
任務通用!清華提出主幹網路Flowformer,實現線性複雜度|ICML2022

- 王林轉載
- 2023-04-16 19:25:011562瀏覽
任務通用是基礎模型研究的核心目標之一,同時也是深度學習研究通往高階智慧的必經之路。近年來,由於注意力機制的通用關鍵建模能力,Transformer在許多領域中表現優異,逐漸呈現通用架構的趨勢。但是隨著序列長度的增長,標準注意力機制的計算呈現二次複雜度,嚴重阻礙了其在長序列建模與大模型中的應用。
為此,來自清華大學軟體學院的團隊深入探索了這個關鍵問題,提出了任務通用的線性複雜度主幹網路Flowformer,在保持標準Transformer的通用性的同時,將其複雜度降至線性,論文被ICML 2022接受。

作者表:吳海旭,吳佳龍,徐介暉,王建民,龍明盛
##連結:https://arxiv.org/pdf/2202.06258.pdf
- 程式碼:https://github.com/thuml/ Flowformer
- 相較於標準Transformer,本文提出的Flowformer模型,具有下列特點:
- ##線性複雜度,可以處理數千長度的輸入序列;沒有引入新的歸納偏好 ,維持了原有註意力機制的通用建模能力;
任務通用,在
長序列、視覺、自然語言、時間序列、強化學習五大任務上取得優秀效果。
1. 問題分析
標準的注意力機制輸入包含queries(),keys()和values()三部分,,其計算方式如下:其中為注意力權重矩陣,最終計算結果為將進行加權融合所得,上述過程計算複雜度為。注意到,對於多項矩陣的連乘問題,在經典演算法中已有較多研究。特別地,對於注意力機制,我們可以利用矩陣乘法的結合律來實現最佳化,如,即可將原本的二次複雜度降至線性。但是注意力機制中的函數使得無法直接應用結合律。因此,如何移除注意力機制中的函數是實現線性複雜度的關鍵。但是,近期的眾多工作證明,函數在避免平凡注意力學習上起到了關鍵性作用。綜上,我們期待一種模型設計方案,實現以下目標:(1)移除函數;(2)避免平凡注意力;(3)維持模型的通用性。2. 動機針對目標(1),在先前的工作中,往往使用核方法來取代函數,即透過近似注意力計算(為非線性函數),但直接去掉會造成平凡注意力。為此,針對目標(2),先前工作不得不引入一些歸納偏好,這限制了模型的通用性
,因此不滿足目標(3),例如cosFormer中的局部性假設等。Softmax中的競爭機制為滿足上述目標,我們從的基本性質出發進行分析。我們注意到,最初被提出是用於:將「贏者全拿」的取極大值操作擴展為可微分形式。因此,得益於其內在的「競爭」機制,它可以使各個token之間的注意力權重差異化,從而避免了平凡的注意力的問題。 基於上述考慮,我們試圖將競爭機制引入註意力機制設計,從而避免核方法分解帶來平凡注意力問題。 網路流中的競爭機制
我們關注在圖論中的經典網路流(Flow network)模型中,「守恆」
(Conservation)是一個重要現象,即每個節點的流入量等於流出量。受到「固定資源情況下,必定引起競爭」的啟發,在本文中,我們試圖從網絡流視角重新分析經典注意力機制中的信息流動,並透過守恆性質將競爭引入註意力機制設計,以避免平凡注意力問題。 3. Flowformer3.1 網路流視角下的注意力機制
######在註意力機制內部:資訊流可以表示為:從# ##來源###(source,對應)基於學習到的###流容量###(flow capacity,對應注意力權重)匯聚至###匯###(sink,對應)。 ######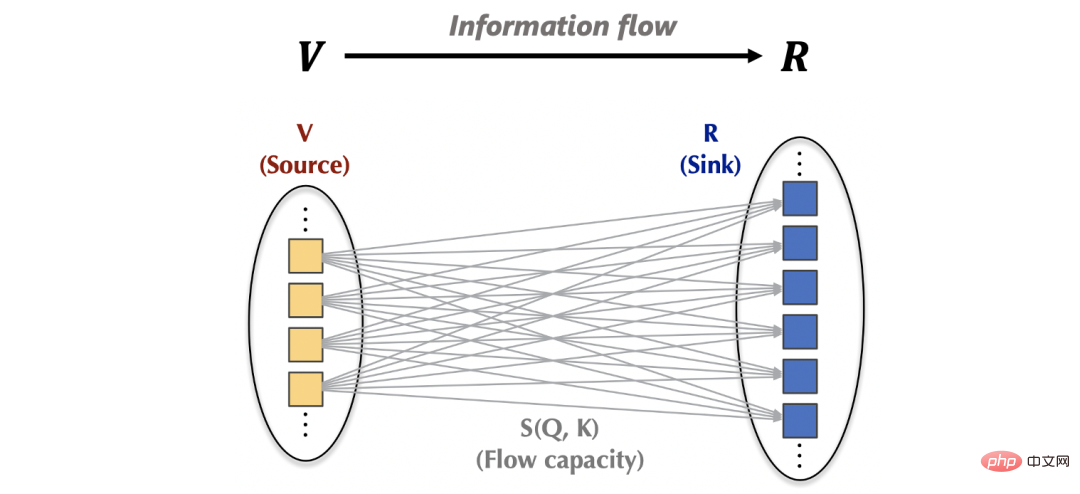
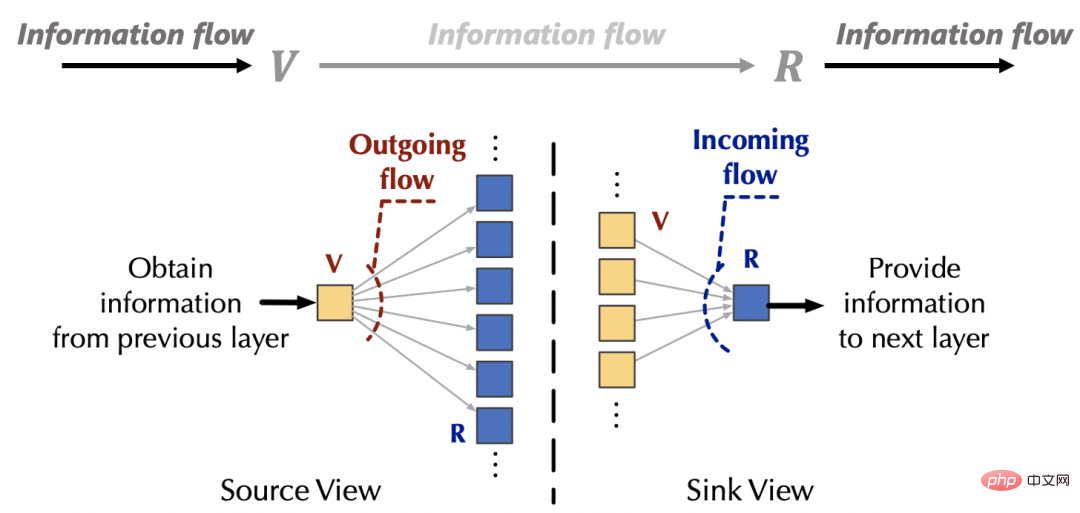
在註意力機制外部,來源(v)的資訊來自上一層網絡,匯(R)的資訊也將提供給下面的前饋層。
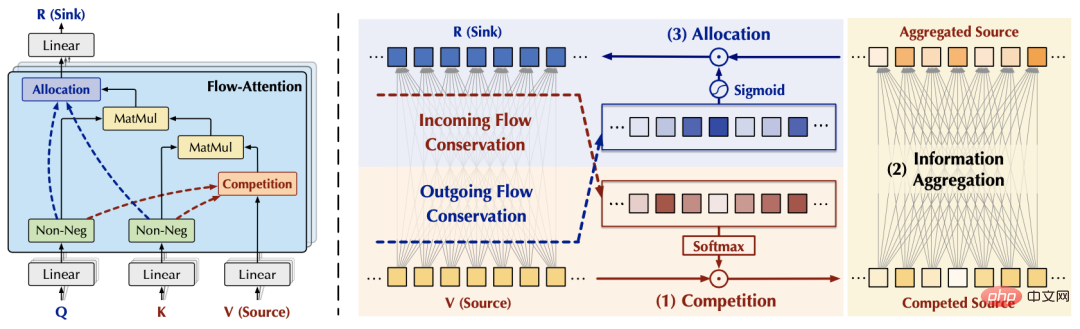
3.2 Flow-Attention
基於上述觀察,我們可以透過分別從流入和流出兩個角度,控制注意力機制與外部網路的交互,來實現「固定資源」,從而分別引起源和匯內部的競爭,以避免平凡注意力。不失一般性,我們將注意力機制與外部網路的交互資訊量設定為預設值1.
(1)匯(R)的流入守恆:
不難取得,未經過守恆之前,對於第個匯,其流入的資訊量為: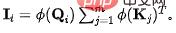 。為了固定每個匯流入的資訊量為單位1,我們將
。為了固定每個匯流入的資訊量為單位1,我們將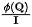 作為歸一化引入資訊流(注意力權重)的計算。經過歸一化之後,第個彙的流入資訊量為:
作為歸一化引入資訊流(注意力權重)的計算。經過歸一化之後,第個彙的流入資訊量為: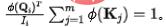
#此時,由於彙的流入守恆,各個源(V)之間存在天然的競爭關係,我們計算此時每個源(V)給出的資訊量,即可得到:競爭情況下,每個源所提供的資訊量,這也代表著每個源的重要性。
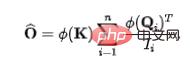
(2)源(V)的流出守恆:與前述過程類似,未經守恆之前,對於第個源,其流出的資訊量為: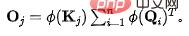 。為了固定每個源流出的資訊量為單位1,我們將作為歸一化引入資訊流(注意力權重)的計算。經過歸一化之後,第j個源的流出資訊量為:
。為了固定每個源流出的資訊量為單位1,我們將作為歸一化引入資訊流(注意力權重)的計算。經過歸一化之後,第j個源的流出資訊量為: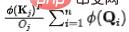 。此時,由於源的流出守恆,各個匯()之間存在天然的競爭關係,我們計算此時每個匯()接受的資訊量,即可得到:競爭情況下,每個結果所需要最終所接受的資訊量。
。此時,由於源的流出守恆,各個匯()之間存在天然的競爭關係,我們計算此時每個匯()接受的資訊量,即可得到:競爭情況下,每個結果所需要最終所接受的資訊量。
(3)整體設計
#基於上述結果,我們設計如下Flow-Attention機制,具體包含競爭(Competition)、聚合(Aggregation)、分配(Allocation)三部分:其中Competition將競爭機制引入中,突出重要的資訊;Aggregation基於矩陣結合律實現線性複雜度;Allocation透過將競爭機制引入,控制傳遞到下一層的資訊量。上述過程中的所有操作均為線性複雜度。同時,Flow-Attention的設計僅依賴網路流中的守恆原理,對資訊流的重新整合,因此並沒有引入新的歸納偏好,保證了模型的通用性。將標準Transformer中的二次複雜度Attention替換為Flow-Attention,即得到了Flowformer。
4. 實驗
本文在標準資料集上進行了廣泛的實驗:
- 涵蓋了長序列、視覺、自然語言、時間序列、強化學習五大任務;
- 檢視了標準(Normal)和自回歸任務(Causal)兩種注意力機制類型。
- 涵蓋了多種序列長度的輸入情況(20-4000)。
- 比較了各領域經典模型、主流深度模型、Transformer及其變體等多種基準方法。
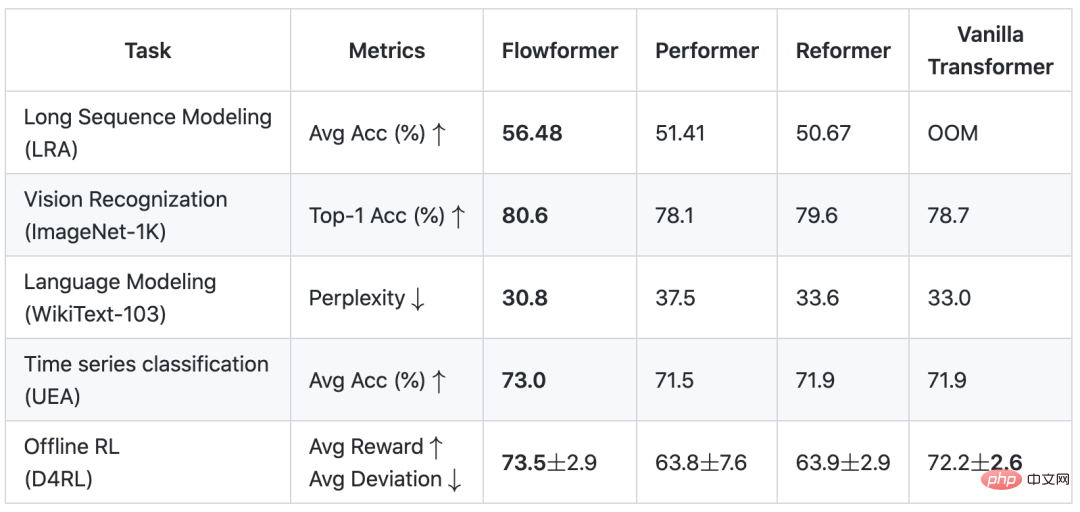
如下表所示,Flowformer在五大任務上皆表現優秀,驗證了模型的通用性。詳細實驗結果請見論文。
5. 分析
為了進一步說明Flowformer的工作原理,我們對ImageNet分類任務中的注意力(對應Flow-Attention中的)進行了可視化實驗,從中可以發現:
- 如果僅使用核方法進行分解,如Linear Transformer,會造成模型注意力分散,無法有效捕捉關鍵區域;
- 經典Transformer和Flowformer均可以準確捕捉到影像的關鍵位置,但是後者在計算複雜度上具有優勢;
- cosFormer在註意力機制中引入一維局部性假設,在語言任務上效果突出。但在影像(將2D資料展開成1D序列)中,如果不將局部性假設擴展至二維,則無法適配視覺任務。這也印證了Flowformer中「沒有引進新的歸納偏好」設計方式的優勢。
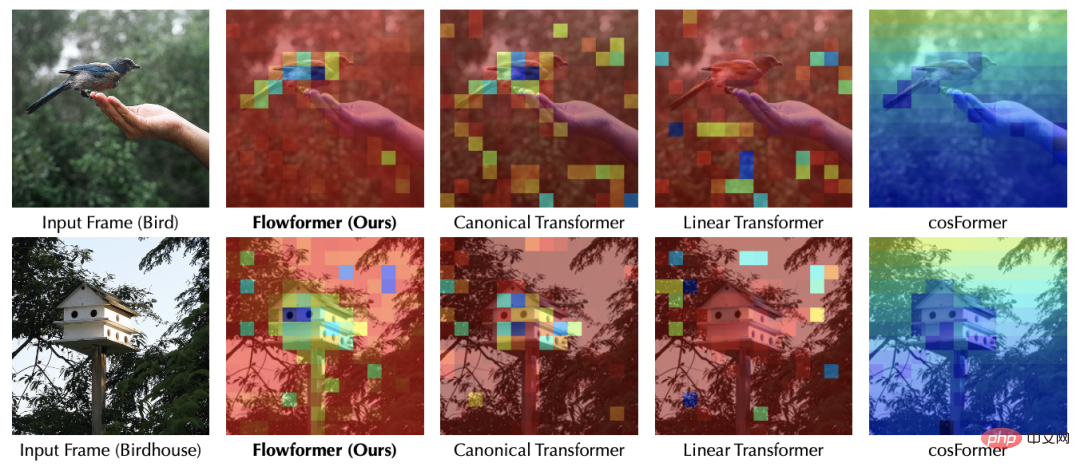
上述視覺化表明,透過Flow-Attention將競爭引入註意力機制設計可以有效避免平凡注意力。更多可視化實驗可見論文。
6. 總結
本文提出的Flowformer透過將網路流中的守恆原理引入設計,自然地將競爭機制引入註意力運算中,有效避免了平凡注意力問題,在實現線性複雜度的同時,保持了標準Transformer的通用性。 Flowformer在長序列、視覺、自然語言、時間序列、強化學習五大任務上取得優秀效果。此外,Flowformer中「無特殊歸納偏好」的設計理念也對通用基礎架構的研究具有一定的啟發性。在未來工作中,我們將進一步探索Flowformer在大規模預訓練上的潛力。
以上是任務通用!清華提出主幹網路Flowformer,實現線性複雜度|ICML2022的詳細內容。更多資訊請關注PHP中文網其他相關文章!