
隱私計算在大數據AI領域的應用實踐

- 王林轉載
- 2023-04-28 15:13:061631瀏覽
01 隱私權計算的背景與現況
1.隱私權計算的背景


##隱私計算目前已成為剛需。一方面,個人使用者對個人隱私和資訊安全的需求變強了。另一方面,有大量隱私權安全相關的法律法規發布,例如歐盟的GDPR,美國的CCPA和國內的個人資訊保護法等,法規政策也逐漸從寬鬆走向嚴格,主要體現在權力權益、執行範圍和執行力度等方面。以GDPR為例,自2018年生效後,已出現了1,000多個判例,罰款總額超過110億,單筆最高罰款超過50億(Amazon)。

#2. 隱私權計算的現狀
在這樣的大背景下,資料安全性從可選項變成了必選項。這導致大量企業、投資、新創公司和從業人員投入安全和隱私技術的生態中,學術界更是針對工業界的需求進行許多前瞻性的探索。這些因素促使近年來安全和隱私技術和生態蓬勃發展,其中的差分隱私、可信任執行環境、同態加密、安全多方計算和聯邦學習等技術都得到了長足發展。 Gartner 對這一領域的發展也秉持樂觀的態度,認為其在未來將會是一個百億甚至千億的市場。
#02 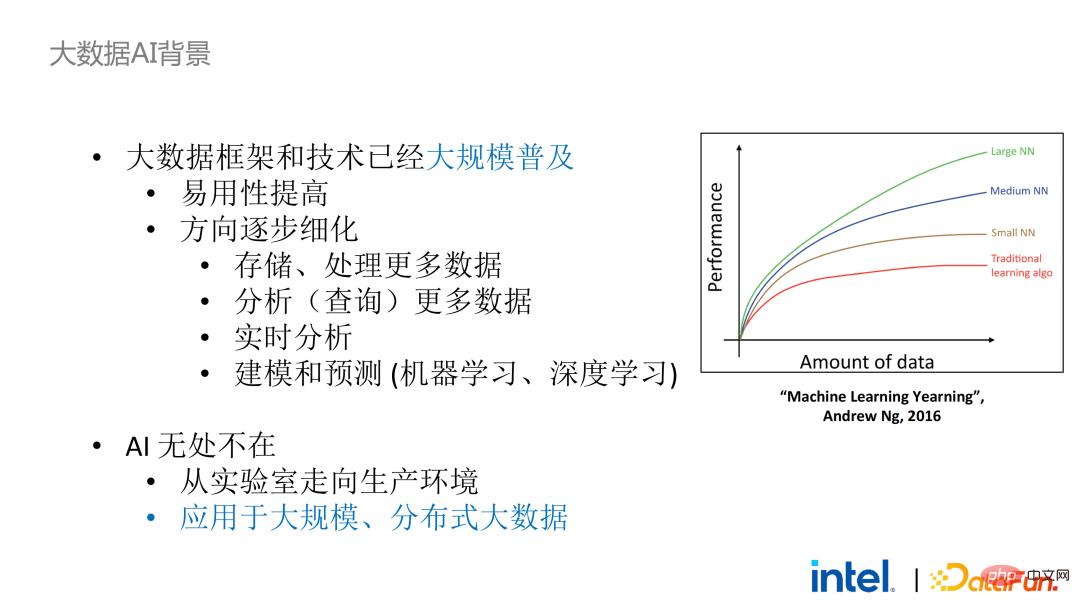 大數據AI 隱私權計算
大數據AI 隱私權計算
#回到大數據AI這個背景,從產業的宏觀角度來看,大數據框架和技術已經大規模商用和普及。我們可能每時每刻都在使用大數據的技術,但我們卻感受不到程式和模型訓練是跑在一個上千甚至上萬節點的伺服器叢集和大規模資料上。近年來,該領域的發展方向有兩個新趨勢:一是易用性的提高,二是應用方向的細化。前者大大降低的大數據技術的使用門檻,而後者不斷為新出現的需求和問題提供新的解決方案,例如資料湖等。
 從與AI框架的結合來看,現在大數據和AI生態是緊密結合的。因為對於AI模型來說,資料量越大、品質越高,模型的訓練效果就越好,所以大數據和AI這兩個領域會天然地結合在一起。
從與AI框架的結合來看,現在大數據和AI生態是緊密結合的。因為對於AI模型來說,資料量越大、品質越高,模型的訓練效果就越好,所以大數據和AI這兩個領域會天然地結合在一起。
2. 大數據AI 隱私計算
兩年前,在和行業內大數據及AI應用相關的客戶溝通的過程中,我們收集到了一些用戶痛點。除了常規的效能問題之外,大多數客戶關心的第一個問題是相容性問題。例如,有些客戶已經有了數千甚至上萬節點的集群,如果需要將其中的部分模組或者環節進行安全處理,應用隱私計算的技術從而實現隱私保護的功能,則可能需要對現有應用進行更改,甚至引入一些全新的框架或基礎設施,這些衝擊是客戶需要考慮的首要問題。其次,客戶會考慮資料規模對安全技術的影響,希望引入的新框架和技術能夠支援大規模資料的計算且具有較高的計算效率。最後客戶才會考慮聯邦學習技術是否能解決資料孤島的問題。

基於研究得出的客戶需求,我們推出了BigDL PPML方案,其首要目標是讓常規的、標準的大數據及AI方案能在安全環境中運行,確保端到端都是安全的。為此,計算過程需要被SGX(硬體級的TEE)保護。同時,需要確保儲存和網路被加密,整個連結需要進行遠端證明(也稱為遠端簽鑑),確保運算的機密性和完整性。
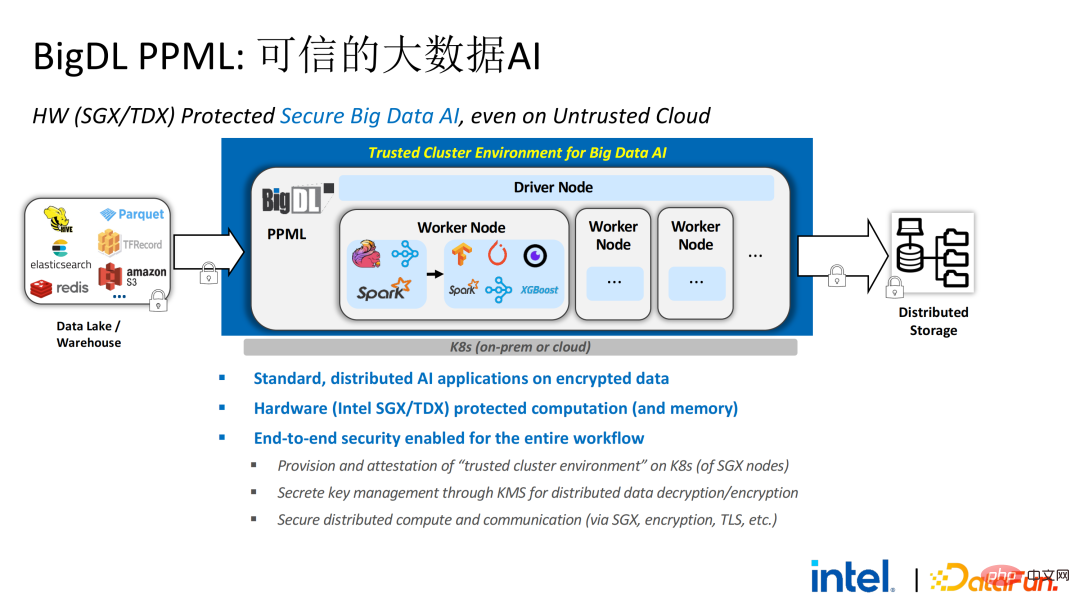
#接下來我們以Apache Spark這一常用的大資料框架為例詳細闡述此方案的必要性。 Apache Spark是大數據AI領域比較常用的分散式運算框架,它已經有很多與安全相關的功能了,例如,網路方面可以進行加密和認證,通訊和RPC都被TLS和AES保護;儲存方面主要涉及本地shuffle存儲,也採用AES保護;但計算方面存在較大的問題,因為即使是最新版本的Spark也只能進行明文計算。萬一運算環境或節點被攻破,其就能取得大量敏感資料。
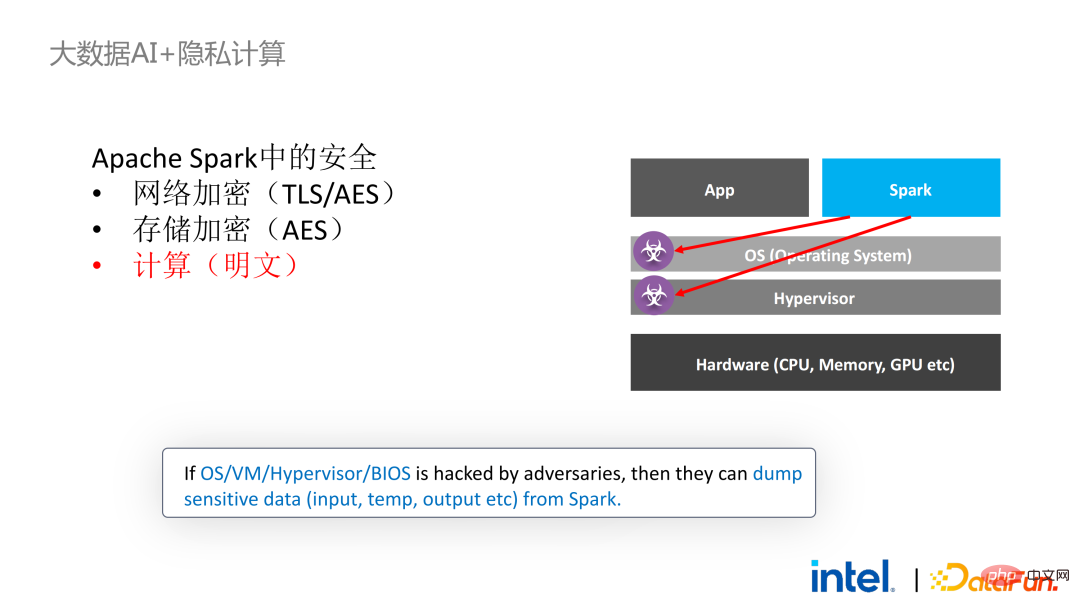
SGX技術是以Intel CPU為底層設施的軟硬體結合的可信任運算環境技術,它具有:
- 硬體級的可信執行環境
- 相對小的攻擊面:即使部分系統已經被攻破,只要CPU是安全的就能夠確保整個程式的安全性
- 效能影響小
- #夠大的飛地(最大1TB)
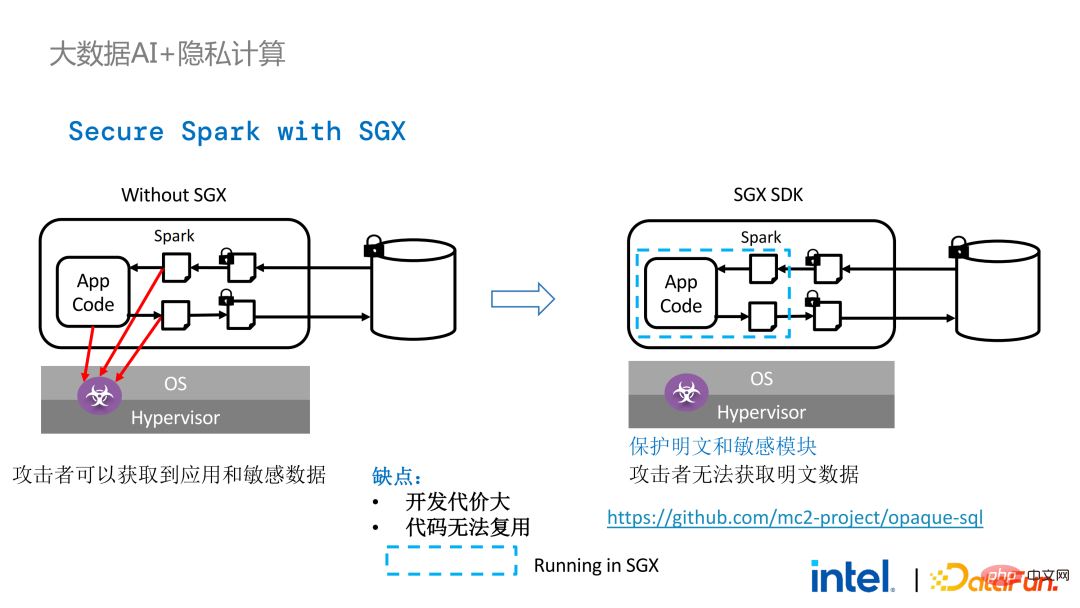
回到先前提到的Apache Spark這個應用場景:
#左邊是計算環境沒有受到保護的情況,即使使用了加密存儲,只要在明文計算階段遭到攻擊,就會有資料外洩的風險;右邊則是Spark社群的一些嘗試,透過把SparkSQL相關的一些關鍵步驟提取出來,用SGX SDK重寫這部分邏輯,既能夠實現性能的最大化,又能實現攻擊面最小化。但這方法缺點也很明顯,就是開發代價太大,成本太高。重新SparkSQL核心邏輯,需要對Spark有清晰明確的認知;同時,程式碼無法重複使用到其他專案。
#
為了解決上述提到的缺點,我們使用了LibOS方案 ,簡而言之就是透過LibOS這個中間層,降低開發與遷移的難度,將系統API的呼叫轉換成SGX SDK能夠辨識的形式,以實現一些常規應用的無縫遷移。常見的LibOS解決方案有螞蟻集團的Occlum、英特爾參與的Gramine以及帝國理工主導的sgx-lkl方案等。以上LibOS都有各自的特性和優勢,它們透過不同的方式解決了SGX的易用性和易遷移性的問題。
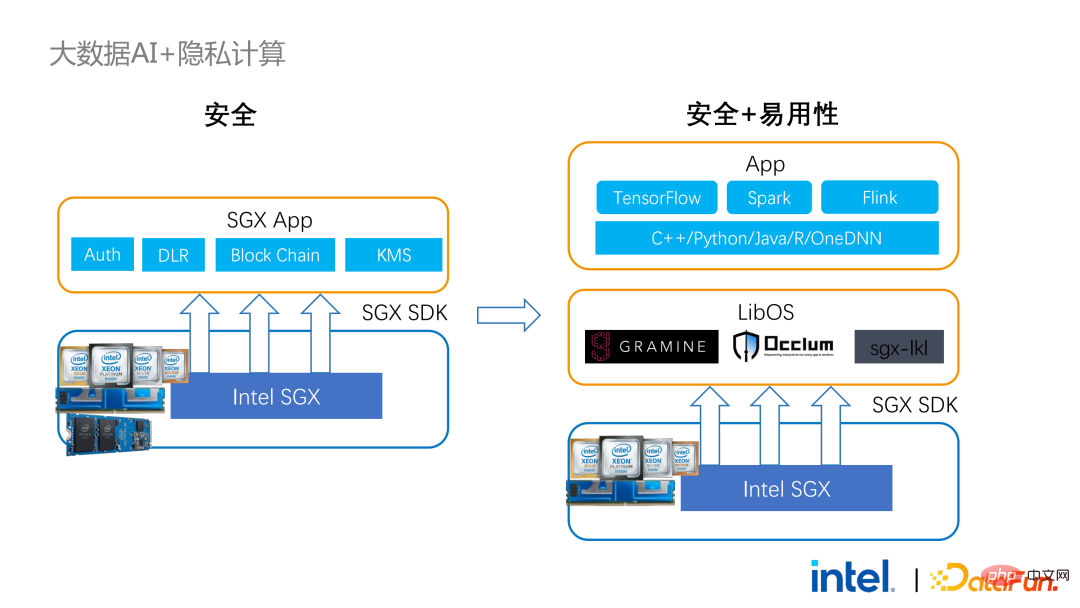
#有了LibOS就不再需要重寫Spark中的核心邏輯,而是能夠透過LibOS將整個Spark放入SGX中,同時無需修改Spark和現有應用。
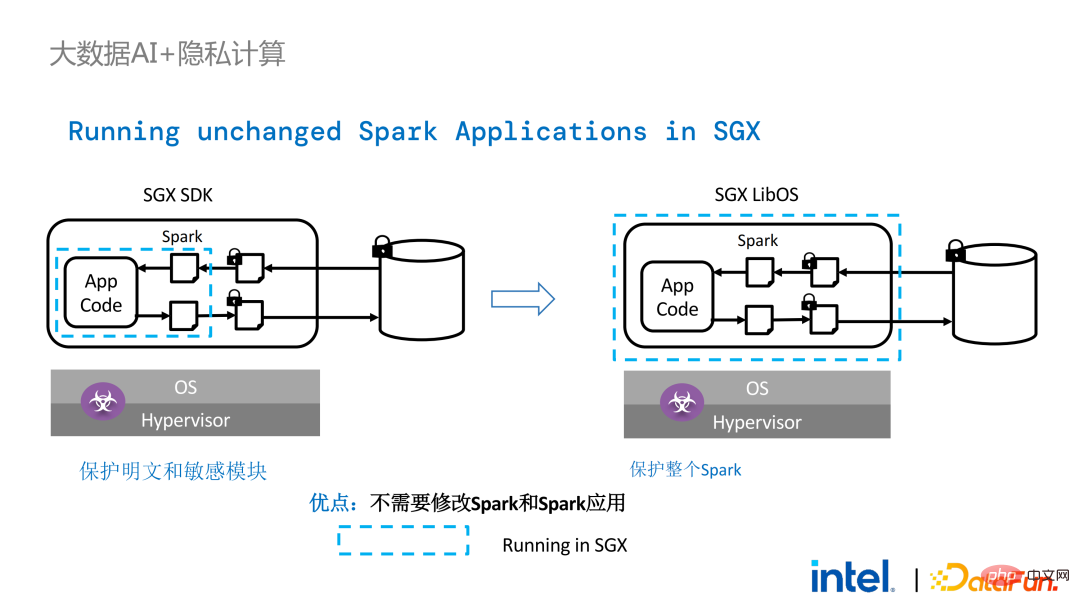
#在Spark的分散式計算中,可以將分散式中的各個模組分別用LibOS和SGX保護,存儲端可以配置密鑰管理和加密存儲,executor獲取密文數據後在SGX中解密併計算。整個流程對開發人員較為無感,對現有應用的衝擊較少。
不過,與單機應用程式相比,分散式應用程式中的安全性問題也更為複雜。攻擊者可能會將部分運行節點攻破,或與資源管理節點形成共謀,從而以惡意的運行環境取代SGX環境。這樣就能非法取得密鑰和加密數據,並最終造成隱私資料外洩。
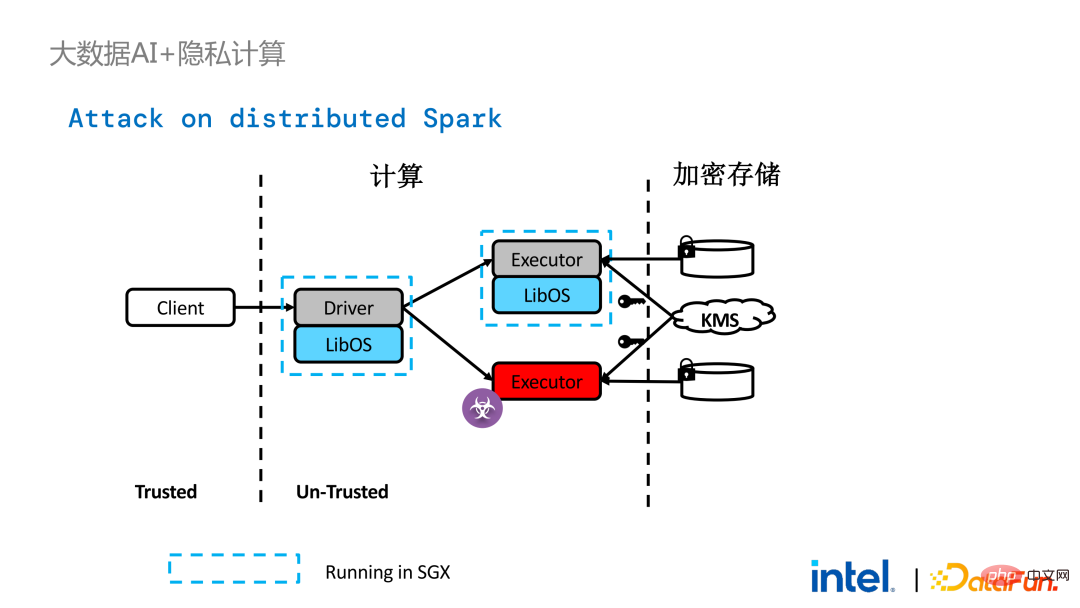
為了解決這問題,需要應用遠端證明技術。簡單來說,就是跑在SGX中的應用程式可以提供證明或證書,而該證明或證書是不可竄改的。證書能夠證實該應用程式是否在SGX中運作、套用是否被竄改,平台是否符合安全標準等。
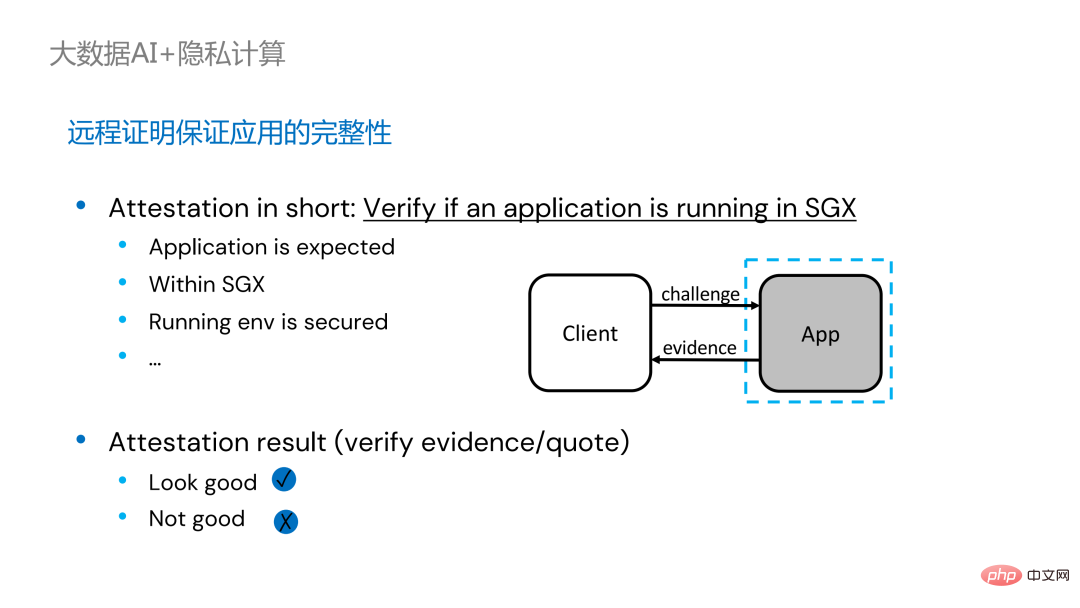
為分散式應用程式加入遠端證明存在兩種實作方式。左邊是一套比較完備但改動較大的方案,在driver端和executor端互相做遠端證明,需要對Spark做一定程度的修改。另一種方案則透過第三方的遠端證明伺服器實現集中式的遠端證明,並使用不可變更的憑證阻斷被攻擊者控制的模組來取得資料。第二種方案不需要修改應用程序,只需對小部分啟動腳本進行修改即可。
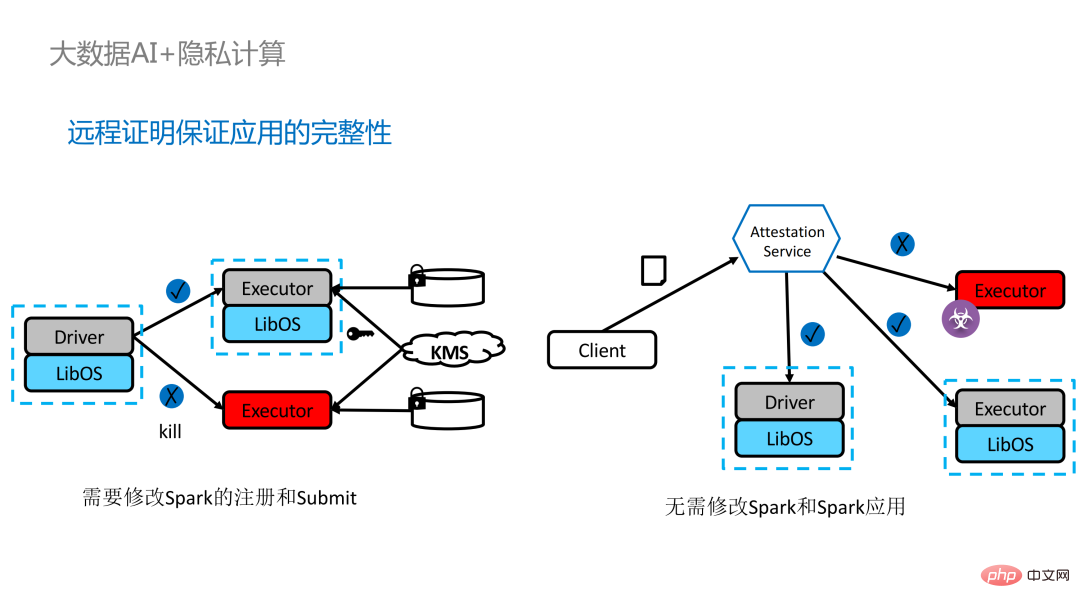
雖然LibOS可以讓Spark運行在SGX中,但進行Spark的LibOS和SGX適配依舊需要花費一定人力和時間成本。 為此我們推出了PPML的一站式解決方案,其中許多步驟都能實現自動化處理,並且實現無縫遷移,大大減少遷移成本。
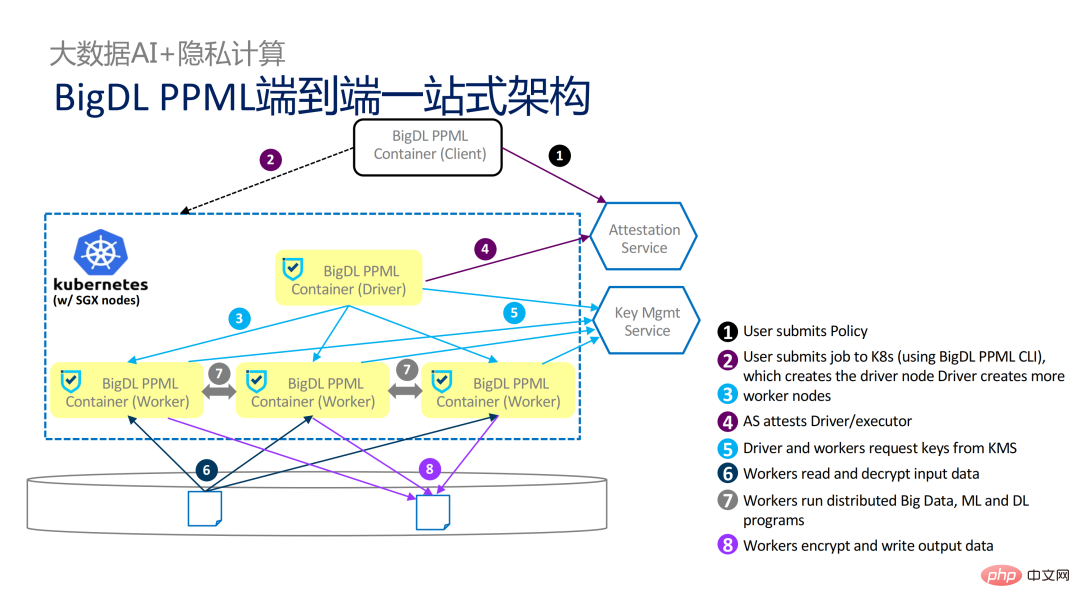
從工作流程的角度來說,此方案還有另一個優點,即資料科學家感知不到底層的變化,只有叢集管理員需要參與SGX的部署和準備工作,資料科學家可以正常地進行建模和查詢工作,完全感知不到底層的環境已經改變了。這樣就可以很好地解決現有應用的兼容性和遷移問題,也不會阻礙資料科學家和開發人員的日常工作。
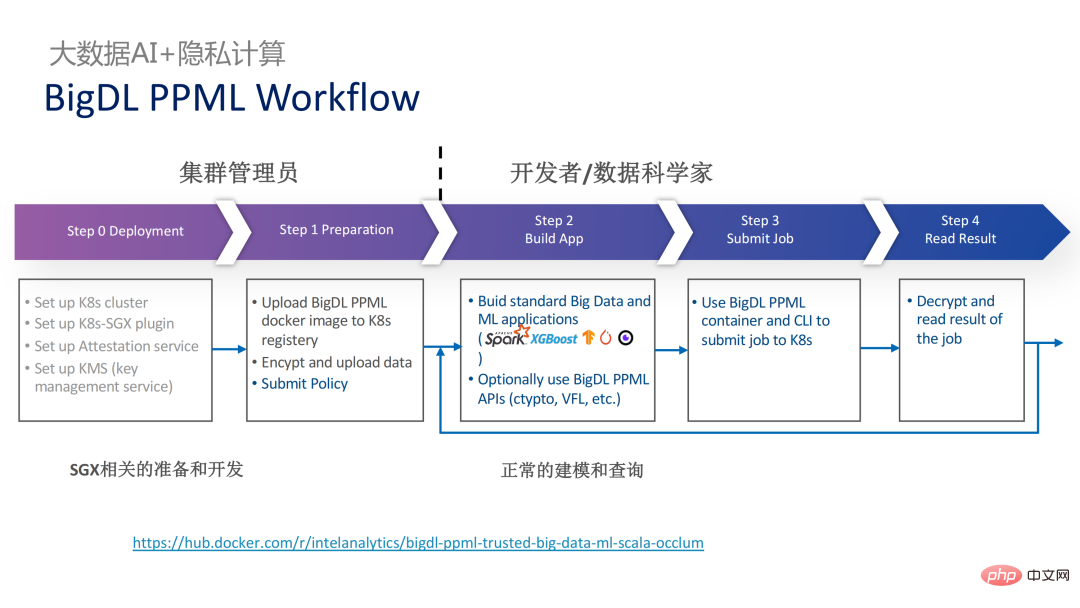
以下是整個PPML方案的全貌。為了滿足客戶的不同需求,在最近這兩年內PPML支援的功能也不斷拓展。例如,中間層Library and Framework中,Spark、Flink和Ray等常用的計算框架均在支援範圍內;同時PPML也支援機器學習、深度學習、聯邦學習功能,並配備加密儲存和同態加密的支持,確保端到端的全鏈路安全性。
03 #應用實作
下面是一些客戶的應用實作案例,其中比較有名的是去年的天池大賽。在去年的一個分賽中,參賽者希望訓練和模型推理過程能完全被SGX保護,透過PPML提供的Flink功能,結合螞蟻集團的LibOS項目Occlum,實現訓練和模型推理在應用層面無感。最後整個比賽有4000多支隊伍參加,應用了上百台伺服器,證明了PPML能夠支援大規模商用,並且整體而言,運營方並沒有感知到很大的變化。

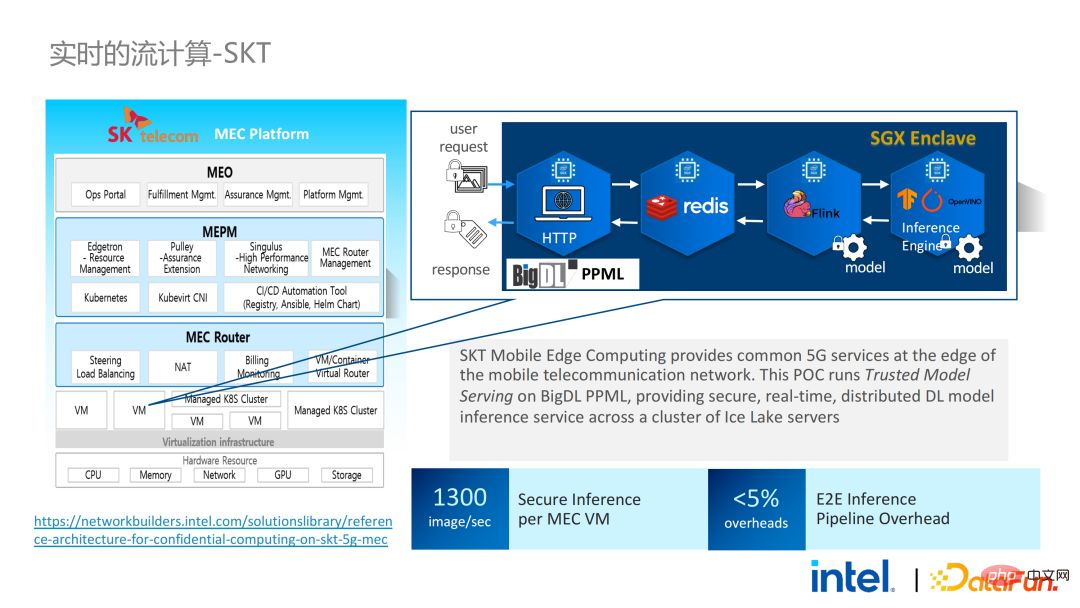
在同年9-10月份,韓國電信希望搭建端到端安全的、基於BigDL和Flink的即時模型推理環境,他們對性能的要求更加苛刻。經過天池的歷練,BigDL基於Flink和SGX的即時模型推理的方案更加成熟,端到端的效能損失小於5%,吞吐量也達到了韓國電信的基本需求。
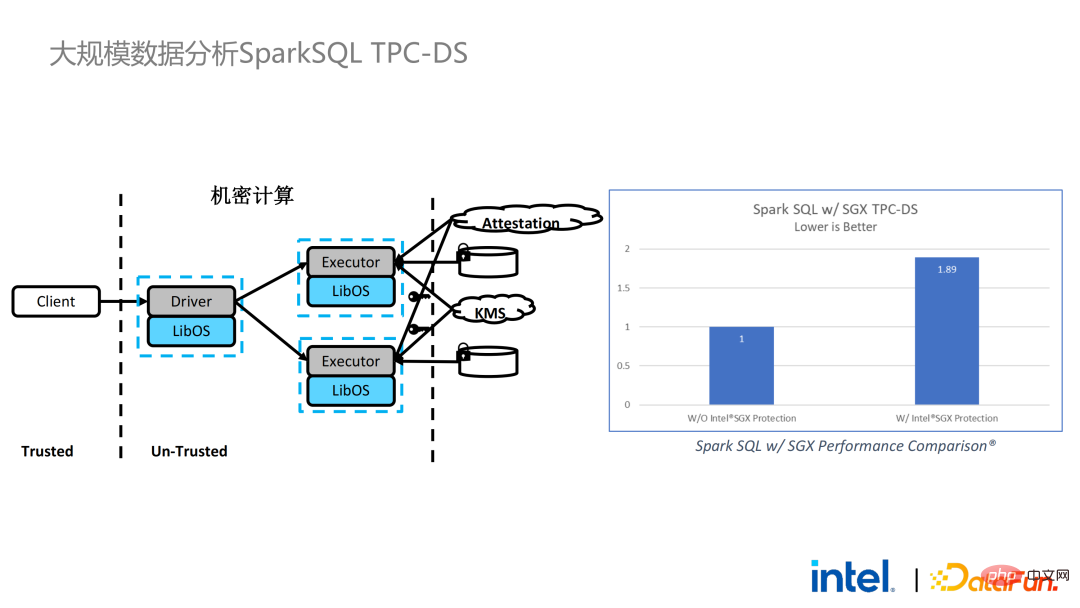
我們也進行了Spark的效能測試。結論而言,即使測試資料達到上百GB,PPML方案運行Spark也沒有出現拓展性和效能問題。根據客戶的需求,我們特別選了一個對SGX不友善的IO密集型應用TPC-DS。 TPC-DS是常用的SQL benchmark標準,它對IO和運算的要求比較高,在資料量較大時,會出現大規模的磁碟、記憶體和網路IO。而作為硬體級的TEE,資料進出SGX都需要經過解密和加密,因此讀取和寫出資料的開銷會比非SGX大。經過完整的TPC-DS測試,整個端到端的損失在2倍以內,達到了客戶的預期。透過TPC-DS的benchmark,我們證明了,即使是在這種最壞的情況下,我們都能確保端到端的損失降到可接受的範圍內(1.8)。
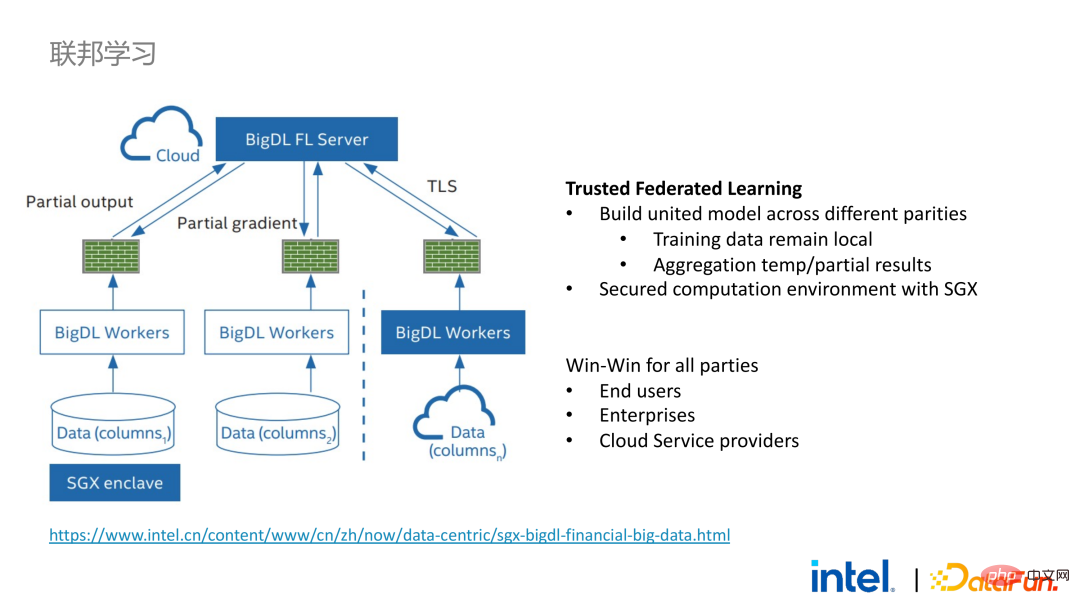
實現了大數據應用的無縫遷移之後,我們也和部分客戶進行了聯邦學習的嘗試。因為SGX提供了安全的環境,恰好可以解決聯邦學習過程中最關鍵的伺服器和本地資料的安全問題。 BigDL提供的聯邦學習方案和一般方案有一個很大的差異,即整個方案本質上是一個面向大規模資料的聯邦學習方案。其中,每個worker的工作負載和針對的資料規模較大,每一個worker相當於一個小叢集。我們和部分客戶驗證了方案的可行性和有效性。
04 總結和展望
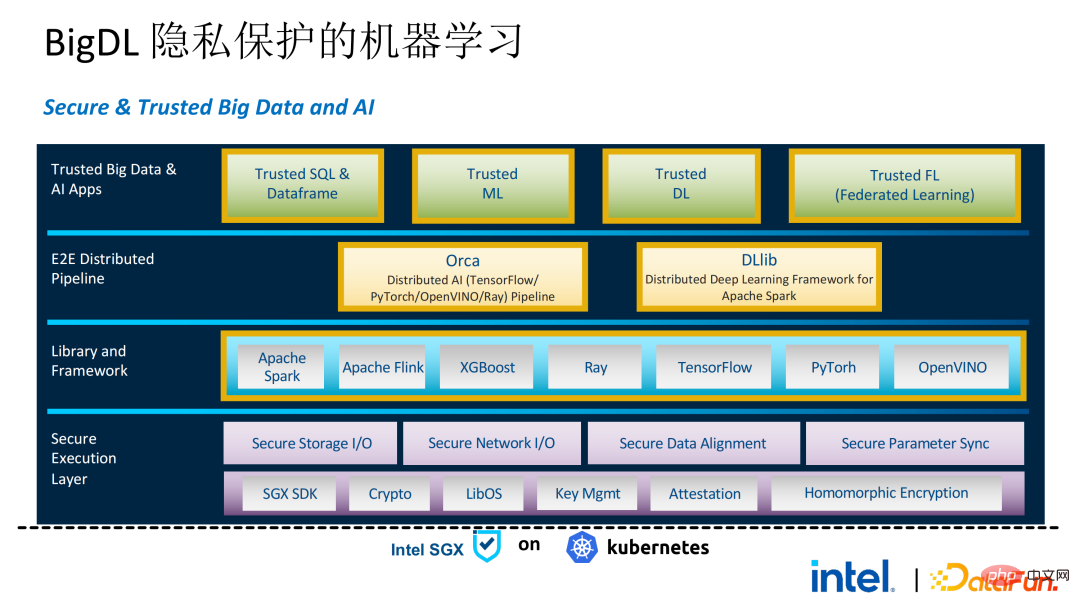
#如前文所說,在和客戶兩年多的溝通和合作中,我們挖掘到了隱私計算和大數據AI相關的若干痛點。這些痛點均可透過SGX等安全技術解決。其中,LibOS能夠解決相容性問題,SGX能夠解決安全環境和效能問題;Spark或Flink的支援能夠解決大數據及遷移的問題;聯邦學習能夠解決資料孤島問題。 BigDL PPML則是綜合了上述服務的一站式隱私計算方案。

SGX和TEE的生態目前正在快速發展。在可預見的未來,TEE在易用性、安全性和性能等方面會有很大的提高,例如英特爾下一代的TDX能直接提供OS的支持,可以從根本上解決應用的兼容性問題;開源社群也正在完善機密容器的支持,確保container的安全性,大大降低應用程式遷移的成本。從安全性角度來說,也會出現如微內核之類工作,進一步強化TEE生態的安全性。從拓展性的角度來看,英特爾和社群也在推動對加速器和IO設備的支持,將其納入可信任域內,降低資料流轉的效能開銷。

以上是隱私計算在大數據AI領域的應用實踐的詳細內容。更多資訊請關注PHP中文網其他相關文章!