



今年,DeepMind 公佈了大約 2.2 億種蛋白質的預測結構,它幾乎涵蓋了 DNA 資料庫中已知生物體的所有蛋白質。現在,另一家科技巨頭 Meta 正在填補另一個空白,微生物領域。
簡單來說,Meta 使用 AI 技術預測了約 6 億種蛋白質結構,這些蛋白質來自細菌和其他尚未被表徵的微生物。團隊負責人Alexander Rives 表示:「這些蛋白質是我們所知最少的結構,它們是非常神秘的蛋白質。我認為這些發現為深入了解生物學提供了潛力。」
通常,語言模型是在大量文本上進行訓練的。 Meta 為了將語言模型應用於蛋白質,Rives 及其同事將已知的蛋白質序列作為輸入,這些蛋白質由 20 種氨基酸組成,並以不同的字母表示。然後,該網絡在遮蔽一定比例氨基酸的情況下學會了自動補全蛋白質。
Meta 將這個網路命名為 ESMFold。雖然 ESMFold 預測準確度不如 AlphaFold,但在預測結構方面,它比 AlphaFold 快約 60 倍。這一速度意味著可以將蛋白質結構預測擴展到更大的資料庫。

- 論文網址:https://www.biorxiv.org/content/10.1101/2022.07.20.500902v2
- 專案網址:https://github.com/facebookresearch/esm
如今,作為測試,Meta 決定將他們的模型應用於宏基因組DNA 資料庫,這些DNA 全部來自環境,包括土壤、海水、人類腸道、皮膚和其他微生物棲息地。 Meta AI 宣布推出包含 6 億多個蛋白質的 ESM 宏基因組圖譜(ESM Metagenomic Atlas),它是首個蛋白質宇宙「暗物質」的綜合視圖#。這還是最大的高解析度預測結構資料庫,比任何現有的蛋白質結構資料庫都要大 3 倍,並且是第一個全面、大規模地涵蓋宏基因組蛋白質的資料庫。
Meta 團隊總共預測了超過 6.17 億個蛋白質結構,只花了兩週的時間。 Rives 說,預測是免費的,任何人都可以使用,就像模型的底層程式碼一樣。
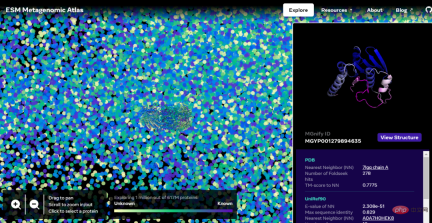
互動版本位址:https://esmatlas.com/explore?at=1,1,21.999999344348925
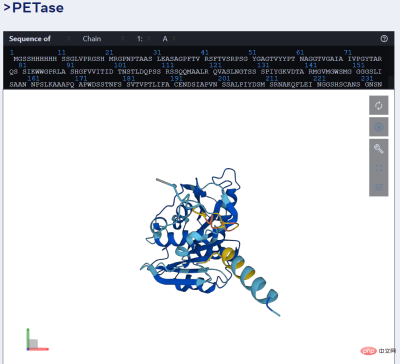
舉例而言,下圖為ESMFold 對PET 酵素的預測。
引言
眾所周知,蛋白質作為複雜且動態的分子,其由基因編碼,主要負責生命基本過程。蛋白質在生物學中有著驚人作用。例如,人類眼睛中的視桿和視錐細胞可以感知光線,因而我們能看到外面的世界;構成聽覺和觸覺基礎的分子感測器;植物中把光能轉化為化學能的複雜分子;驅動微生物和人類肌肉運動的「馬達」;分解塑膠的酵素;保護我們免受疾病的抗體,等等這些都是蛋白質。
1998 年,來自威斯康辛大學植物病理學部門的Jo Handelsman 首次提出宏基因組學(Metagenomics)這一概念,它是源於將來自環境中基因集可以在某種程度上當成單一基因組研究分析的想法,而宏的英文正是meta-,也翻譯為元。
宏基因體學揭示了數十億個對科學來說是新的蛋白質序列,並首次編入由NCBI、歐洲生物資訊研究所(European Bioinformatics Institute) 和聯合基因組研究所(Joint Genome Institute) 等公共計畫編製的大型資料庫中。
Meta AI 開發的新的蛋白質折疊方法,該方法利用大型語言模型,在宏基因組資料庫中(具有數億蛋白質)創建了首個全面的蛋白質結構視圖。 Meta 發現,相對於現有的 SOTA 蛋白質結構預測方法,語言模型可以將預測蛋白質原子級三維結構的速度提高 60 倍。這項進展將有助於加速蛋白質結構理解的新時代,這是首次人類有可能了解基因定序技術正在編目的數十億蛋白質的結構。
解鎖隱藏的自然世界:宏基因組結構空間的首個綜合視圖
我們知道,基因定序的進步使得對數十億個宏基因組蛋白序列進行編目成為可能。但是,透過實驗確定數以億計蛋白質的 3D 結構遠遠超出了時間密集型實驗室技術的範圍,例如 X 射線晶體學,它可能需要數週乃至數年的時間來檢測單個蛋白質。計算方式可以讓我們深入了解使用實驗技術無法實現的宏基因體學蛋白質。
ESM 宏基因組圖譜將使科學家能夠在數億蛋白質的尺度上搜尋和分析宏基因組蛋白質的結構。這可以幫助識別以前未被表徵的結構,尋找遙遠的演化關係,並發現可用於醫學和其他應用的新蛋白質。
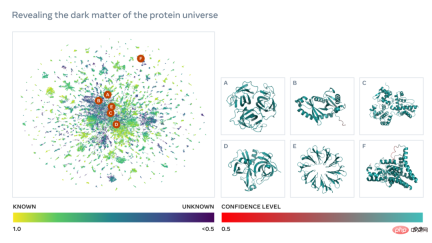
如下為一張包含數以萬計高置信度預測的圖譜,顯示了與目前已知結構的蛋白質的相似性。並且,該圖像首次顯示了完全未知的蛋白質結構空間的更大區域。
學習閱讀生物學語言
如下圖所示,ESM-2 語言模型經過訓練,可以預測演化過程中被序列掩蓋的胺基酸。 Meta AI 發現,作為訓練的結果,蛋白質結構的資訊出現在該模型的內部狀態中。這實在令人驚訝,因為該模型僅在序列上進行了訓練。

就像論文或信件的文字一樣,蛋白質可以寫成字元序列。其中,每個字元對應 20 種標準化學元素(胺基酸)中的一種,每種又具有不同的特性,它們是蛋白質的構建塊。這些構建塊能夠以天文數字的不同方式組合在一起,例如對於由 200 個氨基酸組成的蛋白質,存在 20^200 個可能的序列,這要比可見宇宙中的原子數量還要多。每個序列都折疊成 3D 形狀(但並非所有序列都會折疊成連貫的結構,許多序列折疊成無序形式),而正是這種形狀在很大程度上決定了蛋白質的生物學功能。
學習閱讀這種生物學語言帶來了巨大挑戰。雖然蛋白質序列和文本段落都可以寫成字符,但它們之間存在著深刻而根本性的差異。蛋白質序列描述了一個分子的化學結構,該分子根據物理定律折疊成複雜的 3D 形狀。
蛋白質序列包含了傳遞蛋白質摺疊結構訊息的統計模式。舉例而言,如果一個蛋白質中的兩個位置共同進化,或者換言之,如果其中一個位置出現某種氨基酸,通常與另一個位置的某種氨基酸配對,這可能意味著這兩個位置在折疊結構中相互作用。這類似於拼圖遊戲中的兩塊拼圖,進化必須選擇在折疊結構中拼合在一起的氨基酸。這又意味著我們通常可以透過觀察蛋白質序列中的模式來推斷蛋白質的結構。
ESM 使用 AI 來學習閱讀這些模式。 2019 年,Meta AI 提供證據證明語言模型學習了蛋白質的特性,例如它們的結構和功能。透過一種稱為掩碼語言建模的自我監督學習形式,Meta AI 在數百萬個天然蛋白質的序列上訓練了一個語言模型。使用此方法,模型必須正確填入文本段落中的空白,例如「To _ or not to , that is the _____」。
之後,Meta AI 訓練了一個語言模型來填補蛋白質序列中的空白。他們發現,蛋白質結構和功能的資訊在這項訓練中浮現了出來。 2020 年,Meta 發布了一個 SOTA 蛋白質語言模型 ESM1b,用於各種應用,包括幫助科學家預測 COVID-19 的演變以及發現疾病的遺傳原因。
現在,Meta AI 擴展了這種方法,用來創建下一代蛋白質語言模型 ESM-2,它的參數為 150 億,是迄今為止最大的蛋白質語言模型。他們發現,當模型參數從 800 萬放大到 150 億時,內部表示中會出現訊息,從而能夠以原子分辨率進行 3D 結構預測。
將蛋白質折疊實現數量級加速
在下圖中,隨著模型的擴大,高解析度的蛋白質結構出現。同時隨著模型的縮放,蛋白質結構的原子解析度影像中會出現新的細節。

使用目前SOTA 運算工具,在實際時間範圍內預測數億蛋白質序列結構可能花費數年時間,即便用上主要研究機構的資源也是如此。因此,想要在宏基因組尺度上進行預測,預測速度的突破至關重要。
Meta AI 發現使用蛋白質序列的語言模型大大加快了結構預測的速度,最高提升 60 倍。這足以在短短幾週內對整個宏基因組資料庫做出預測,並且可以擴展到比我們目前發布的資料庫大得多的資料庫。事實上,這種新的結構預測能力能夠在短短兩週內,在大約 2000 個 GPU 組成的集群上預測超過 6 億多個宏基因組蛋白的序列。
此外,目前 SOTA 結構預測方法需要搜尋大型蛋白質資料庫以識別相關序列。這些方法實際上需要一整組進化相關的序列作為輸入,以便它們可以提取與結構相關的模式。 Meta AI 的 ESM-2 語言模型在其對蛋白質序列的訓練過程中學習這些進化模式,進而能夠直接從蛋白質序列中對 3D 結構進行高解析度預測。
下圖展示了使用 ESM-2 語言模型進行蛋白質摺疊。箭頭從左到右顯示了網路中從語言模型到折疊 trunk 再到結構模組的資訊流,最後輸出 3D 座標和置信度。
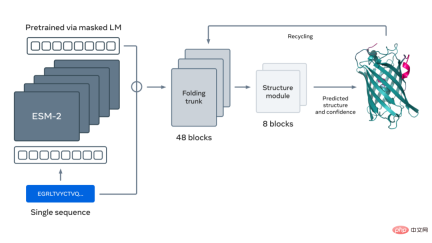
更多詳細內容請參考原文。
#部落格連結:https://ai.facebook.com/blog/protein-folding-esmfold-metagenomics/
以上是Meta AI開放6億+宏基因體蛋白質結構圖譜,150億語言模型用兩週完成的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 使用Python的Google表自動化|分析VidhyaApr 13, 2025 am 10:01 AM
使用Python的Google表自動化|分析VidhyaApr 13, 2025 am 10:01 AMGoogle表是Excel的最受歡迎和廣泛使用的替代方案之一,它提供了具有實時編輯,版本控制和與Google Suite無縫集成等功能的協作環境,允許U
 O1-Mini:一種改變遊戲規則的STEM和推理模型Apr 13, 2025 am 09:55 AM
O1-Mini:一種改變遊戲規則的STEM和推理模型Apr 13, 2025 am 09:55 AMOpenAI引入了O1-Mini,這是一種具有成本效益的推理模型,重點是STEM受試者。該模型在數學和編碼中表現出令人印象深刻的性能,與其前身Openai O1非常相似
 用結構化輸出和功能調用增強LLMApr 13, 2025 am 09:45 AM
用結構化輸出和功能調用增強LLMApr 13, 2025 am 09:45 AM介紹 假設您正在與知識淵博但有時缺乏具體/知情的回答或他/她/她/她在面對複雜問題時不會流利的回應時互動。我們在這裡做什麼
 關於LLM代理商的15個最常見的問題Apr 13, 2025 am 09:41 AM
關於LLM代理商的15個最常見的問題Apr 13, 2025 am 09:41 AM介紹 大型語言模型(LLM)代理是使用LLM作為中央計算引擎的高級AI系統。他們有能力執行特定的行動,做出決策並與外部工具或
 11 YouTube頻道免費學習生成AI -Analytics VidhyaApr 13, 2025 am 09:38 AM
11 YouTube頻道免費學習生成AI -Analytics VidhyaApr 13, 2025 am 09:38 AM介紹 As Generative AI continues to reshape industries from content creation to automation, learning this technology has become essential for aspiring AI professionals and enthusiasts alike.憑藉其巨大的教育
 LLM代理商的10種申請Apr 13, 2025 am 09:34 AM
LLM代理商的10種申請Apr 13, 2025 am 09:34 AM介紹 大型語言模型或LLM是改變遊戲規則的人,尤其是在使用內容時。從支持摘要,翻譯和一代,諸如GPT-4,Gemini和Llama之類的LLM使它變得簡單
 LLM代理如何重塑工作場所?Apr 13, 2025 am 09:33 AM
LLM代理如何重塑工作場所?Apr 13, 2025 am 09:33 AM介紹 大型語言模型(LLM)代理是提高工作場所業務效率的最新創新。他們自動進行重複的活動,促進協作並在各個部門提供有用的見解。與眾不同
 設置法師AI與PostgresApr 13, 2025 am 09:31 AM
設置法師AI與PostgresApr 13, 2025 am 09:31 AM想像一下自己是一個數據專業人士,負責創建有效的數據管道來簡化流程並生成實時信息。聽起來很具有挑戰性,對嗎?那就是法師AI的來源以確保貸款


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

