
用ChatGPT和強化學習玩《我的世界》,Plan4MC攻克24個複雜任務

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-04-25 08:37:061250瀏覽
在開放式的環境中學習多種任務是通用智能體的重要能力。 《我的世界》(Minecraft)作為一款受歡迎的開放世界遊戲,具有無限生成的複雜世界和大量開放的任務,成為近幾年開放式學習研究的重要測試環境。
學習 Minecraft 中的複雜任務對目前的強化學習演算法是巨大的挑戰。一方面,智能體在無限的世界中透過局部的觀測尋找資源,面臨探索的困難。另一方面,複雜的任務通常需要很長的執行時間,要求完成許多隱含的子任務。例如,製作一把石鎬涉及砍樹、製作木鎬、挖原石等十餘個子任務,需要智能體執行數千步驟才能完成。智能體只有在任務完成時能夠獲得獎勵,難以透過稀疏獎勵學會任務。

#圖:Minecraft 中製作石鎬的過程。
目前圍繞 MineRL 挖鑽石競賽的研究普遍使用專家演示的資料集,而 VPT 等研究則使用大量標籤的資料學習策略。在缺少額外資料集的情況下,用強化學習訓練 Minecraft 的任務是非常低效的。 MineAgent 使用 PPO 演算法僅能完成若干個簡單任務;基於模型的 SOTA 方法 Dreamer-v3 在簡化環境模擬器的情況下,也需要採樣 1000 萬步學會獲得原石。
北京大學和北京智源人工智慧研究院的團隊提出了在無專家資料的情況下高效解決Minecraft 多任務的方法Plan4MC 。作者結合強化學習和規劃的方法,將解決複雜任務分解為學習基本技能和技能規劃兩個部分。作者使用內在獎勵的強化學習方法訓練三類細粒度的基本技能。智能體使用大型語言模型建構技能關係圖,透過圖上的搜尋得到任務規劃。實驗部分,Plan4MC 目前可以完成 24 個複雜多樣任務,成功率相較於所有的基線方法都有巨大提升。

- 論文連結:https://arxiv.org/abs/2303.16563
- #程式碼連結:https://github.com/PKU-RL/Plan4MC
- #專案首頁:https://sites.google.com/view/plan4mc
1、Minecraft 多任務
Minecraft 中玩家透過探索能夠獲得數百種物品。任務定義為初始條件和目標物品的組合,例如,「初始化
工作台,獲得熟牛肉」。解決這個任務包含 「獲得牛肉」、「用工作台和原石製作熔爐」 等步驟,這些細分的步驟稱為技能。人類在世界中掌握和組合此類技能來完成各種任務,而不是獨立地學習每個任務。 Plan4MC 的目標是學習策略掌握大量的技能,然後透過規劃將技能組合成任務。
作者在MineDojo 模擬器上建立了24 個測試任務,它們涵蓋了多種行為(砍樹、挖原石、與動物互動)、多種地形,涉及37 個基本技能。需要數十步的技能組合和數千步的環境互動來完成各個任務。
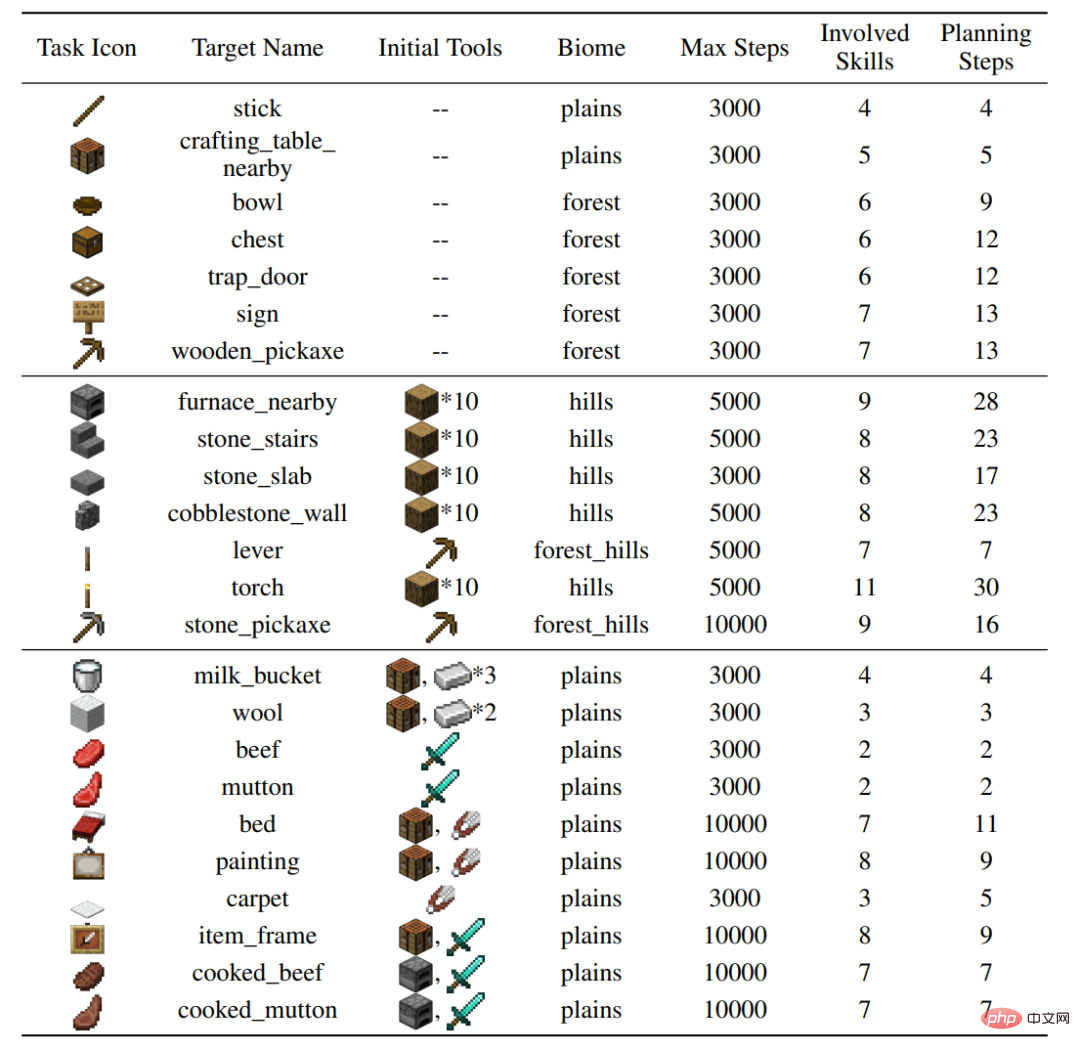
#圖:24 個任務的設定
2 、Plan4MC 方法
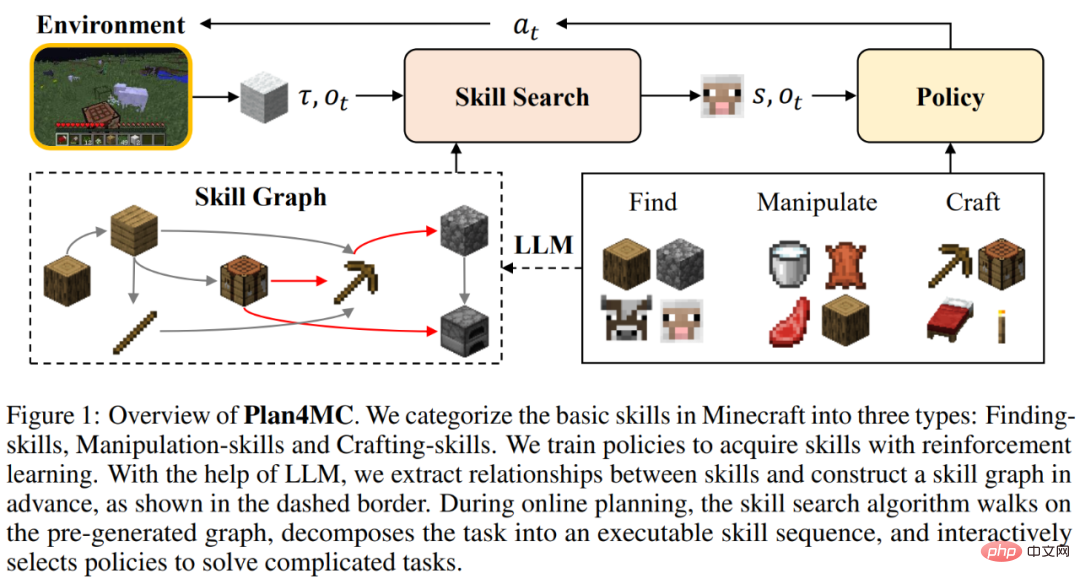
#學習技能
######################################################################################由於強化學習在訓練中難以讓玩家大規模跑動探索世界,許多技能仍無法被掌握。作者提出將探索和尋找的步驟分離出來,將 “砍樹” 技能進一步細化為 “找樹” 和 “獲得木頭”。 Minecraft 中的所有技能被分為三類細粒度的基本技能:
- #尋找:給定目標物品,玩家要在世界中探索,找到並接近該物品。
- 操作:利用現有的工具在附近完成一些任務,如放置工作台、與動物互動、挖方塊。
- 合成:用低階物品合成高階物品。
針對每一類技能,作者設計了強化學習模型和內在獎勵進行高效率的學習。尋找類技能使用分層的策略,其中上層策略負責給出目標位置、增加探索範圍,下層策略負責到達目標位置。操作類技能使用 PPO 演算法結合 MineCLIP 模型的內在獎勵訓練。合成類技能只使用一個動作完成。在未修改難度的 MineDojo 模擬器上,學習全部技能僅需與環境互動 6.5M 步驟。
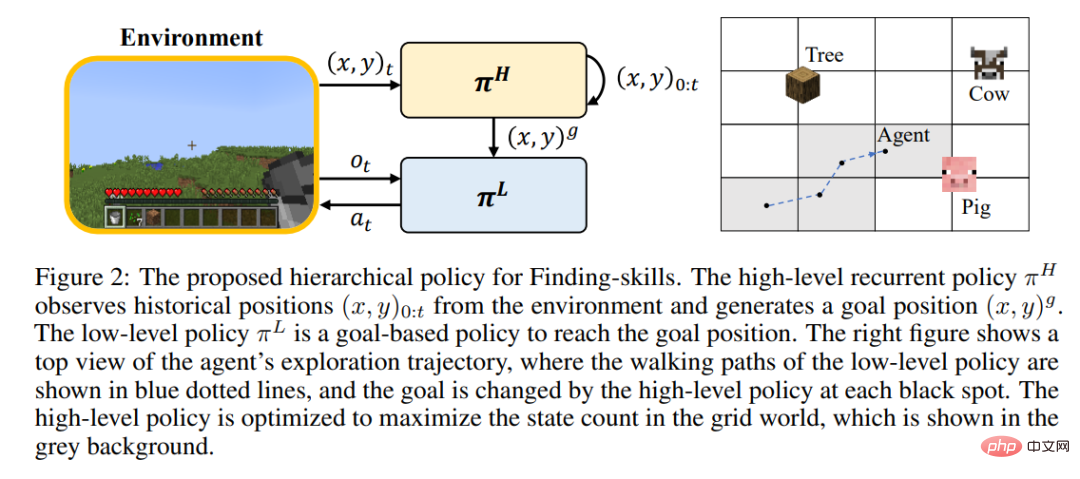
#Plan4MC 利用技能之間的依賴關係進行規劃,例如獲得石鎬與獲得原石、木棍、放置的工作台等技能間存在如下關係。

作者透過與大語言模型ChatGPT 互動的方式產生所有技能之間的關係,建構了技能的有向無環圖。規劃演算法是技能圖上的深度優先搜索,如下圖所示。

比起Inner Monologue、DEPS 等與大語言模型互動式規劃的方法,Plan4MC 能夠有效避免大語言模型規劃過程中的錯誤。
3、實驗結果
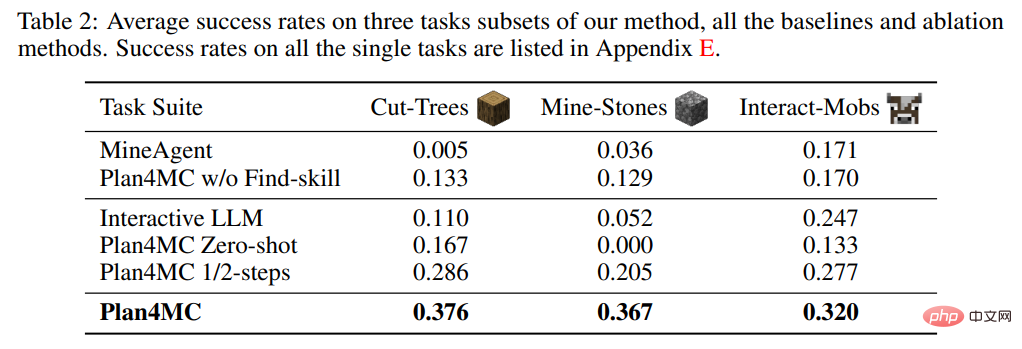
#在關於學習技能的研究中,作者引進了不做任務分解的MineAgent,以及不細分出尋找類技能的消融實驗Plan4MC w/o Find-skill。表 2 表明,Plan4MC 在三組任務上均顯著超過基線方法。 MineAgent 在擠牛奶、剪羊毛等簡單任務上表現接近 Plan4MC,但無法完成探索困難的砍樹、挖原石等任務。不做技能細分的方法在所有任務上成功率都低於 Plan4MC。
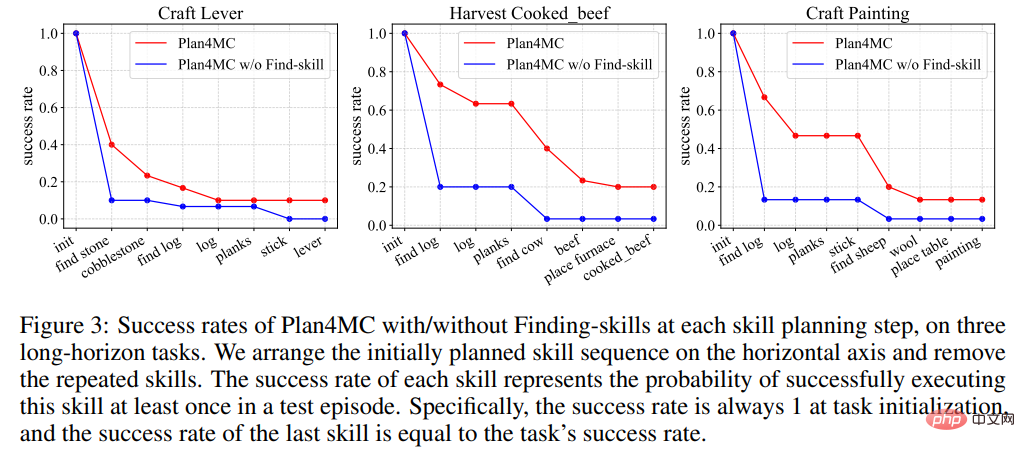
圖3 顯示了在完成任務的過程中,各方法在尋找目標的階段都有較大的失敗機率、導致成功率曲線下降。而不做技能細分的方法在這些階段的失敗機率明顯高於 Plan4MC 的機率。
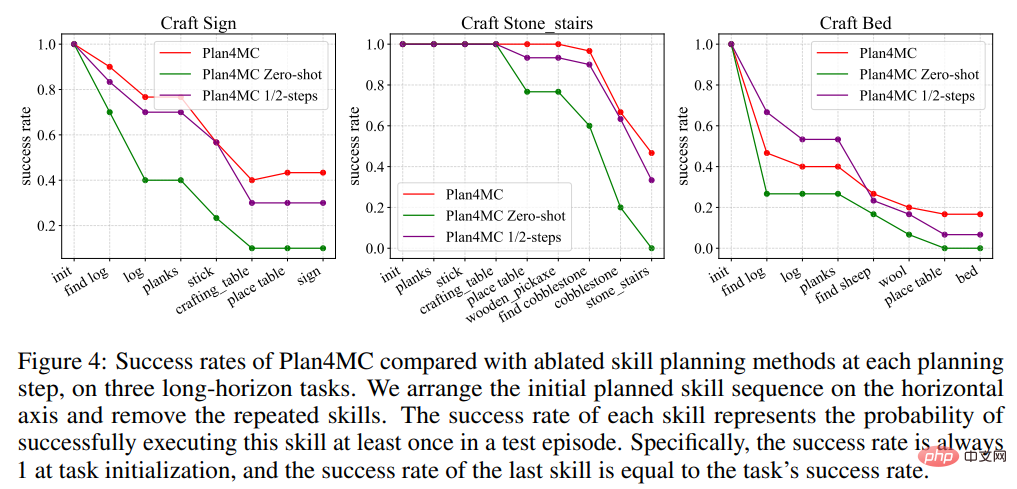
在關於規劃的研究中,作者引入了利用ChatGPT做互動規劃的基準方法Interactive LLM,以及兩個消融實驗:技能執行失敗時不再重新規劃的Zero-shot方法和使用一半最大交互步數的1/2-steps方法。表2顯示Interactive LLM在與動物互動的任務集上表現接近Plan4MC,而在另兩個需要更多規劃步驟的任務集上表現不佳。 Zero-shot的方法在所有任務上都表現較差。使用一半步數的方法相比Plan4MC成功率下降不多,表面Plan4MC能用較少的步數高效完成任務。
4、總結
作者提出了 Plan4MC,使用強化學習和規劃解決 Minecraft 中的多任務。為解決探索困難和樣本效率的問題,作者使用內在獎勵的強化學習訓練基本技能,利用大語言模型建立技能圖進行任務規劃。作者在大量困難 Minecraft 任務上驗證了 Plan4MC 相較包括 ChatGPT 等的各種基線方法的優勢。
結束語:強化學習技能 大語言模型 任務規劃有可能實現 Daniel Kahneman 所描述的 System1/2 人類決策模型。
以上是用ChatGPT和強化學習玩《我的世界》,Plan4MC攻克24個複雜任務的詳細內容。更多資訊請關注PHP中文網其他相關文章!