
微軟開源微調指令集,協助開發家用版GPT-4,支援中英雙語生成。

- 王林轉載
- 2023-04-26 14:58:091276瀏覽
「指令」(Instruction)是ChatGPT模型取得突破性進展的關鍵因素,可以讓語言模型的輸出更符合「人類的偏好」。
但指令的標註工作需要耗費大量的人力,即便有了開源的語言模型,資金不足的學術機構、小公司也很難訓練出自己ChatGPT.
最近微軟的研究人員利用先前提出的Self-Instruct技術,首次嘗試使用GPT-4模型來自動產生語言模型所需的微調指令資料。

論文連結:https://arxiv.org/pdf/2304.03277.pdf
#程式碼連結:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
在基於Meta開源的LLaMA模型上的實驗結果表明,由GPT-4生成的5.2萬條英語和漢語instruction-following數據在新任務中的表現優於以前最先進的模型生成的指令數據,研究人員還從GPT-4收集回饋和比較數據,以便進行全面的評估和獎勵模式訓練。
訓練資料
資料收集
#研究人員重用了史丹佛大學發布的Alpaca模型用到的5.2萬條指令,其中每條指令都描述了模型應該執行的任務,並遵循與Alpaca相同的prompting策略,同時考慮有輸入和無輸入的情況,作為任務的可選上下文或輸入;使用大型語言模型對指令輸出答案。

在Alpaca 資料集中,輸出是使用GPT-3.5(text-davinci-003)產生的,但在在這篇論文中,研究者選擇使用GPT-4來產生數據,具體包括以下四個數據集:
#1. 英文Instruction-Following Data:對於在Alpaca中收集的5.2萬條指令,為每個指令都提供一個英文GPT-4答案。

未來的工作為遵循迭代的過程,使用GPT-4和self-instruct建立一個全新的資料集。
2. 中文Instruction-Following Data:使用ChatGPT將5.2萬條指令翻譯成中文,並要求GPT-4用中文回答這些指令,並以此建立一個基於LLaMA的中文instruction-following模型,並研究指令調優的跨語言泛化能力。
3. 比較數據(Comparison Data):要求GPT-4對自己的回覆提供從1到10的評分,並對GPT-4, GPT -3.5和OPT-IML這三個模型的回覆進行評分,以訓練獎勵模型。
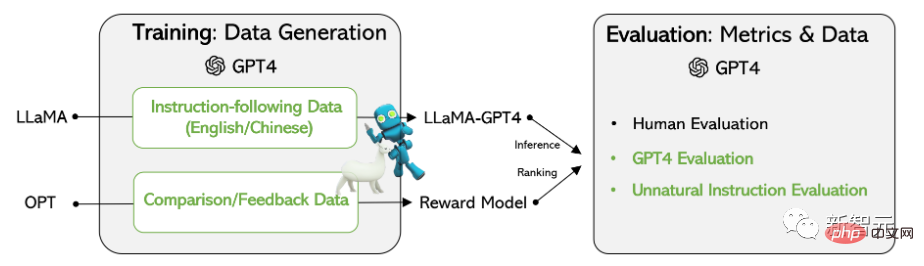
4. 非自然指令的答案:GPT-4的答案在6.8萬條(指令,輸入,輸出)三元組的資料集上解碼的,使用該子集來量化GPT-4和指令調優後的模型在規模上的差距。
資料統計
#研究人員比較了GPT-4和GPT-3.5的英語輸出回應集合:對於每個輸出,都提取了根動詞(root verb)和直接賓語名詞(direct-object noun),在每個輸出集上計算了獨特的動詞-名詞對的頻率。
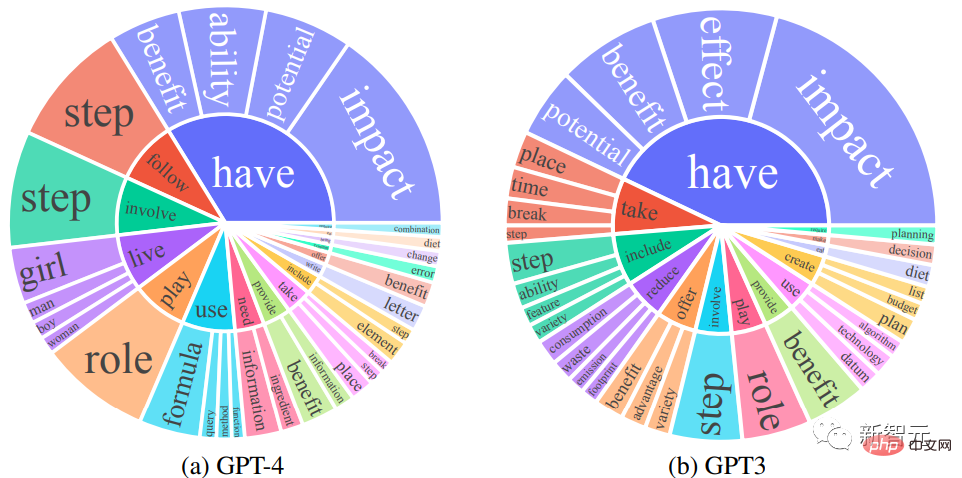
頻率高於10的動詞-名詞對
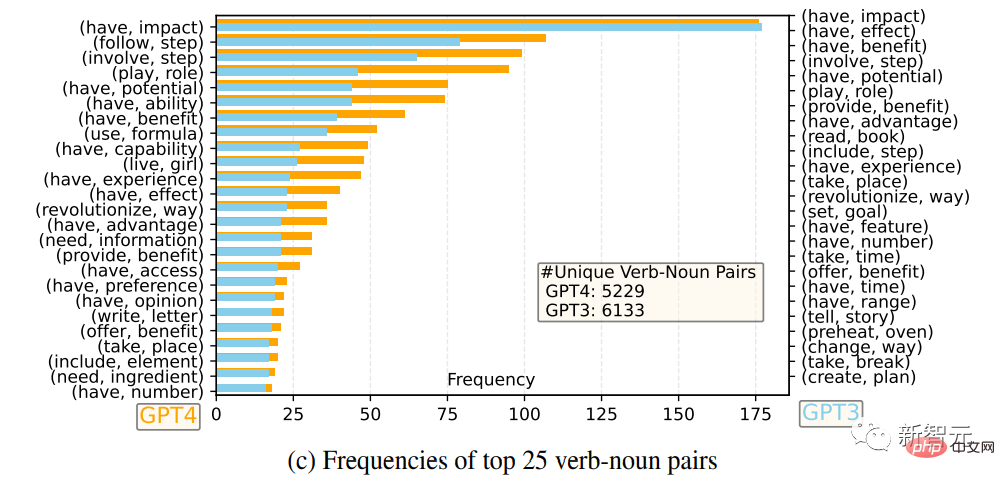
頻率最高的25對動詞-名詞
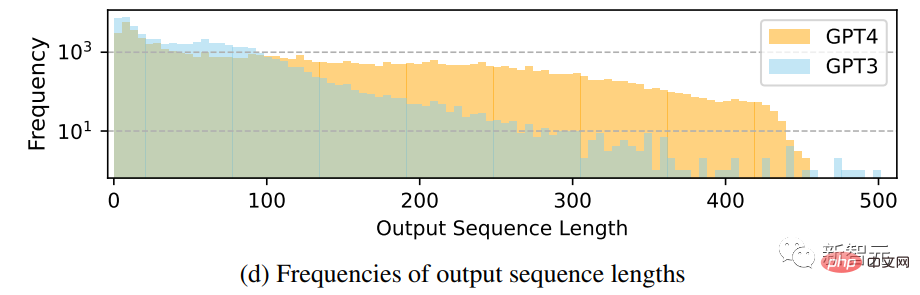
輸出序列長度的頻率分佈對比
#可以看到,GPT-4傾向於產生比GPT-3.5更長的序列,Alpaca中GPT-3.5資料的長尾現像比GPT-4的輸出分佈更明顯,可能是因為Alpaca資料集涉及到一個迭代的資料收集過程,在每次迭代中去除相似的指令實例,在目前的一次性數據生成中是沒有的。
儘管這個過程很簡單,但GPT-4產生的instruction-following資料表現出更強大的對齊效能。
指令調優語言模型
Self-Instruct 調優
研究人員基於LLaMA 7B checkpoint有監督微調後訓練得到了兩個模型:LLaMA-GPT4是在GPT-4產生的5.2萬條英文instruction-following資料上訓練的;LLaMA-GPT4-CN是在GPT-4的5.2萬條中文instruction-following資料上訓練的。
兩個模型被用來研究GPT-4的資料品質以及在一種語言中進行指令調優的LLMs時的跨語言泛化特性。
獎勵模型
#從人類回饋中進行強化學習(Reinforcement Learning from Human Feedback,RLHF)旨在使LLM行為與人類的偏好相一致,以使語言模型的輸出對人類更有用。
RLHF的關鍵組成部分是獎勵建模,其問題可以被表述為一個回歸任務,以預測給定提示和回應的獎勵評分,該方法通常需要大規模的比較數據,即對同一提示的兩個模型反應進行比較。
現有的開源模型,如Alpaca、Vicuna和Dolly,由於標註對比數據的成本很高,所以沒有用到RLHF,並且最近的研究表明,GPT-4能夠辨識並修復自己的錯誤,並準確判斷回覆的品質。
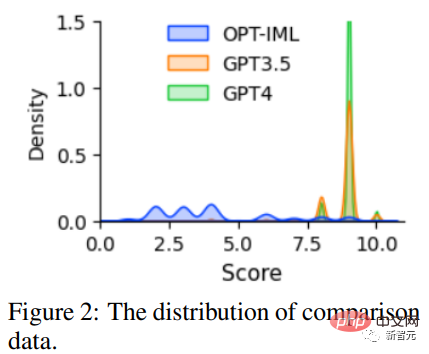
為了促進對RLHF的研究,研究人員使用GPT-4創建了對比數據;為了評估數據質量,研究人員訓練一個基於OPT 1.3B的獎勵模型,以對不同的回復進行評分:對一個提示和K個回复,GPT-4為每個回复提供一個1到10之間的評分。
實驗結果
在GPT-4數據上評估以前從未見過的任務的self-instruct調優模型的性能仍然是一項困難的任務。
由於主要目標是評估模型理解和遵守各種任務指示的能力,為了實現這一點,研究人員利用三種類型的評估,並透過研究結果證實,「利用GPT-4產生資料」相比其他機器自動產生的資料來說是一種有效的大型語言模型指令調優方法。
人類評估
為了評估該指令調優後的大型語言模型對齊質量,研究人員遵循先前提出的對齊標準:如果一個助手是有幫助的、誠實的和無害的(HHH),那它就是與人類評估標準對齊的,這些標準也被廣泛用於評估人工智慧系統與人類價值觀的一致性程度。
幫助性(helpfulness):是否能幫助人類實現他們的目標,一個能夠準確回答問題的模型是有幫助的。
誠實(honesty):是否提供真實訊息,並在必要時表達其不確定性以避免誤導人類用戶,一個提供虛假資訊的模型是不誠實的。
無害性(harmlessness):是否不會對人類造成傷害,一個產生仇恨言論或提倡暴力的模型不是無害的。
基於HHH對齊標準,研究人員使用眾包平台Amazon Mechanical Turk對模型生成結果進行手動評估。
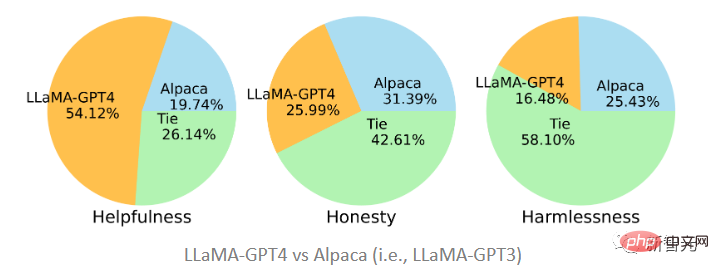
文中提出的兩個模型分別在GPT-4和GPT-3產生的資料上進行了微調,可以看到LLaMA-GPT4以51.2%的佔比在幫助性上要大大優於在GPT-3上微調的Alpaca(19.74%),而在誠實性和無害性標準下,則基本上處於平局狀態, GPT-3要略勝一籌。
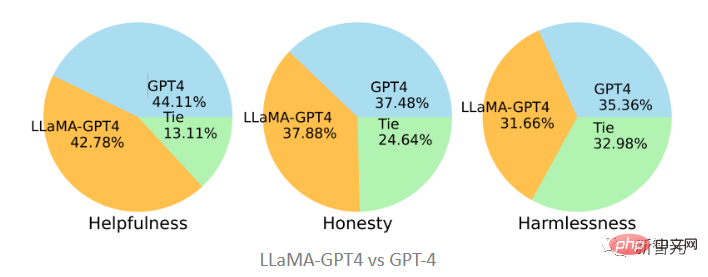
在和原版GPT-4比較時,可以發現二者在三個標準上也是相當一致的,即GPT-4指令調優後的LLaMA表現與原始的GPT-4類似。
GPT-4自動評估
#受Vicuna 的啟發,研究者也選擇用GPT-4來評估不同聊天機器人模型對80個未見過的問題所產生回答的質量,從LLaMA-GPT-4(7B)和GPT-4模型中收集回复,並從先前的研究中獲得其他模型的答案,然後要求GPT-4對兩個模型之間的回應品質進行評分,評分範圍從1到10,並將結果與其他強競爭模型(ChatGPT 和GPT-4)進行比較。
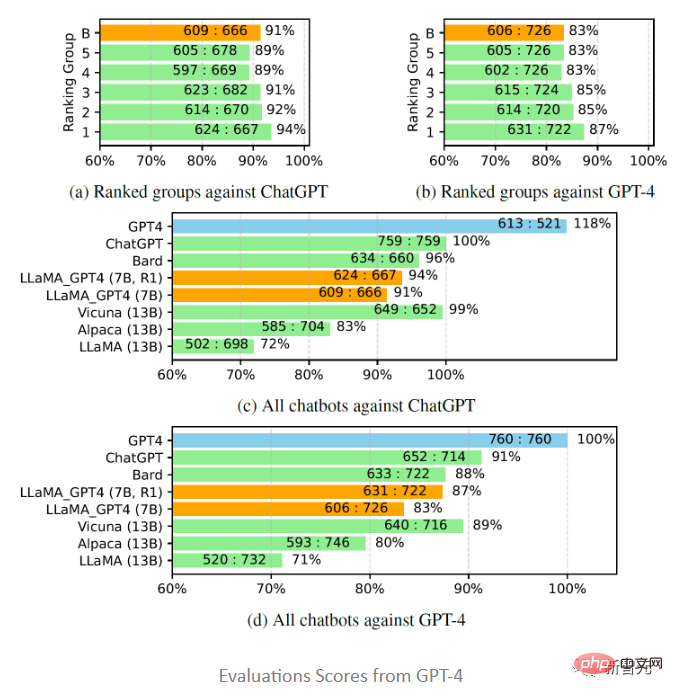
評估結果顯示,回饋資料和獎勵模型對提高LLaMA 的表現是有效的;用GPT-4對LLaMA進行指令調優,往往比用text-davinci-003調優(即Alpaca)和不調優(即LLaMA)的性能更高;7B LLaMA GPT4的性能超過了13B Alpaca和LLaMA,但和GPT-4等大型商業聊天機器人相比,仍有差距。
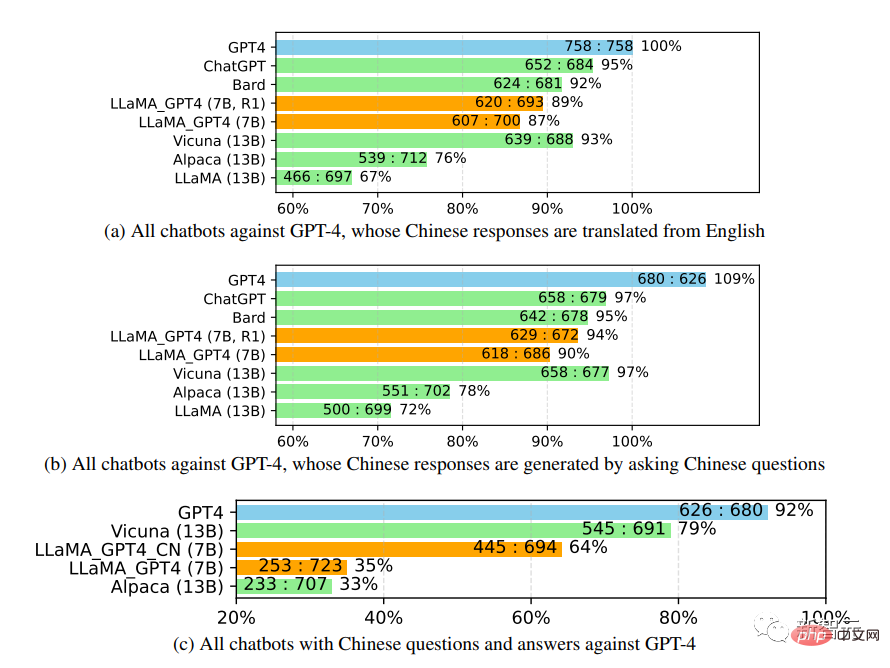
進一步研究中文聊天機器人的效能時,首先使用GPT-4將聊天機器人的問題也從英文翻譯成中文,用GPT-4得到答案,可以得到兩個有趣的觀察結果:
#1. 可以發現GPT-4評價的相對分數指標是相當一致的,無論是在不同的對手模型(即ChatGPT或GPT-4)和語言(即英文或中文)方面。
2. 僅就GPT-4的結果而言,翻譯後的回覆比中文產生的回覆表現得更好,可能是因為GPT-4是在比中文更豐富的英文語料庫中訓練的,所以具有更強的英文instruction-following能力。
非自然指令評估(Unnatural Instruction Evaluation)
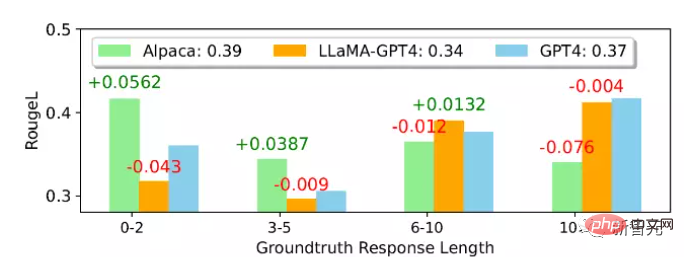
從平均ROUGE-L得分來看,Alpaca優於LLaMA-GPT 4和GPT-4,可以注意到,LLaMA-GPT4和GPT4在ground truth回復長度增加時逐漸表現得更好,最終在長度超過4時表現出更高的效能,意味著當場景更具創造性時,可以更好地遵循指令。
在不同的子集中,LLaMA-GPT4跟GPT-4的行為相差無幾;當序列長度較短時,LLaMA-GPT4和GPT-4都能產生包含簡單的基本事實答案的回复,但會增加額外的詞語,使回復更像聊天,可能會導致ROUGE-L得分降低。
以上是微軟開源微調指令集,協助開發家用版GPT-4,支援中英雙語生成。的詳細內容。更多資訊請關注PHP中文網其他相關文章!