



目錄
- #Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
- MiniGPT-4:Enhancing Vision-language Understanding with Advanced Large Language Models
- OpenAssistant Conversations - Democratizing Large Language Model Alignment
- Inpaint Anything: Segment Anything Meets Image Inpainting
- Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
- Plan4MC: Skill Reinforcement Learning and Planning for Open-World Minecraft Tasks T2Ranking: A large-scale Chinese Benchmark for Passage Ranking
ArXiv Weekly Radiostation:NLP、CV、ML 更多精選論文(附音訊)
論文1:Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models

範例展示:從草圖建立網站。

推薦:3 天近一萬Star,無差體驗GPT-4 識圖能力,MiniGPT-4 看圖聊天、還能草圖建網站。
論文3:OpenAssistant Conversations - Democratizing Large Language Model Alignment
- #作者:Andreas Köpf、Yannic Kilcher 等
- 論文地址:https://drive.google.com/file/d/10iR5hKwFqAKhL3umx8muOWSRm7hs5FqX/view
摘要:為了使大規模對齊研究民主化,來自LAION AI 等機構(Stable diffusion 使用的開源資料就是該機構提供的。)的研究者收集了大量基於文字的輸入和回饋,創建了一個專門訓練語言模型或其他AI 應用的多樣化和獨特資料集OpenAssistant Conversations。
該資料集是一個由人工生成、人工註釋的助理式對話語料庫,涵蓋了廣泛的主題和寫作風格,由161443 條訊息組成,分佈在66497 個會話樹中,使用35 種不同的語言。該語料庫是全球眾包工作的產物,涉及超過 13500 名志工。對於任何希望創建 SOTA 指令模型的開發者而言,它都是一個非常寶貴的工具。並且任何人都可以免費存取整個資料集。
此外,為了證明OpenAssistant Conversations 資料集的有效性,該研究還提出了一個基於聊天的助手OpenAssistant,其可以理解任務、與第三方系統交互、動態檢索信息。可以說這是第一個在人類資料上進行訓練的完全開源的大規模指令微調模型。
結果顯示,OpenAssistant 的回覆比 GPT-3.5-turbo (ChatGPT) 更受歡迎。
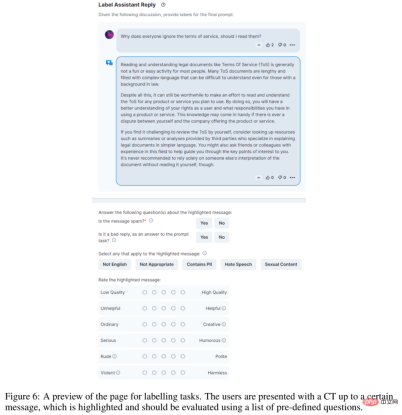
OpenAssistant Conversations 資料是使用web-app 介面收集的,包括5 個步驟:提示、標記提示、將回覆訊息新增為提示器或助理、標記回覆、對助理回覆進行排名。
推薦:ChatGPT 全球最大開源平替。
論文4:Inpaint Anything: Segment Anything Meets Image Inpainting
- 作者:Tao Yu、Runseng Feng 等
- 論文網址:http://arxiv.org/abs/2304.06790
摘要:來自中國科學技術大學和東方理工高等研究院的研究團隊,基於SAM(Segment Anything Model),提出「修補一切」(Inpaint Anything,簡稱IA)模型。有別於傳統圖像修補模型,IA 模型無需精細化操作生成掩碼,支援了一鍵點擊標記選定對象,IA 即可實現移除一切物體(Remove Anything)、填補一切內容(Fill Anything)、替換一切場景(Replace Anything),涵蓋了包括目標移除、目標填充、背景替換等在內的多種典型圖像修補應用場景。
IA 有三個主要功能:(i) 移除一切(Remove Anything):使用者只需點擊一下想要移除的物體,IA 將無痕地移除該物體,實現高效「魔法消除」;(ii) 填補一切(Fill Anything):同時,使用者還可以進一步透過文字提示(Text Prompt)告訴IA 想要在物體內填充什麼,IA 隨即透過驅動已嵌入的AIGC(AI-Generated Content)模型(如Stable Diffusion [2])產生對應的內容填充物體,實現隨心所欲「內容創作」;(iii) 替換一切(Replace Anything):使用者也可以透過點擊選擇需要保留的物體對象,並用文字提示告訴IA想要把物體的背景替換成什麼,即可將物件背景替換為指定內容,實現生動「環境轉換」。 IA 的整體框架如下圖所示:
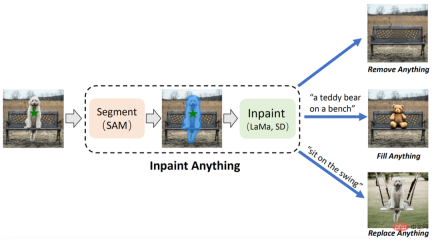
#建議:無需精細標記,按一下物件移除物件、內容填補、場景替換。
論文5:Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
- ##作者:Feng Liang 、 Bichen Wu 等
- 論文網址:https://arxiv.org/pdf/2210.04150.pdf
#摘要:Meta、UTAustin 聯合提出了新的開放語言風格模型(open-vocabulary segmentation, OVSeg),它能讓Segment Anything 模型知道所要分隔的類別。
從效果來看,OVSeg 可以與 Segment Anything 結合,完成細微的開放語言分割。例如下圖 1 中辨識花朵的種類:sunflowers (向日葵)、white roses (白玫瑰)、 chrysanthemums (菊花)、carnations (康乃馨)、green dianthus (綠石竹)。

#建議:Meta/UTAustin 提出全新開放類別分割模型。
論文6:Plan4MC: Skill Reinforcement Learning and Planning for Open-World Minecraft Tasks
- 作者:Haoqi Yuan、Chi Zhang 等
- #論文網址:https://arxiv.org/abs/2303.16563
#摘要:北京大學和北京智源人工智慧研究院的團隊提出了在無專家資料的情況下高效解決Minecraft 多任務的方法Plan4MC。作者結合強化學習和規劃的方法,將解決複雜任務分解為學習基本技能和技能規劃兩個部分。作者使用內在獎勵的強化學習方法訓練三類細粒度的基本技能。智能體使用大型語言模型建構技能關係圖,透過圖上的搜尋得到任務規劃。實驗部分,Plan4MC 目前可以完成 24 個複雜多樣任務,成功率相較於所有的基線方法都有巨大提升。

推薦:用 ChatGPT 和強化學習來玩《我的世界》,Plan4MC 攻克 24 個複雜任務。
論文 7:T2Ranking: A large-scale Chinese Benchmark for Passage Ranking
- 作者:Xiaohui Xie、Qian Dong 等
- #論文網址:https://arxiv.org/abs /2304.03679
摘要:段落排序是資訊檢索領域中十分重要且具有挑戰性的議題,受到了學術界和工業界的廣泛關注。段落排序模型的有效性能夠提高搜尋引擎使用者的滿意度並且對問答系統、閱讀理解等資訊檢索相關應用有所助益。在這一背景下,例如 MS-MARCO,DuReader_retrieval 等一些基準資料集被建構用於支援段落排序的相關研究工作。然而常用的資料集大部分都關注英文場景,對於中文場景,已有的資料集在資料規模、細粒度的使用者標註和假負例問題的解決上有其限制。在這一背景下,該研究基於真實搜尋日誌,建立了一個全新的中文段落排序基準資料集:T2Ranking。
T2Ranking 由超過 30 萬的真實查詢和 200 萬的網路段落構成,並且包含了由專業標註人員提供的 4 級細粒度相關性標註。目前數據和一些 baseline 模型已經公佈在 Github,相關研究工作已作為 Resource 論文被 SIGIR 2023 錄用。
推薦:30 萬真實查詢、200 萬網路段落,中文段落排序基準資料集發布。
ArXiv Weekly Radiostation
機器之心聯合由楚航、羅若天、梅洪源發起的ArXiv Weekly Radiostation,在7 Papers 的基礎上,精選本週更多重要論文,包括NLP、CV、ML領域各10篇精選,並提供音頻形式的論文摘要簡介,詳情如下:
本週10 篇NLP 精選論文是:
1. Task-oriented Document-Grounded Dialog Systems by HLTPR@RWTH for DSTC9 and DSTC10. (from Hermann Ney)
#2. Exploring the Trade-Offs: Unified Large Language Models vs Local Fine-Tuned Models for Highly-Specific Radiology NLI Task. (from Wei Liu, Dinggang Shen)
##3. On the Robustness of Aspect-based Sentiment Analysis: Rethinking Model, Data, and Training. (from Tat-Seng Chua)
#4. Stochastic Parrots Looking for Stochastic Parrots : LLMs are Easy to Fine-Tune and Hard to Detect with other LLMs. (from Rachid Guerraoui)
5. Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models. ( from Kai-Wei Chang, Song-Chun Zhu, Jianfeng Gao)
6. MER 2023: Multi-label Learning, Modality Robustness, and Semi-Supervised Learning. (from Meng Wang, Erik Cambria, Guoying Zhao)
7. GeneGPT: Teaching Large Language Models to Use NCBI Web APIs. (from Zhiyong Lu)
8 . A Survey on Biomedical Text Summarization with Pre-trained Language Model. (from Sophia Ananiadou)
9. Emotion fusion for mental illness detection from social media: A survey. (from Sophia Anani )
10. Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes. (from Christopher Ré)
本週10 篇CV 精選論文是:
1. NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models. (from Antonio Torralba)
########################################################################################################################################## #####2. Align-DETR: Improving DETR with Simple IoU-aware BCE loss. (from Xiangyu Zhang)############3. Exploring Incompatible Knowledge Transfer in Few-shot Image Generation##3. Exploring Incompatible Knowledge Transfer in Few-shot Image Generation##3. Exploring Incompatible Knowledge Transfer in Few-shot Image Generation##3. Exploring Incompatible Knowledge Transfer in Few-shot Image Generation##3. Exploring Incompatible Knowledge Transfer in Few-shot Image Generation . (from Shuicheng Yan)######4。用於視訊問答的學習情境超圖。 (來自穆巴拉克·沙阿)
5。超越單一剪輯的影片生成。 (出自楊明軒)
6.透過 Vision Transformer 實現非均勻去霧的以資料為中心的解決方案。 (來自劉歡)
7.神經形態光流和事件相機的即時實現。 (來自盧卡·貝尼尼、大衛·斯卡拉穆扎)
8。用於互動式影像檢索的語言引導局部滲透。 (來自張雷)
9. LipsFormer:將 Lipschitz Continuity 引入 Vision Transformer。 (來自張雷)
10. UVA:面向視圖合成、姿勢渲染、幾何和紋理編輯的統一體積頭像。 (摘自陶大成)
本週第10篇ML精選論文是:
1.將強化學習理論與實務與有效視野連結。 (來自斯圖爾特·拉塞爾)
2。建立透明且穩健的數據驅動風力渦輪機功率曲線模型。 (來自克勞斯-羅伯特·穆勒)
3。開放世界持續學習:統一新穎性檢測與持續學習。 (來自劉冰)
4。潛在空間的學習提高了深度神經算子的預測準確性。 (來自喬治·艾姆·卡尼亞達基斯)
5。解耦圖神經網路:同時訓練多個簡單 GNN,而不是一個。 (來自李雪龍)
6.基於模型的神經網路的泛化和估計誤差界。 (來自 Yonina C. Eldar)
7。 RAFT:產生基礎模型對齊的獎勵排名微調。 (來自張童)
8. GAN 的自適應共識最佳化方法。 (來自帕萬·庫馬爾)
9。基於角度的梯度下降動態學習率。 (來自帕萬·庫馬爾)
10。 AGNN:交替圖正則化神經網路以減輕過度平滑。 (出自郭文忠)
以上是MiniGPT-4看圖片聊天、還能草圖建網站;視訊版Stable Diffusion來了的詳細內容。更多資訊請關注PHP中文網其他相關文章!


 軟AI的興起及其對當今企業的意義Apr 15, 2025 am 11:36 AM
軟AI的興起及其對當今企業的意義Apr 15, 2025 am 11:36 AM軟AI(被定義為AI系統,旨在使用近似推理,模式識別和靈活的決策執行特定的狹窄任務 - 試圖通過擁抱歧義來模仿類似人類的思維。 但是這對業務意味著什麼
 為AI前沿的不斷發展的安全框架Apr 15, 2025 am 11:34 AM
為AI前沿的不斷發展的安全框架Apr 15, 2025 am 11:34 AM答案很明確 - 只是雲計算需要向雲本地安全工具轉變,AI需要專門為AI獨特需求而設計的新型安全解決方案。 雲計算和安全課程的興起 在
 生成AI的3種方法放大了企業家:當心平均值!Apr 15, 2025 am 11:33 AM
生成AI的3種方法放大了企業家:當心平均值!Apr 15, 2025 am 11:33 AM企業家,並使用AI和Generative AI來改善其業務。同時,重要的是要記住生成的AI,就像所有技術一樣,都是一個放大器 - 使得偉大和平庸,更糟。嚴格的2024研究O
 Andrew Ng的新簡短課程Apr 15, 2025 am 11:32 AM
Andrew Ng的新簡短課程Apr 15, 2025 am 11:32 AM解鎖嵌入模型的力量:深入研究安德魯·NG的新課程 想像一個未來,機器可以完全準確地理解和回答您的問題。 這不是科幻小說;多虧了AI的進步,它已成為R
 大語言模型(LLM)中的幻覺是不可避免的嗎?Apr 15, 2025 am 11:31 AM
大語言模型(LLM)中的幻覺是不可避免的嗎?Apr 15, 2025 am 11:31 AM大型語言模型(LLM)和不可避免的幻覺問題 您可能使用了諸如Chatgpt,Claude和Gemini之類的AI模型。 這些都是大型語言模型(LLM)的示例,在大規模文本數據集上訓練的功能強大的AI系統
 60%的問題 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM
60%的問題 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM最近的研究表明,根據行業和搜索類型,AI概述可能導致有機交通下降15-64%。這種根本性的變化導致營銷人員重新考慮其在數字可見性方面的整個策略。 新的
 麻省理工學院媒體實驗室將人類蓬勃發展成為AI R&D的核心Apr 15, 2025 am 11:26 AM
麻省理工學院媒體實驗室將人類蓬勃發展成為AI R&D的核心Apr 15, 2025 am 11:26 AM埃隆大學(Elon University)想像的數字未來中心的最新報告對近300名全球技術專家進行了調查。由此產生的報告“ 2035年成為人類”,得出的結論是,大多數人擔心AI系統加深的採用


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

禪工作室 13.0.1
強大的PHP整合開發環境

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

