



同期群分析
同期群分析概念
同期群(Cohort)的字面意思(有共同特點或舉止類同的)一群人,比如不同性別,不同年齡。
同期群分析:比較的是相似群體隨時間的變化。
產品會隨著你的開發和測試而不斷迭代,這就導致在產品發布第一周就加入的用戶和後來才加入的用戶有著不同的體驗。例如,每個用戶都會經歷一個生命週期:從免費試用,到付費使用,最後停止使用。同時,在這段期間裡,你還在不停地對商業模式進行調整。於是,在產品上線第一個月就「吃螃蟹」的用戶勢必與四個月後才加入的用戶有著不同的上手體驗。這對用戶流失率會有什麼影響?我們用同期群分析來找答案。
每一組使用者構成一個同期群,參與整個試驗過程。透過比較不同的同期群,你可以獲知:從整體來看,關鍵指標的表現是否越來越好了。
結合到用戶分析層面,例如不同月份取得的用戶,不同管道新增用戶,具備不同特徵的用戶(例如微信裡每天至少和10個以上朋友微信的用戶)。
同期群分析(Cohort Analysis),將這些具有不同特徵的族群進行比較分析,以發現他們在時間維度下的行為差異。
因此,同期群分析主要用於以下2點:
對比不同同期群體同一體驗週期的資料指標,驗證產品迭代優化的效果
對比同一同期群體不同體驗週期(生命週期)的資料指標,發現長線體驗的問題
我們在進行同期群分析的時候,大致可以分成2個流程:決定同期群分組邏輯和決定同期群分析的關鍵資料指標。
具有相似行為特徵的群體
具有相同時間週期的群體
例如:
按獲客月份(按週甚至按天分組)
#按獲客頻道
#依照使用者完成的特定行為,例如使用者造訪網站的次數或購買次數來分類。
關於關鍵資料指標,需要是基於時間維度下的例如留存、營收、自傳播係數等等。
以下是以留存率作為指標的案例範例:
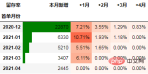
#下面是某電商的營運數據,我們將以該數據示範用python進行同期群分析。
同期群分析案例詳解:
資料是某電商使用者付費日誌,日誌欄位包含日期、付費金額和使用者id,已脫敏處理。
資料讀取
import pandas as pd df = pd.read_csv('日志.csv', encoding="gb18030") df.head()
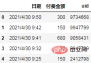
分析方向
#分組邏輯:
這裡只依照使用者的初始購買月份進行分組,如果日誌包含的分類欄位較多(例如頻道、性別或年齡等),可以考慮更多種分組邏輯。
關鍵數據指標:
針對此份數據,至少有3個數據指標可以進行分析:
。留存率
人均付款金額
人均購買次數
資料預處理
因為我們是依照月份分組,所以需要先將日期重採樣為月份:
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
df.head()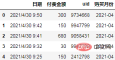
#計算每個使用者在每個月的付費總額:
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额","sum"),
月付费次数=("uid","count"),
)
order.head()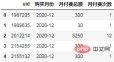
計算每個用戶的首單購買月份作為同期群分組,並將其對應到原始資料:
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order.head()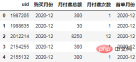
計算每筆購買記錄的時間與首單購買時間的月份差,並重置月份差標籤:
order["标签"] = (order.购买月份-order.首单月份).apply(lambda x:"同期群人数" if x.n==0 else f"+{x.n}月")
order.head()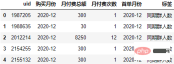
兩個月均為時期類型,相減後得到object類型的列,而該列每個元素的類型是pandas._libs.tslibs.offsets.MonthEnd
MonthEnd類型具有屬性n能傳回具體差值整數。
同期群分析
前面我們說了至少有3個資料指標可以進行分析:
留存率
人均付款金額
人均購買次數
从留存率角度进行同期群分析
通过数据透视表可以一次性计算所需的数据:
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number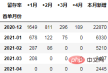
注意:rename_axis(columns=None)用于删除列标签的轴名称。rename_axis(columns=“留存率”)则设置轴名称为留存率。
将 本月新增 列移动到第一列:
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number
具体过程是先通过pop删除该列,然后插入到0位置,并命名为指定的列名。
在本次的分析中,留存率的具体计算方式为:+N月留存率=+N月付款用户数/首月付款用户数
cohort_number.iloc[:, 1:] = cohort_number.iloc[:, 1:].divide(cohort_number.本月新增, axis=0) cohort_number
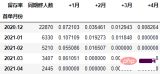
以百分比形式显示,并设置颜色:
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
out1
至此计算完毕。
从人均付款金额角度进行同期群分析
要从从人均付款金额角度考虑,需要考虑同期群基期这个整体。具体计算方式是先计算各月的付款总额,然后除以基期的总人数:
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out2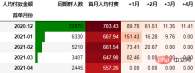
可以看到,12月份的同期群首月新用户人均消费为703.43元,然后逐月递减,到+4月后这些用户人均消费仅11.41元。而随着版本的迭代发展,新增用户的首月消费并没有较大提升,且接下来的消费趋势反而不如12月份。由此可见产品的发展受到了一定的瓶颈,需要思考增长营收的出路了。
一般来说, 通过同期群分析可以比较好指导我们后续更深入细致的数据分析,为产品优化提供参考。
从人均购买次数角度进行同期群分析
依然按照上面一样的套路:
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out3
可以得到类似上述一致的结论。
每月总体付费情况
下面我们看看每个月的总体消费情况:
order.groupby("购买月份").agg(
付费人数=("uid", "count"),
人均付款金额=("月付费总额", "mean"),
月付费总额=("月付费总额", "sum")
)
可以看到总体付费人数和付费金额都在逐月下降。
将结果导出网页或截图
对于Styler类型,我们可以调用render方法转化为网页源代码,通过以下方式即可将其导入到一个网页文件中:
with open("out.html", "w") as f:
f.write(out1.render())
f.write(out2.render())
f.write(out3.render())如果你的电脑安装了谷歌游览器,还可以安装dataframe_image,将这个表格导出为图片。
安装:pip install dataframe_image
import dataframe_image as dfi dfi.export(obj=out1, filename='留存率.jpg') dfi.export(obj=out2, filename='人均付款金额.jpg') dfi.export(obj=out3, filename='人均购买次数.jpg')
dfi.export的参数:
obj : 被导出的Datafream对象
filename : 文件保存位置
fontsize : 字体大小
max_rows : 最大行数
max_cols : 最大列数
table_conversion : 使用谷歌游览器或原生’matplotlib’, 只要写非’chrome’的值就会使用原生’matplotlib’
chrome_path : 指定谷歌游览器位置
整体完整代码
import pandas as pd
import dataframe_image as dfi
df = pd.read_csv('日志.csv', encoding="gb18030")
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额", "sum"),
月付费次数=("uid", "count"),
)
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order["标签"] = (
order.购买月份-order.首单月份).apply(lambda x: "同期群人数" if x.n == 0 else f"+{x.n}月")
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number.iloc[:, 1:] = cohort_number.iloc[:,1:].divide(cohort_number.同期群人数, axis=0)
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
outs = [out1, out2, out3]
with open("out.html", "w") as f:
for out in outs:
f.write(out.render())
display(out)
dfi.export(obj=out1, filename='留存率.jpg')
dfi.export(obj=out2, filename='人均付款金额.jpg')
dfi.export(obj=out3, filename='人均购买次数.jpg')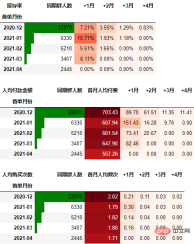
以上是Python在同期群分析中的應用方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Python中的合併列表:選擇正確的方法May 14, 2025 am 12:11 AM
Python中的合併列表:選擇正確的方法May 14, 2025 am 12:11 AMTomergelistsinpython,YouCanusethe操作員,estextMethod,ListComprehension,Oritertools
 如何在Python 3中加入兩個列表?May 14, 2025 am 12:09 AM
如何在Python 3中加入兩個列表?May 14, 2025 am 12:09 AM在Python3中,可以通過多種方法連接兩個列表:1)使用 運算符,適用於小列表,但對大列表效率低;2)使用extend方法,適用於大列表,內存效率高,但會修改原列表;3)使用*運算符,適用於合併多個列表,不修改原列表;4)使用itertools.chain,適用於大數據集,內存效率高。
 Python串聯列表字符串May 14, 2025 am 12:08 AM
Python串聯列表字符串May 14, 2025 am 12:08 AM使用join()方法是Python中從列表連接字符串最有效的方法。 1)使用join()方法高效且易讀。 2)循環使用 運算符對大列表效率低。 3)列表推導式與join()結合適用於需要轉換的場景。 4)reduce()方法適用於其他類型歸約,但對字符串連接效率低。完整句子結束。
 Python執行,那是什麼?May 14, 2025 am 12:06 AM
Python執行,那是什麼?May 14, 2025 am 12:06 AMpythonexecutionistheprocessoftransformingpypythoncodeintoExecutablestructions.1)InternterPreterReadSthecode,ConvertingTingitIntObyTecode,whepythonvirtualmachine(pvm)theglobalinterpreterpreterpreterpreterlock(gil)the thepythonvirtualmachine(pvm)
 Python:關鍵功能是什麼May 14, 2025 am 12:02 AM
Python:關鍵功能是什麼May 14, 2025 am 12:02 AMPython的關鍵特性包括:1.語法簡潔易懂,適合初學者;2.動態類型系統,提高開發速度;3.豐富的標準庫,支持多種任務;4.強大的社區和生態系統,提供廣泛支持;5.解釋性,適合腳本和快速原型開發;6.多範式支持,適用於各種編程風格。
 Python:編譯器還是解釋器?May 13, 2025 am 12:10 AM
Python:編譯器還是解釋器?May 13, 2025 am 12:10 AMPython是解釋型語言,但也包含編譯過程。 1)Python代碼先編譯成字節碼。 2)字節碼由Python虛擬機解釋執行。 3)這種混合機制使Python既靈活又高效,但執行速度不如完全編譯型語言。
 python用於循環與循環時:何時使用哪個?May 13, 2025 am 12:07 AM
python用於循環與循環時:何時使用哪個?May 13, 2025 am 12:07 AMUseeAforloopWheniteratingOveraseQuenceOrforAspecificnumberoftimes; useAwhiLeLoopWhenconTinuingUntilAcIntiment.forloopsareIdealForkNownsences,而WhileLeleLeleLeleLeleLoopSituationSituationsItuationsItuationSuationSituationswithUndEtermentersitations。
 Python循環:最常見的錯誤May 13, 2025 am 12:07 AM
Python循環:最常見的錯誤May 13, 2025 am 12:07 AMpythonloopscanleadtoerrorslikeinfiniteloops,modifyingListsDuringteritation,逐個偏置,零indexingissues,andnestedloopineflinefficiencies


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SublimeText3 Linux新版
SublimeText3 Linux最新版

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

