
Google下場優化擴散模型,三星手機運行Stable Diffusion,12秒內出圖

- 王林轉載
- 2023-04-28 08:19:141122瀏覽
Stable Diffusion 在影像生成領域的知名度不亞於對話大模型中的 ChatGPT。其能夠在幾十秒內為任何給定的輸入文字創建逼真圖像。由於 Stable Diffusion 的參數量超過 10 億,並且由於裝置上的運算和記憶體資源有限,因此此模型主要運行在雲端。
在沒有精心設計和實施的情況下,在裝置上運行這些模型可能會導致延遲增加,這是由於迭代降噪過程和記憶體消耗過多造成的。
如何在設備端運行Stable Diffusion 引起了大家的研究興趣,此前,有研究者開發了一個應用程序,該應用在iPhone 14 Pro 上使用Stable Diffusion 生成圖片僅需一分鐘,使用大約2GiB 的應用程式記憶體。
先前蘋果也對此做了一些優化,他們在 iPhone、iPad、Mac 等裝置上,半分鐘就能產生一張解析度 512x512 的圖片。高通緊隨其後,在安卓手機端運行 Stable Diffusion v1.5 ,不到 15 秒生成分辨率 512x512 的圖像。
近日,Google發表的一篇論文中《 Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations 》,他們實現了在GPU 驅動的裝置上執行Stable Diffusion 1.4 ,達到SOTA 推理延遲效能(在三星S23 Ultra 上,透過20 次迭代產生512 × 512 的影像僅需11.5 秒)。此外,該研究不是只針對一種設備;相反,它是一種通用方法,適用於改進所有潛在擴散模型。
在沒有資料連線或雲端伺服器的情況下,這項研究為在手機上本地運行生成 AI 開闢了許多可能性。 Stable Diffusion 去年秋天才發布,今天已經可以塞進設備運行,可見這個領域發展速度有多快。

#論文網址:https://arxiv.org/pdf/2304.11267.pdf
#為了達到這個生成速度,Google提出了一些優化建議,下面我們來看看Google是如何優化的。
方法介紹
該研究旨在提出最佳化方法來提高大型擴散模型文生圖的速度,其中針對Stable Diffusion 提出一些最佳化建議,這些最佳化建議也適用於其他大型擴散模型。
首先來看Stable Diffusion 的主要組成部分,包括:文字嵌入器(text embedder)、雜訊產生(noise generation)、去噪神經網路(denoising neural network)和圖像解碼器(image decoder,如下圖1 所示。
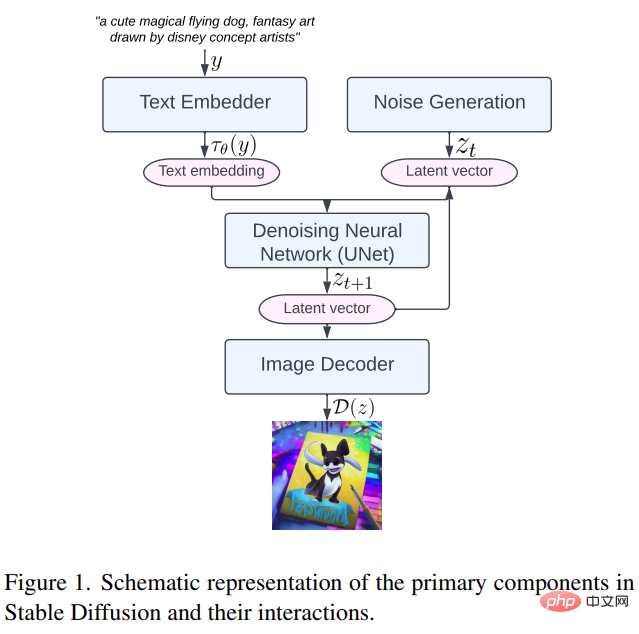
#然後我們具體看一下該研究提出的三種最佳化方法。
專用核心:Group Norm 和GELU
群組歸一化(GN)方法的工作原理是將特徵圖的通道(channel)分成更小的群組,並獨立地對每個群組進行歸一化,從而使GN 對批次大小的依賴性降低,更適合各種批次大小和網路架構。該研究沒有按順序執行reshape、取均值、求方差、歸一化這些操作,而是設計了一個獨特的GPU shader 形式的內核,它可以在一個GPU 命令中執行所有這些操作,而無需任何中間張量(tensor)。
高斯誤差線性單元(GELU)作為常用的模型激活函數,包含大量數值計算,例如乘法、加法和高斯誤差函數。該研究用一個專用的shader 來整合這些數值計算及其伴隨的split 和乘法操作,使它們能夠在單一AI 作畫呼叫中執行。
提高注意力模組的效率
Stable Diffusion 中的文字到圖像 transformer 有助於對條件分佈進行建模,這對於文字到圖像生成任務至關重要。然而,由於記憶體複雜性和時間複雜度,自 / 交叉注意力機制在處理長序列時遇到了困難。基於此,研究提出兩種最佳化方法,以緩解計算瓶頸。
一方面,為了避免在大矩陣上執行整個softmax 計算,該研究使用一個GPU shader 來減少運算操作,大大減少了中間張量的記憶體佔用和整體延遲,具體方法如下圖2 所示。

另一方面,研究採用FlashAttention [7] 這種IO 感知的精確注意力演算法,使得高頻寬記憶體(HBM)的存取次數少於標準注意力機制,提高了整體效率。
Winograd 卷積
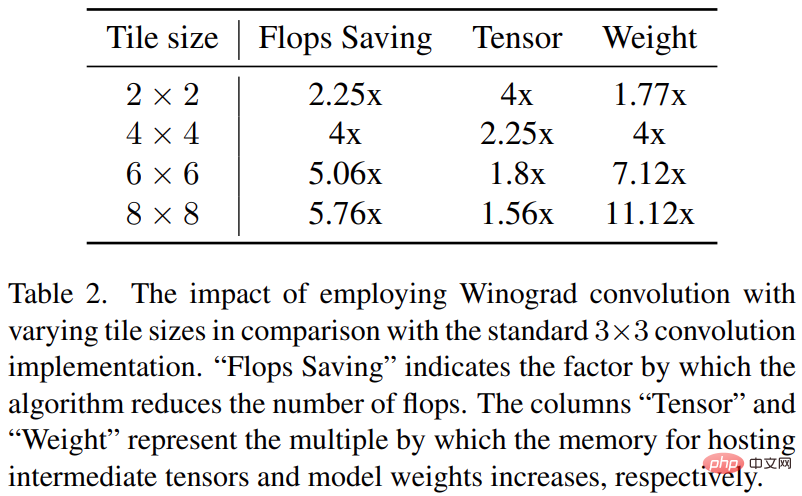
#Winograd 磁碟區將卷積運算轉換為一系列矩陣乘法。這種方法可以減少許多乘法運算,並提高計算效率。但是,這樣一來也會增加記憶體消耗和數字錯誤,特別是在使用較大的 tile 時。
Stable Diffusion 的主幹在很大程度上依賴 3×3 卷積層,尤其是在影像解碼器中,它們佔了 90% 。該研究對這一現象進行了深入分析,以探索在 3 × 3 內核卷積上使用不同 tile 大小的 Winograd 的潛在好處。研究發現 4 × 4 的 tile 大小最佳,因為它在計算效率和記憶體利用率之間提供了最佳平衡。
該研究在各種裝置上進行了基準測試:三星S23 Ultra(Adreno 740)和iPhone 14 Pro Max(A16)。基準測試結果如下表1 所示:
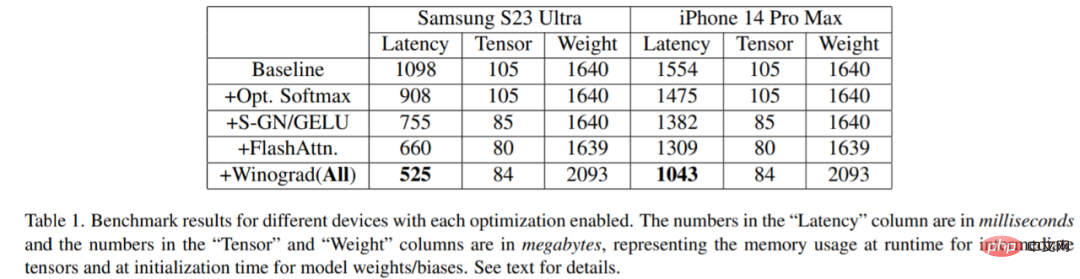
#很明顯,隨著每個最佳化被激活,延遲逐漸減少(可理解為生成影像時間減少)。具體而言,與基準相比:在三星 S23 Ultra 延遲減少 52.2%;iPhone 14 Pro Max 延遲減少 32.9%。此外,該研究也對三星 S23 Ultra 端對端延遲進行評估,在 20 個去噪迭代 step 內,產生 512 × 512 像素影像,不到 12 秒就達到 SOTA 結果。
小型裝置可以運行自己的生成式人工智慧模型,這對未來意味著什麼?我們可以期待一波。
以上是Google下場優化擴散模型,三星手機運行Stable Diffusion,12秒內出圖的詳細內容。更多資訊請關注PHP中文網其他相關文章!