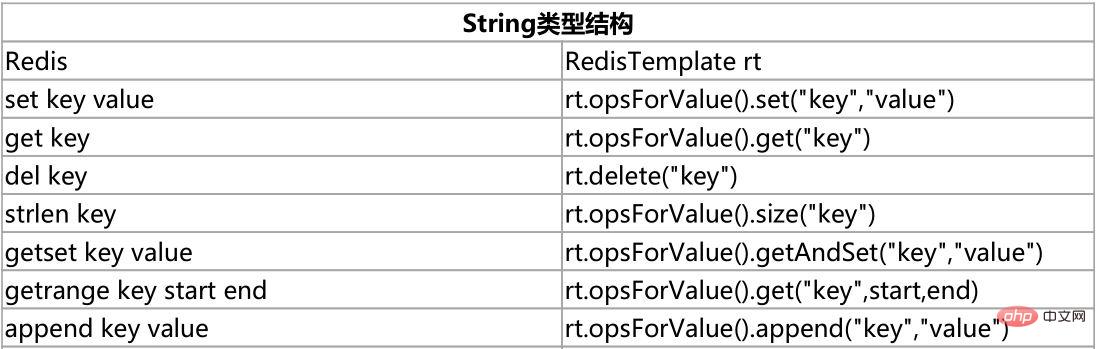


四、集群的Jedis连接代码
public class Test3 {public static void main(String[] args) throws IOException {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPoolConfig.setMinIdle(5);Set<HostAndPort> jedisClusterNode = new HashSet<HostAndPort>();jedisClusterNode.add(new HostAndPort("192.168.0.61", 8001));jedisClusterNode.add(new HostAndPort("192.168.0.62", 8002));jedisClusterNode.add(new HostAndPort("192.168.0.63", 8003));jedisClusterNode.add(new HostAndPort("192.168.0.61", 8004));jedisClusterNode.add(new HostAndPort("192.168.0.62", 8005));jedisClusterNode.add(new HostAndPort("192.168.0.63", 8006));// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数JedisCluster jedisCluster = new JedisCluster(jedisClusterNode, 6000, 5000, 10, "zhuge", jedisPoolConfig);try {while(true) {Thread.sleep(1000);try {System.out.println(jedisCluster.set("single", "zhuge"));System.out.println(jedisCluster.get("single"));} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}}} catch (Exception e) {e.printStackTrace();} finally {// 注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedisCluster != null)jedisCluster.close();}}}
五、集群模式Springboot整合redis
其实集群模式跟哨兵模式很类似,只不过配置文件修改一下即可
server:port: 8080spring:redis:database: 0timeout: 3000password: zhugecluster:nodes:192.168.0.61:8001,192.168.0.62:8002,192.168.0.63:8003lettuce:pool:# 连接池中的最大空闲连接max‐idle: 50# 连接池中最小空闲连接min‐idle: 10max‐active: 100# 连接池阻塞等待时间(负值表示没有限制)max‐wait: 1000
只不过 sentinel换成了 cluster,然后API什么的都是一样的。
以上是Redis Java連線的方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!