
從決策樹到Transformer——餐廳評論情感分析模型比較

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-04 12:31:061941瀏覽
譯者 | 朱先忠
#審查| 孫淑娟
。 ##本文字將展示各種#機器學習模型和嵌入技術對馬其頓餐廳評論情感分析的有效性
#, 探索並比較幾種經典的機器學習模型以及包括神經網路和
探索並比較幾種經典的機器學習模型以及包括神經網路和
# #Transformers在內的現代深度學習技術。 實驗表明,採用最新OpenAI嵌入的微調Transformers模型和深度學習模型遠 優於其他方法。 雖然用於自然語言處理的機器學習模型傳統上側重於如英語和西班牙語 等流行語言;但#是,在
方面其相關性機器學習模型的研究與應用
###要少得多。 ######另一方面######,隨著新冠肺炎疫情導致電子商務的興起,馬其頓語等不太常見的語言也透過線上評論產生了大量數據。這為開發和######訓練######馬其頓餐廳評論情感分析的機器學習模型提供了機會######;成功的話,######這可以幫助企業更好地了解客戶情感並改善######相關######服務。在這項研究中,我們解決了這個問題帶來的挑戰,並探索和比較了馬其頓餐廳評論中用於分析情緒的各種######情感分析模型######,從經典的隨機森林到現代深度學習技術和######Transformers######等#######。 ##################首先,我們給出本文內容的提綱:#############- 挑戰與資料預處理
- #建立向量嵌入
- LASER嵌入
- #多語言通用文字編碼器
- #OpenAI Ada v2
- #機器學習模型
- #隨機森林
- XGBoost
- 支援向量機
- 深度學習
- Transformers
- #結果與討論
- ##未來的工作
- #結論
預處理資料語言是一種獨特的人類交流工具,如果沒有適當的處理技術,計算機無法解釋語言。為了讓機器能夠分析和理解語言,我們需要以可計算處理的方式表示複雜的語意和詞彙資訊。實現這一點的一種流行方法是使用向量表示。近年來,除了特定語言的表示模型之外,還出現了多語言模型。這些模型可以捕捉大量語言上文字的語義上下文。
然而,對於使用西里爾#(Cyrillic)文字的語言,由於網路上的使用者經常使用拉丁文字來表達自己,從而產生了由拉丁文字和西里爾文字組成的混合數據;這樣一來,就#產生了一個額外的挑戰。為了應對這項挑戰,我使用了當地餐廳的資料集,其中包含大約500條評論——其中包含拉丁語和西里爾語腳本。數據集還包括一小部分英語評論,這將有助於評估混合數據的表現。此外,線上文字可能包含需要刪除的符號,例如表情符號。因此,在執行任何文字嵌入之前,預處理是至關重要的步驟。
import pandas as pd
import numpy as np
#把数据集加载进一个dataframe
df = pd.read_csv('/content/data.tsv', sep='t')
# 注意sentiment类别的分布情况
df['sentiment'].value_counts()
# -------
# 0 337
# 1 322
# Name: sentiment, dtype: int64注意到,資料集包含了分佈幾乎相等的正負類。為了刪除表情符號,我使用了Python庫emoji,它可以輕鬆刪除表情符號和其他符號。
!pip install emoji import emoji clt = [] for comm in df['comment'].to_numpy(): clt.append(emoji.replace_emoji(comm, replace="")) df['comment'] = clt df.head()對於西里爾文和拉丁文的問題,我將所有文字轉換為一種或另一種,這樣機器學習模型就可以在兩者上進行測試,以比較性能。我使用“cyrtranslit”庫執行此任務。它支援大多數西里爾字母,如馬其頓語、保加利亞語、烏克蘭語等。
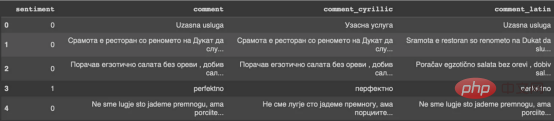
import cyrtranslit latin = [] cyrillic = [] for comm in df['comment'].to_numpy(): latin.append(cyrtranslit.to_latin(comm, "mk")) cyrillic.append(cyrtranslit.to_cyrillic(comm, "mk")) df['comment_cyrillic'] = cyrillic df['comment_latin'] = latin df.head()
#圖1:##轉換輸出
的結果
###############對於我使用的嵌入模型,通常不需要刪除標點符號、停止單字和進行其他文字清理。這些模型被設計用於處理自然語言文本,包括標點符號,當句子保持完整時,通常能夠更準確地捕捉句子的意思。這樣,文本的預處理就完成了。 ############矢量嵌入
目前,没有大规模的马其顿语言描述模型可用。然而,我们可以使用基于马其顿语文本训练的多语言模型。当前,有几种这样的模型可用,但对于这项任务,我发现LASER和多语言通用句子编码器是最合适的选择。
LASER
LASER(Language-Agnostic Sentence Representations)是一种生成高质量多语言句子嵌入的语言不可知方法。LASER模型基于两阶段过程。其中,第一阶段是对文本进行预处理,包括标记化、小写和应用句子。这部分是特定于语言的;第二阶段涉及使用多层双向LSTM将预处理的输入文本映射到固定长度的嵌入。
在一系列基准数据集上,LASER已经被证明优于其他流行的句子嵌入方法,如fastText和InferSent。此外,LASER模型是开源的,免费提供,使每个人都可以轻松访问。
使用LASER创建嵌入是一个简单的过程:
!pip install laserembeddings
!python -m laserembeddings download-models
from laserembeddings import Laser
#创建嵌入
laser = Laser()
embeddings_c = laser.embed_sentences(df['comment_cyrillic'].to_numpy(),lang='mk')
embeddings_l = laser.embed_sentences(df['comment_latin'].to_numpy(),lang='mk')
# 保存嵌入
np.save('/content/laser_multi_c.npy', embeddings_c)
np.save('/content/laser_multi_l.npy', embeddings_l)多语言通用句子编码器
多语言通用句子编码器(MUSE)是由Facebook开发的用于生成句子嵌入的预训练模型。MUSE旨在将多种语言的句子编码到一个公共空间中。
该模型基于深度神经网络,该网络使用“编码器-解码器”架构来学习句子与其在高维空间中的对应嵌入向量之间的映射。MUSE是在一个大规模的多语言语料库上训练的,其中包括维基百科的文本、新闻文章和网页。
!pip install tensorflow_text
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
import tensorflow_text
#加载MUSE模型
module_url = "https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3"
embed = hub.load(module_url)
sentences = df['comment_cyrillic'].to_numpy()
muse_c = embed(sentences)
muse_c = np.array(muse_c)
sentences = df['comment_latin'].to_numpy()
muse_l = embed(sentences)
muse_l = np.array(muse_l)
np.save('/content/muse_c.npy', muse_c)
np.save('/content/muse_l.npy', muse_l)OpenAI Ada v2
2022年底,OpenAI宣布了他们全新的最先进嵌入模型text-embedding-ada-002(https://openai.com/blog/new-and-improved-embedding-model/)。由于此模型基于GPT-3构建,因此具有多语言处理能力。为了比较西里尔文和拉丁语评论的结果,我决定在两个数据集上运行了模型:
!pip install openai
import openai
openai.api_key = 'YOUR_KEY_HERE'
embeds_c = openai.Embedding.create(input = df['comment_cyrillic'].to_numpy().tolist(), model='text-embedding-ada-002')['data']
embeds_l = openai.Embedding.create(input = df['comment_latin'].to_numpy().tolist(), model='text-embedding-ada-002')['data']
full_arr_c = []
for e in embeds_c:
full_arr_c.append(e['embedding'])
full_arr_c = np.array(full_arr_c)
full_arr_l = []
for e in embeds_l:
full_arr_l.append(e['embedding'])
full_arr_l = np.array(full_arr_l)
np.save('/content/openai_ada_c.npy', full_arr_c)
np.save('/content/openai_ada_l.npy', full_arr_l)机器学习模型
本节将探讨用于预测马其顿餐厅评论中情绪的各种机器学习模型。从传统的机器学习模型到深度学习技术,我们将研究每个模型的优缺点,并比较它们在数据集上的性能。
在运行任何模型之前,应该先对数据进行分割,以便针对每种嵌入类型进行训练和测试。这可以通过sklearn库轻松完成。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(embeddings_c, df['sentiment'], test_size=0.2, random_state=42)
随机森林
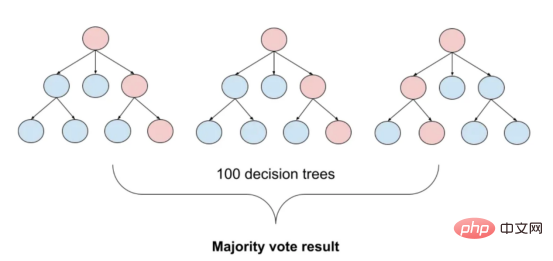
图2:随机森林分类的简化表示。构建100个决策树,并将结果作为每个决策树的结果之间的多数表决进行计算
随机森林是一种广泛使用的机器学习算法,它使用决策树集合对数据点进行分类。该算法通过在完整数据集的子集和特征的随机子集上训练每个决策树来工作。在推理过程中,每个决策树都会生成一个情绪预测,最终的结果是通过对所有树进行多数投票获得的。这种方法有助于防止过度拟合,并可导致更稳健和准确的预测结果。
from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report, confusion_matrix rfc = RandomForestClassifier(n_estimators=100) rfc.fit(X_train, y_train) print(classification_report(y_test,rfc.predict(X_test))) print(confusion_matrix(y_test,rfc.predict(X_test)))
XGBoost
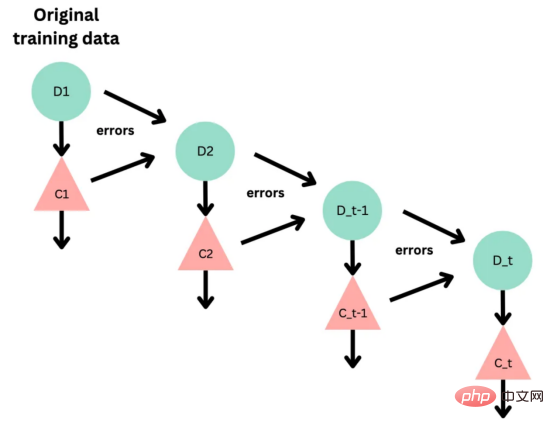
图3:基于boosting算法的顺序过程。每个下一个决策树都基于上一个决策的残差(误差)进行训练
XGBoost(极限梯度增强)是一种强大的集成方法,主要用于表格数据。与随机森林算法模型一样,XGBoost也使用决策树对数据点进行分类,但方法不同。XGBoost不是一次训练所有树,而是以顺序的方式训练每棵树,从上一棵树所犯的错误中学习。这个过程被称为“增强”,这意味着将弱模型结合起来,形成一个更强的模型。虽然XGBoost主要使用表格数据产生了很好的结果,但使用向量嵌入测试该模型也会很有趣。
from xgboost import XGBClassifier from sklearn.metrics import classification_report, confusion_matrix rfc = XGBClassifier(max_depth=15) rfc.fit(X_train, y_train) print(classification_report(y_test,rfc.predict(X_test))) print(confusion_matrix(y_test,rfc.predict(X_test)))
支持向量机
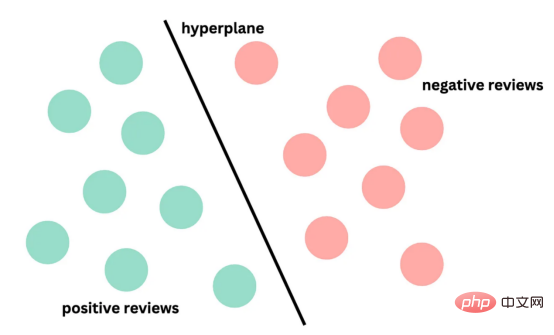
图4:支持向量分类的简化表示。在具有1024个输入特征的这种情绪分析的情况下,超平面将是1023维
支持向量机(SVM)是一种用于分类和回归任务的流行且强大的机器学习算法。它的工作原理是找到将数据分成不同类的最佳超平面,同时最大化类之间的边界。SVM对高维数据特别有用,可以使用核函数处理非线性边界。
from sklearn.svm import SVC from sklearn.metrics import classification_report, confusion_matrix rfc = SVC() rfc.fit(X_train, y_train) print(classification_report(y_test,rfc.predict(X_test))) print(confusion_matrix(y_test,rfc.predict(X_test)))
深度学习
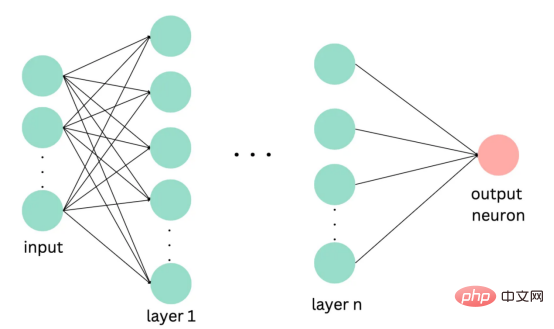
图5:此问题中使用的神经网络的简化表示
深度学习是一种先进的机器学习方法,它利用由多层和神经元组成的人工神经网络。深度学习网络在文本和图像数据方面表现出色。使用Keras库实现这些网络是一个很简单的过程。
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
model = keras.Sequential()
model.add(keras.layers.Dense(256, activatinotallow='relu', input_shape=(1024,)))
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(128, activatinotallow='relu'))
model.add(keras.layers.Dense(1, activatinotallow='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=11, validation_data=(X_test, y_test))
test_loss, test_acc = model.evaluate(X_test, y_test)
print('Test accuracy:', test_acc)
y_pred = model.predict(X_test)
print(classification_report(y_test,y_pred.round()))
print(confusion_matrix(y_test,y_pred.round()))在此,使用了具有两个隐藏层和校正线性单元(ReLU)激活函数的神经网络。输出层包含一个具有S形激活函数的神经元,使网络能够对积极或消极情绪进行二元预测。二元交叉熵损失函数与S形激活配对以训练模型。此外,Dropout被用于帮助防止过度拟合和改进模型的泛化。我用各种不同的超参数进行了测试,发现这种配置最适合这个问题。
通过以下函数,我们可以可视化模型的训练。
import matplotlib.pyplot as plt
def plot_accuracy(history):
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()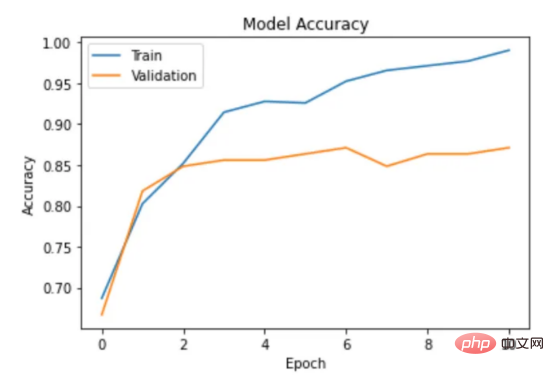
图6:示例训练输出
Transformers
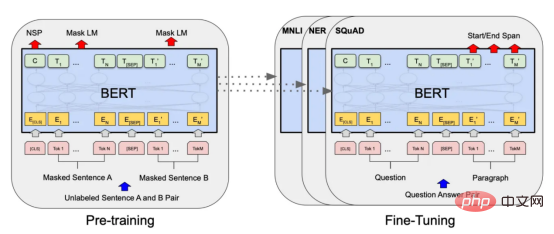
图7:BERT大型语言模型的预训练和微调过程。(BERT原始论文地址:https://arxiv.org/pdf/1810.04805v2.pdf)
微调Transformers是自然语言处理中的一种流行技术,涉及调整预先训练的变换器模型以适应特定任务。Transformers,如BERT、GPT-2和RoBERTa,在大量文本数据上进行了预训练,能够学习语言中的复杂模式和关系。然而,为了在特定任务(如情绪分析或文本分类)上表现良好,需要根据任务特定数据对这些模型进行微调。
对于这些类型的模型,不需要我们之前创建的向量表示,因为它们直接处理标记(直接从文本中提取)。在马其顿语的情绪分析任务中,我使用了bert-base-multilingual-uncased,这是BERT模型的多语言版本。
HuggingFace使微调Transformers成为一项非常简单的任务。首先,需要将数据加载到Transformers数据集中。然后将文本标记化,最后训练模型。
from sklearn.model_selection import train_test_split
from datasets import load_dataset
from transformers import TrainingArguments, Trainer
from sklearn.metrics import classification_report, confusion_matrix
# 创建由数据集加载的训练和测试集的csv文件
df.rename(columns={"sentiment": "label"}, inplace=True)
train, test = train_test_split(df, test_size=0.2)
pd.DataFrame(train).to_csv('train.csv',index=False)
pd.DataFrame(test).to_csv('test.csv',index=False)
#加载数据集
dataset = load_dataset("csv", data_files={"train": "train.csv", "test": "test.csv"})
# 标记文本
tokenizer = AutoTokenizer.from_pretrained('bert-base-multilingual-uncased')
encoded_dataset = dataset.map(lambda t: tokenizer(t['comment_cyrillic'], truncatinotallow=True), batched=True,load_from_cache_file=False)
# 加载预训练的模型
model = AutoModelForSequenceClassification.from_pretrained('bert-base-multilingual-uncased',num_labels =2)
#微调模型
arg = TrainingArguments(
"mbert-sentiment-mk",
learning_rate=5e-5,
num_train_epochs=5,
per_device_eval_batch_size=8,
per_device_train_batch_size=8,
seed=42,
push_to_hub=True
)
trainer = Trainer(
model=model,
args=arg,
tokenizer=tokenizer,
train_dataset=encoded_dataset['train'],
eval_dataset=encoded_dataset['test']
)
trainer.train()
# 取得预测结果
predictions = trainer.predict(encoded_dataset["test"])
preds = np.argmax(predictions.predictions, axis=-1)
# 评估
print(classification_report(predictions.label_ids,preds))
print(confusion_matrix(predictions.label_ids,preds))因此,我们成功地调整了BERT进行情绪分析。
实验结果与讨论
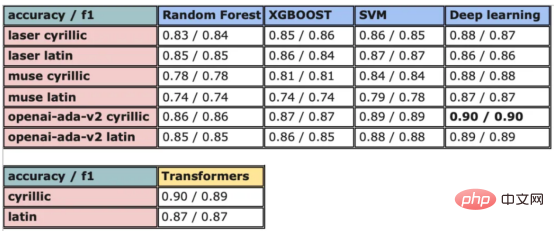
图8:所有模型的结果大对比
实验证明,马其顿餐厅评论的情绪分析结果是很有希望的,从上图中可见,其中有几个模型获得了很高的准确性和F1分数。实验表明,深度学习模型和变换器的性能优于传统的机器学习模型,如随机森林和支持向量机,尽管相差不大。使用新OpenAI嵌入的Transformers和深度神经网络成功打破了0.9精度的障碍。
OpenAI嵌入模型textembedding-ada-002成功地极大提高了从经典ML模型获得的结果,尤其是在支持向量机上。本研究中的最佳结果是在深度学习模型上嵌入西里尔文文本。
一般来说,拉丁语文本的表现比西里尔语文本差。尽管我最初假设这些模型的性能会更好,但考虑到拉丁语中类似单词在其他斯拉夫语言中的流行,以及嵌入模型是基于这些数据训练的事实,这些发现并不支持这一假设。
未來的工作
在未來的工作中,收集更多的數據以進一步訓練和測試模型是非常有價值的,尤其是在審查主題和來源更為多樣化的情況下。此外,嘗試將元資料(例如審查者的年齡、性別、位置)或時間資訊(例如審查時間)等更多特徵納入模型可能會提高其準確性。最後,將分析擴展到其他不太常用的語言,並將模型的性能與馬其頓評論中訓練的模型進行比較,這也#將是很有趣的。
結論
這篇文章展示了各種##流行機器學習模型和嵌入技術對馬其頓餐廳評論情緒分析的有效性。探索並比較了幾種經典的機器學習模型,如隨機森林和SVM,以及包括神經網路和Transformers在內的現代深度學習技術。結果表明,採用最新OpenAI嵌入的微調Transformers模型和深度學習模型優於其他方法,驗證準確率高達90%。
譯者介紹朱先忠,51CTO社群編輯,51CTO專家部落格、講師,濰坊一所高校電腦教師,自由編程界老兵一枚。
原文標題:#From Decision Trees to Transformers: Comparing Sentiment Analysis Models for Macedonian Restaurant Reviews #,作者:Danilo Najkov
以上是從決策樹到Transformer——餐廳評論情感分析模型比較的詳細內容。更多資訊請關注PHP中文網其他相關文章!