
Meta公司創新SOTA模型,能夠根據一句話生成驚人視頻,引爆網絡熱潮!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-04-23 09:22:071690瀏覽
給你一段話,讓你做個視頻,你能做到嗎?
Meta表示,我可以啊。
你沒聽錯:使用AI,你也可以變成電影人了!
近日,Meta推出了新的AI模型,名字起得也是非常直接:做個影片(Make-A-Video)。
這個模型強大到什麼程度?
一句話,就能實現「三馬奔騰」的場景。

就連LeCun都說,該來的總是會來的。

視覺效果超炫
話不多說,咱們直接看效果。
兩個袋鼠在廚房忙著做菜(做出來能不能吃另說)



近景:畫家在畫布上作畫

#大雨中漫步的二人世界(步伐整齊劃一)

馬在喝水

#芭蕾舞女孩在摩天大樓跳舞

#美麗的夏日熱帶海灘上,一隻金毛在吃冰淇淋(爪子已進化)

貓主子拿著遙控器在看電視(爪子已進化)
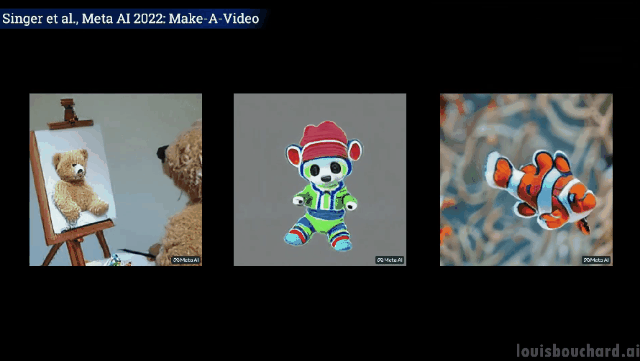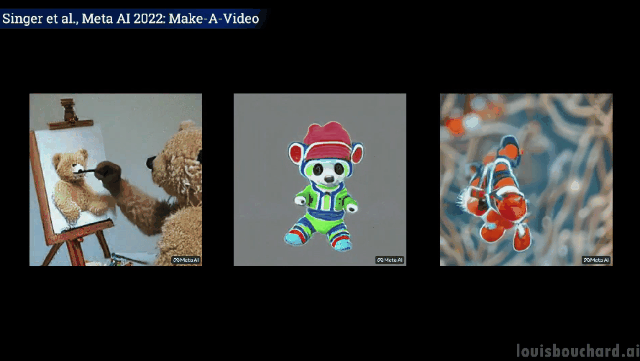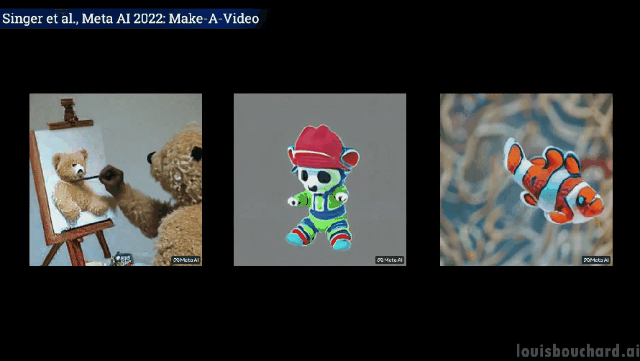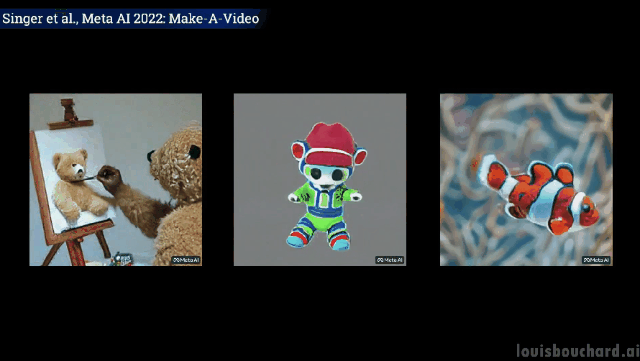
#一隻泰迪熊給自己畫自畫像

意料之外但情理之中的是,狗拿冰淇淋、貓拿遙控器以及泰迪熊畫畫的“手」,果然都「進化」得和人一樣啊! (戰術後仰)

輸入:

輸出:(亮的似乎有點不是地方)

2張靜圖變成GIF,輸入隕石圖

輸出:



##以及,把視頻,變成視頻?
 輸入:
輸入:
 # 輸出:
# 輸出:

#輸入:
## 輸出:

#技術原理
今天,Meta放出了自己的最新研究MAKE-A-VIDEO: TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA。
論文網址:https://makeavideo.studio/Make-A-Video.pdf
 在這個模型出現之前,我們已經有了Stable Diffusion。
在這個模型出現之前,我們已經有了Stable Diffusion。
按照先前的思路,研究人員會用大量的文字-影片對來訓練模型,但在現在的這種情況下,這種處理方法並不現實。因為這些數據很難取得,而且訓練成本非常昂貴。
因此,研究人員開了腦洞,採用了一種全新的方式。
他們選擇開發一個文字到圖像的模型,然後把它應用於影片。
巧了,前段時間,Meta就曾開發過這麼一個從文字到圖像的模型Make-A-Scene。
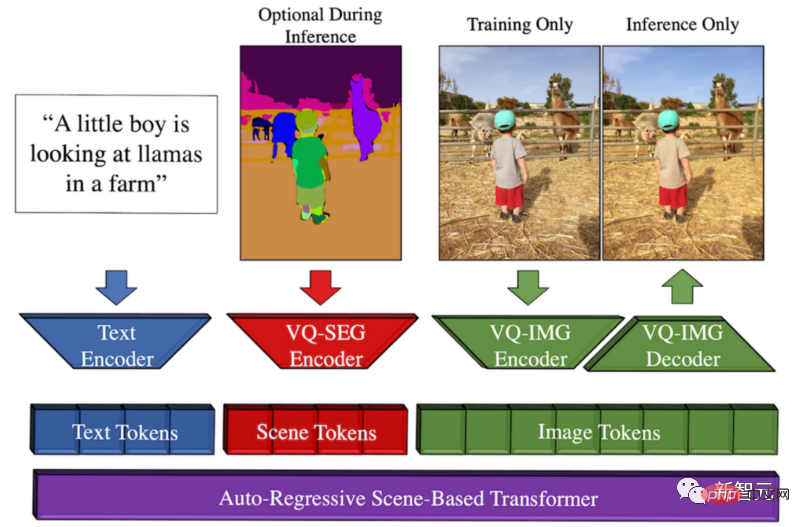
Make-A-Scene的方法概述
這個模型產生的契機是,Meta希望推動創意表達,將這種文字到圖像的趨勢與先前的草圖到圖像模型相結合,從而產生文字和以草圖為條件的圖像生成之間的奇妙融合。
這意味著我們可以快速勾勒出一隻貓,寫出自己想要什麼樣的圖像。遵循草圖和文字的指導,這個模型會在幾秒鐘內,產生我們想要的完美插圖。

你可以把這種多模態產生AI方法看成是一個對產生有更多控制的Dall-E模型,因為它也可以將快速草圖作為輸入。
之所以稱它為多模態,是因為它可以將多種模態作為輸入,例如文字和圖像。相較之下,Dall-E只能從文字生成圖像。
為了產生視頻,就需要加入時間的維度,因此研究人員在Make-A-Scene模型中添加了時空管道。
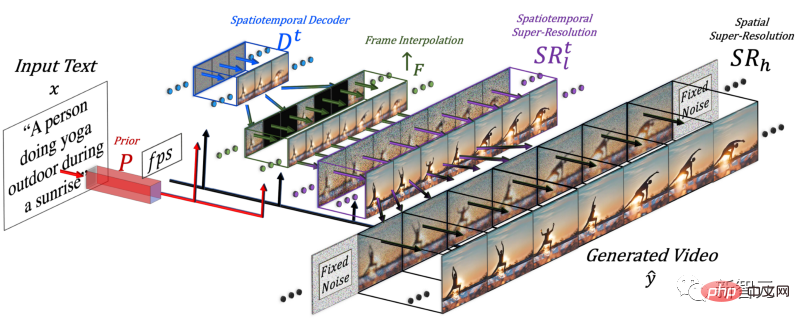
加入時間維度後,這個模型就不是只產生一張圖片,而是產生16張低解析度的圖片,以創建一個連貫的短視頻。
這個方法其實與文字到圖像模型類似,但不同之處在於:在常規的二維卷積的基礎上,它增加一維卷積。
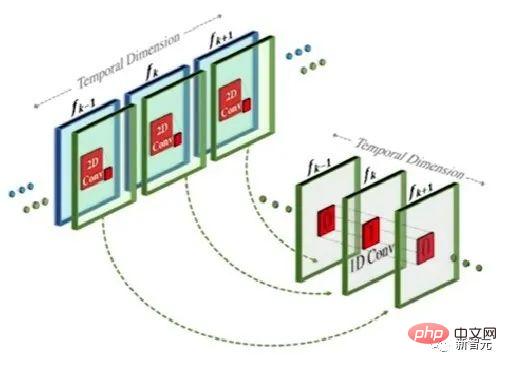
只是簡單地增加了一維卷積,研究人員就能保持預先訓練的二維卷積不變的同時,增加一個時間維度。然後,研究人員可以從頭開始訓練,重新使用Make-A-Scene影像模型的大部分程式碼和參數。
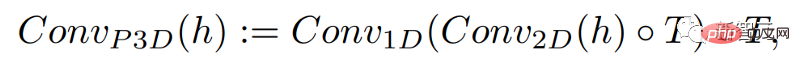
同時,研究人員也想用文字輸入來指導這個模型,這將與使用CLIP嵌入的圖像模型非常相似。
在這種情況下,研究人員是在將文字特徵與圖像特徵混合時,增加空間維度,方法同上:保留Make-A-Scene模型中的注意力模組,並為時間增加一個一維注意力模組-複製貼上影像產生器模型,為多一個維度重複產生模組,來獲得16個初始影格。
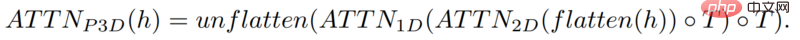
但只靠這16個初始幀,還不能產生影片。
研究人員需要從這16個主幀中,製作一個高清晰度的影片。他們採用的方法是:訪問之前和未來的幀,並同時在時間和空間維度上對它們進行迭代插值。
就這樣,他們在這16個初始幀之間,根據前後的幀生成了新的、更大的幀,這樣就使運動變得連貫,整體視頻變得流暢了。
這是透過一個幀插值網路完成的,它可以採取現有的圖像來填補空白,產生中間的資訊。在空間維度上,它會做同樣的事情:放大影像,填補像素的空白,使影像更加高清。

總而言之,為了生成視頻,研究人員微調了一個文本到圖像的模型。他們採用了一個已經訓練好的強大模型,對它進行調整和訓練,讓它適應影片。
因為增加了空間和時間模組,只要簡單地讓模型適應這些新資料就可以了,而不必重新訓練它,這就節省了大量的成本。
這種重新訓練使用的是未標記的視頻,只需要教模型理解視頻和視頻幀的一致性就可以了,這就可以更簡單地建立資料集。
最後,研究人員再次使用了圖像優化模型,提高了空間分辨率,並使用了幀插值組件增加了更多的幀,使視訊變得流暢。
當然,目前Make-A-Video的結果仍有缺點,就如同文字到圖像的模型一樣。但我們都知道,AI領域的進展是多麼神速。
如果你想進一步了解,可以參考連結中Meta AI的論文。社群也正在開發一個PyTorch的實現,如果你想自己實現它,請繼續關注。
作者介紹
這篇論文中有多位華人研究者參與:殷希、安捷、張宋揚、Qiyuan Hu。
殷希,FAIR研究科學家。先前曾任職微軟,擔任Microsoft Cloud and AI 的高級應用科學家。在密西根州立大學電腦科學與工程系獲博士學位,2013年畢業於武漢大學電機工程專業,獲學士學位。主要研究領域為多模態理解、大規模目標偵測、人臉推理等。
安捷,羅徹斯特大學電腦科學系博士生。師從羅傑波教授。此前於 2016 年和 2019 年在北京大學獲得學士和碩士學位。研究興趣包括電腦視覺、深度生成模型和AI 藝術。作為實習生參與了Make-A-Video研究。
張宋揚,羅徹斯特大學電腦科學系博士生,師從羅傑波教授。在東南大學獲得學士學位,在浙江大學獲得碩士學位。研究興趣包括自然語言矩定位、無監督語法歸納、基於骨架的動作辨識等。作為實習生參與了Make-A-Video研究。
Qiyuan Hu,當時FAIR的AI Resident,從事提升人類創造力的多模態生成模式的研究。她在芝加哥大學獲得醫學物理學博士學位,並從事AI輔助的醫學影像分析工作。現已任職Tempus Labs,任機器學習科學家。
網友大受震撼
前段時間,Google等大廠紛紛放出自家的文字到圖像模型,如Parti,等等。
有人甚至認為文字到影片生成模型還有一段時間才能到來。
沒想到,Meta這次投了一顆重磅炸彈。
其實,同在今天,還有一個文字到影片產生模型Phenaki,目前已提交到ICLR 2023,由於還處於盲審階段,作者機構還是未知。

網友稱,從DALLE到Stable Diffuson再到Make-A-Video,一切來得太快。

以上是Meta公司創新SOTA模型,能夠根據一句話生成驚人視頻,引爆網絡熱潮!的詳細內容。更多資訊請關注PHP中文網其他相關文章!