
今年很火紅的AI繪畫怎麼玩

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-04-17 11:25:021316瀏覽
1、前言
2022年絕對可以說是AIGC元年,從google搜尋的趨勢來看,在2022年AI繪畫及AI生成藝術的搜尋量激增。
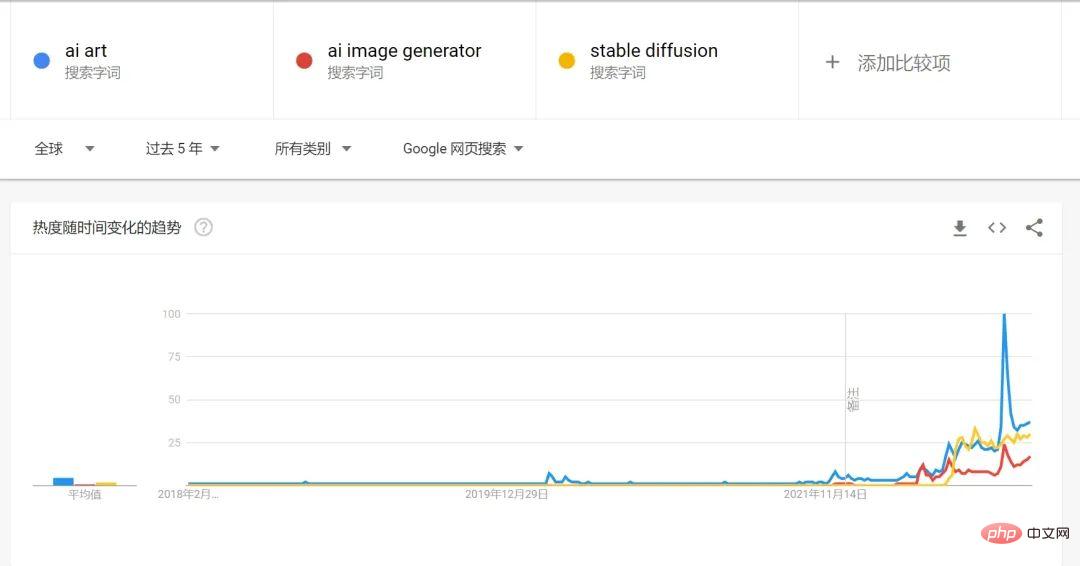
AI繪畫在這一年的爆發一個很重要的原因就是Stable Diffusion 的開源,這也離不開這幾年Diffusion Model擴散模型在這幾年裡的快速發展,結合了OPENAI 已經發展得成熟的文字語言模型GPT-3,從文字到圖片的生成過程變得更加容易。
2、GAN(生成對抗網路)的瓶頸
從14年誕生,到18年的StyleGAN,GAN在圖片生成領域獲得了長足的發展。就好像自然界的掠食者與被掠食者相互競爭共同演化一樣,GAN的原理簡單來說就是使用兩個神經網路:一個作為生成器、一個作為判別器,生成器產生不同的影像讓判別器去判斷結果是否合格,二者互相對抗以此訓練模式。
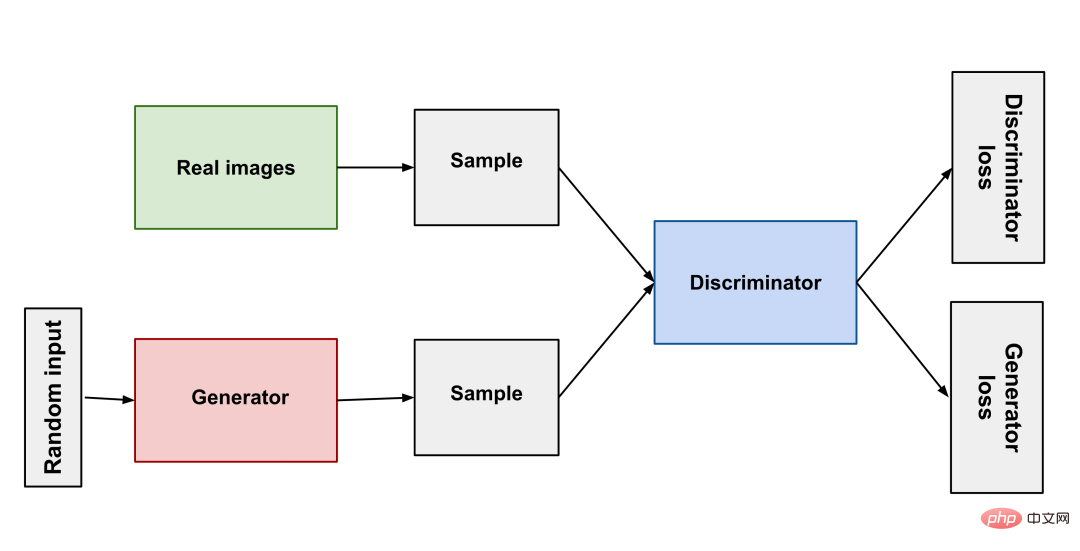
GAN(生成對抗網路)經過不斷發展其有了不錯的效果,但有些始終難以克服的問題:生成結果多樣性缺乏、模式坍縮(生成器在找到最佳模式後就不再進步了)、訓練難度高。這些困難導致 AI 生成藝術一直難以做出實用的產品。
3、Diffusion Model(擴散模型)的突破
在GAN 多年的瓶頸期後,科學家想出了非常神奇的Diffusion Model(擴散模型)的辦法去訓練模型:把原圖用馬爾科夫鏈將雜訊不斷地添加到其中,最終成為一個隨機噪聲圖像,然後讓訓練神經網路把此過程逆轉過來,從隨機噪聲圖像逐漸還原成原圖,這樣神經網路就有了可以說是從無到有生成圖片的能力。而文字產生圖片就是把描述文字處理後當做雜訊不斷加入原圖中,這樣就可以讓神經網路從文字產生圖片。

Diffusion Model(擴散模型)讓訓練模型變得更加簡單,只需大量的圖片就行了,其生成影像的品質也能達到很高的水平,並且生成結果能有很大的多樣性,這也是新一代AI 能有難以讓人相信的「想像力」的原因。
當然技術也是一直在突破的,英偉達在1月底推出的StyleGAN的升級版StyleGAN-T就有了十分驚豔的進步,在同等算力下相比於Stable Diffusion生成一張圖片需要3秒,StyleGAN-T僅需0.1秒。而且在低解析度影像StyleGAN-T要比Diffusion Model好,但在高解析度影像的生成上,還是Diffusion Model的天下。由於StyleGAN-T並沒有像Stable Diffusion那樣獲得廣泛的應用,本文還是以介紹Stable DIffusion為主。
4、Stable Diffusion
在今年早年,AI作畫圈經歷了Disco Diffusion、DALL-E2、Midjouney 群雄混戰的時代,直到Stable Diffusion 開源後,才進入一段時間的塵埃落定,作為最強的AI 作畫模型,Stable Diffusion 引起了AI 社區的狂歡,基本上每天都有新的模型、新的開源庫誕生。尤其是在Auto1111的WebUI版本推出後,無論是部署在雲端還是本地,使用Stable Diffusion都變成一個非常簡單的事情,並且隨著社區的不斷開發,很多優秀的項目,比如Dreambooth、deforum都作為Stable Diffusion WEBUI版的一個插件加入進來,讓像是微調模型、生成動畫等功能都能一站式完成。
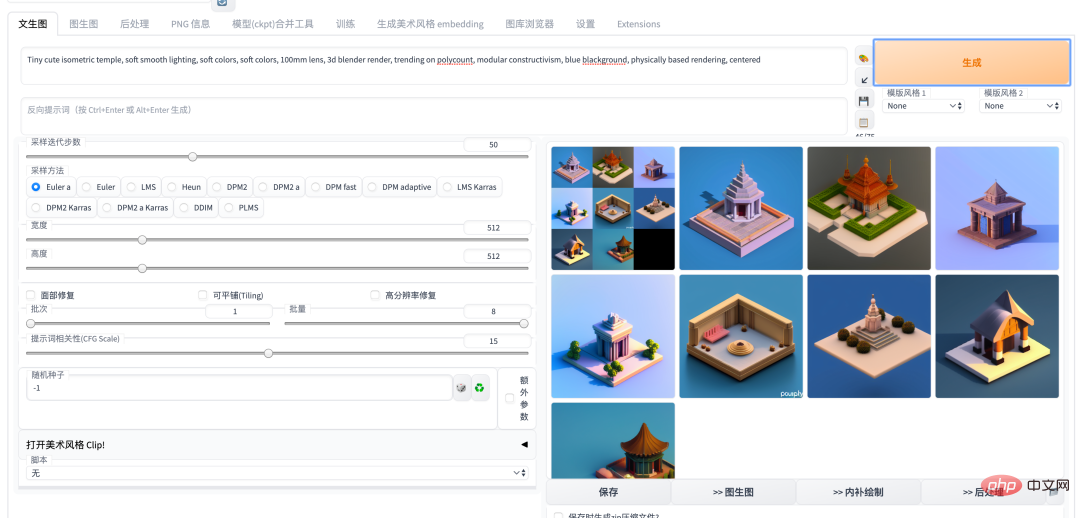
5、AI繪畫玩法及能力介紹
以下介紹目前使用Stable Diffusion 可以有哪些玩法以及能力
#Stable Diffusion 能力簡介(以下圖片使用SD1.5模型輸出) | ||||||||||||||||
簡介 |
輸入 |
|||||||||||||||
| #text2img |
透過文字描述產生圖片,可透過文字描述指定藝術家風格、藝術類型。這裡以藝術家 Greg Rutkowski 的風格舉例。
|
|||||||||||||||
|
a beautiful girl with a flowered shirt posing for a picture with her chin resting on her right hand, by Greg Rutkowski |
|
|||||||||||||||
|
|
|
|||||||||||||||
|
#使用DreamBooth 基於SD 模型訓練微調的大模型,訓練後使用此模型可使用上述的text2img img2img 等能力 |
NovelAI | #text2img目前效果最好的二次元動漫畫風的模型, 由 NAI 基於danbooru 站的公開圖片作為數據集訓練,但由於danbooru 本身存在版權問題,NovelAI一直比較受爭議,並且此模型是商用服務洩漏流出,使用需謹慎。 |
|
|||||||||||||
| #NovelAI | ##img2img
使用NovelAI 的模型進行img2img。目前在各個社區很火的意間AI作畫,也是使用的這個能力。但意間在免責聲明中提到他們的動漫模型是自己收集的資料集訓練的。 a beautiful girl with a flowered shirt posing for a picture with her chin resting on her right hand
|
|
||||||||||||||
| #################################### ###基於使用者照片訓練的主體模型### | 基於使用者提供的幾張照片訓練一個針對主體的模型,用這個模型可以根據描述產生任意包含該主體的圖片。 |
此組圖使用同事的20張照片基於Stable Diffusion 1.5模型訓練2000步驟模型,配合幾個風格化的prompt輸出。 prompt範例(圖1): portrait of alicepoizon, highly detailed vfx portrait, unreal engine, greg rutkowski, loish, rhads, caspar david friedrich, makotootoin, and lois van 素kuvshinov, rossdraws, elegent, tom bagshaw, alphonse mucha, global illumination, detailed and intricate environment *alicepoizon是訓練此模型時為這個人物的命名 |
|
|||||||||||||
|
此組圖使用了得物數字收藏ME.X訓練微調出的風格模型產生。
|
||||||||||||||||
|
|
||||||||||||||||
|
|
||||||||||||||||
|
# 6、目前主要應用程式介紹
建立後開機並啟動JupterLab,
9、參考資料
https://sspai.com/ post/76277
https://blog.csdn.net/ qq_45848817/article/details/127808815
…https://thetheais .com/# ##GAN 結構概觀
##The absolute bener a magical introduction to AI art
https://www.php.cn/ link/81d7118d88d5570189ace943bd14f142timbrooks/instruct-pix2pix ###### |
||||||||||||||||


















 先在AutoDL上註冊帳號並且租一台 A5000/RTX3090 顯示卡的雲端主機。 https://www.autodl.com/market/list
先在AutoDL上註冊帳號並且租一台 A5000/RTX3090 顯示卡的雲端主機。 https://www.autodl.com/market/list
以上是今年很火紅的AI繪畫怎麼玩的詳細內容。更多資訊請關注PHP中文網其他相關文章!