
儲存操作n維資料的難題,Google用一個開源軟體庫解決了

- 王林轉載
- 2023-04-15 10:52:051610瀏覽
電腦科學與機器學習 (ML) 的許多應用都需要處理跨座標系的多維資料集,單一資料集可能也需要儲存 TB 或 PB 的資料。另一方面,使用此類數據集也具有挑戰性,因為用戶可能會以不規則的間隔和不同的規模讀取和寫入數據,通常還會執行大量的平行工作。
為了解決上述問題,Google開發了一個開源的 C 和 Python 軟體庫 TensorStore,專為儲存和操作 n 維資料而設計。 Google AI 負責人 Jeff Dean 也在推特上發文表示 TensorStore 現已正式開源。
TensorStore 的主要功能包括:
- 提供統一的API 用於讀寫多種陣列格式,包括zarr 和N5;
- 原生支援多種儲存系統,包括Google雲端儲存、本機和網路檔案系統、HTTP 伺服器和記憶體儲存;
- 支援讀取/ 寫入快取和事務,具有很強的原子性、隔離性、一致性和持久性(ACID)特性;
- 支援從多個進程和機器進行安全、高效的並發存取;
- 提供非同步API 以實現對高延遲遠端儲存的高吞吐量存取;
- #提供進階、完全可組合的索引操作和虛擬視圖。
TensorStore 已被用於解決科學運算中的工程挑戰,也被用於建立大型機器學習模型,例如用來管理PaLM 在分散式訓練期間的模型參數(檢查點)。
GitHub 網址:https://github.com/google/tensorstore
用於資料存取和操作的API
TensorStore 提供了一個簡單的Python API 用於載入和操作大型陣列資料。例如,下面的程式碼創建了一個TensorStore 對象,該對象代表一個56 兆體素的蒼蠅大腦3D 圖像,並允許存取NumPy 數組中100x100 的圖像patch 資料:
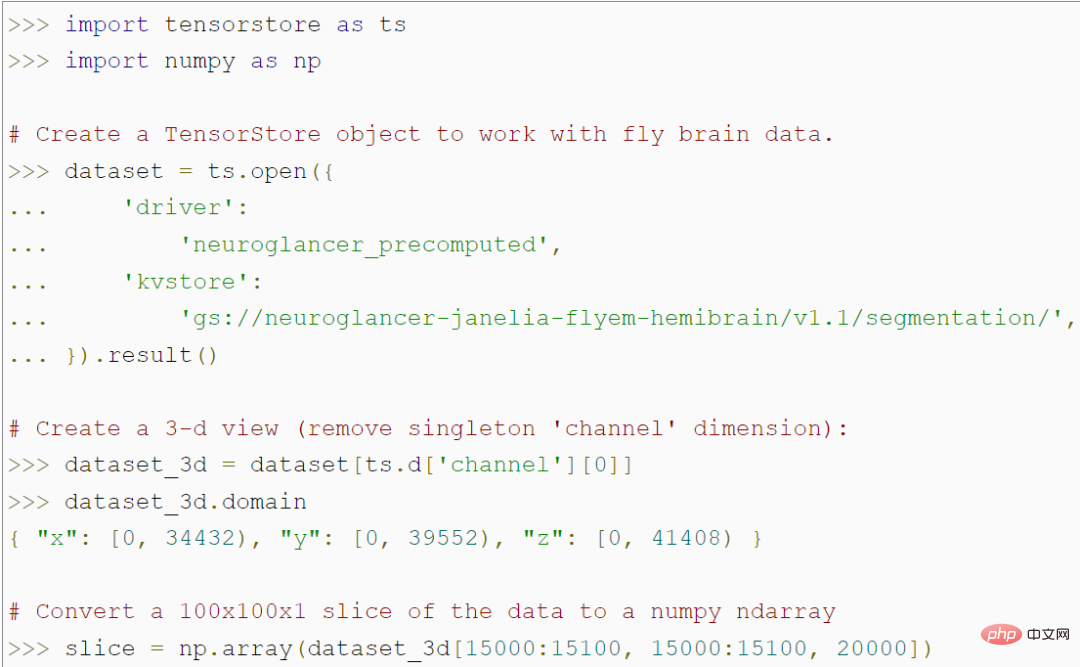
值得注意的是,該程式在存取特定的100x100 patch 之前,不會存取記憶體中的實際數據,因此可以載入和操作任意大的基礎資料集,而無需將整個數據集儲存在記憶體中。 TensorStore 使用與標準 NumPy 基本相同的索引和操作語法。
此外,TensorStore 也為進階索引功能提供廣泛支持,包括對齊、虛擬視圖等。
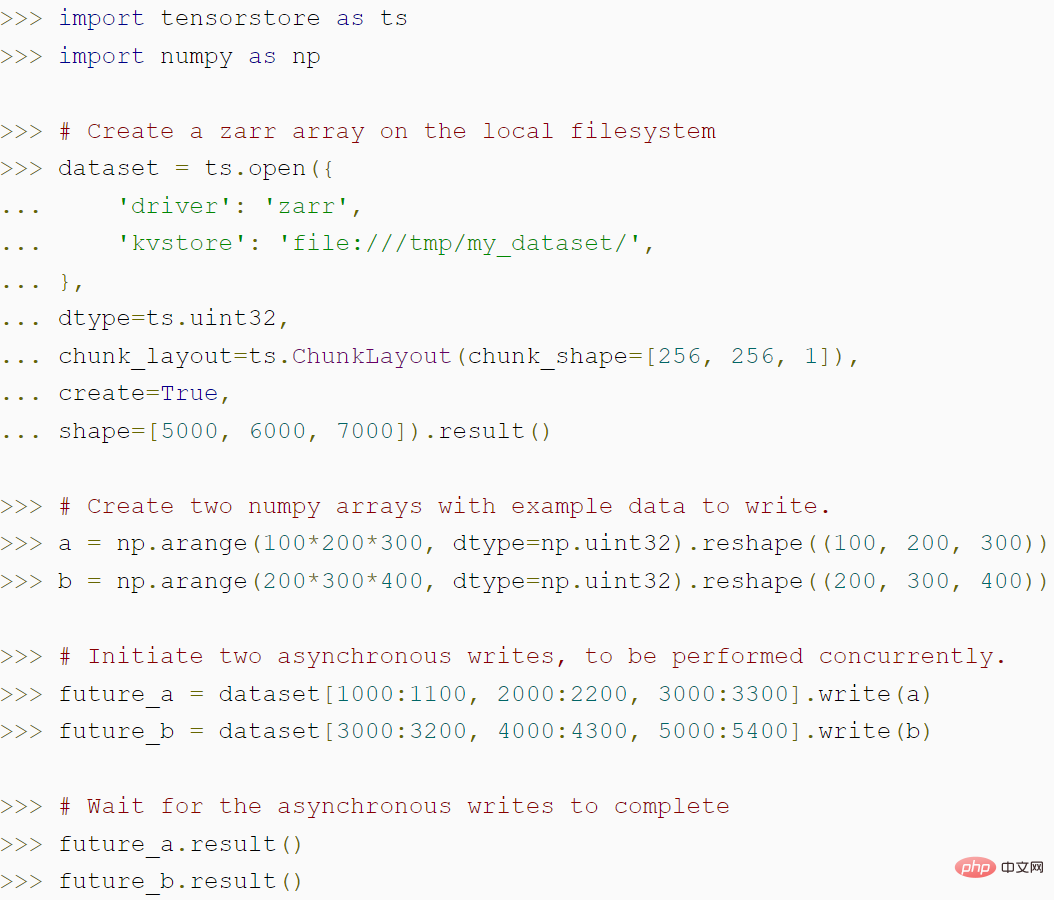
下面的程式碼示範如何使用TensorStore 建立一個zarr 數組,以及TensorStore 的非同步API 如何實現更高的吞吐量:
#安全性和效能擴展
眾所周知,分析和處理大型資料集需要大量的運算資源,通常需要分佈在多個機器上的CPU 或加速器核心的並行化來實現。因此,TensorStore 的一個基本目標是實現並行處理,達到既安全又高效能的目的。事實上,在Google資料中心內的測試中,他們發現隨著CPU 數量的增加,TensorStore 讀寫效能幾乎呈現線性成長:
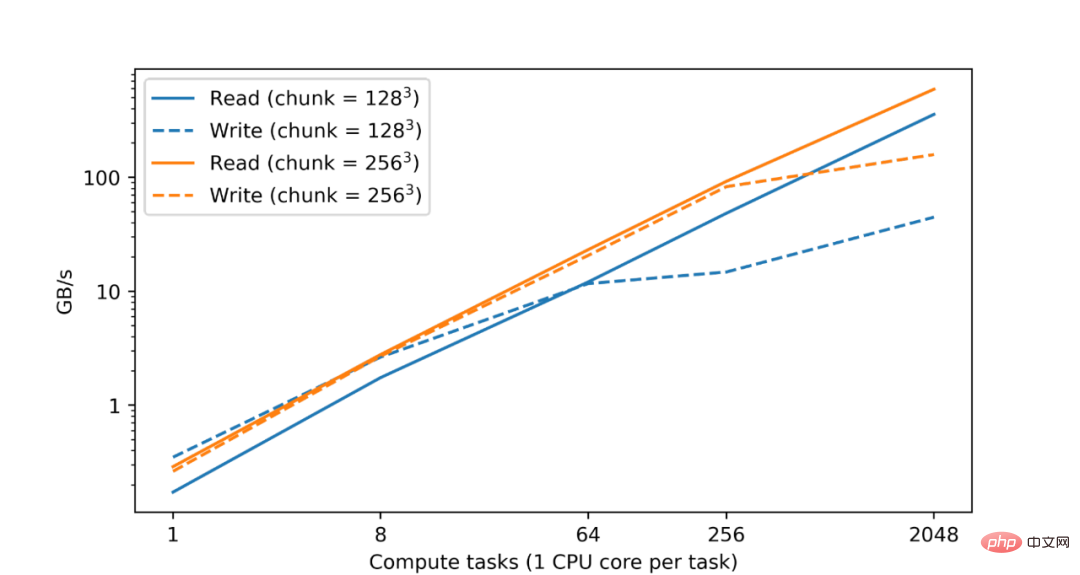
##在Google雲端儲存(GCS) 上對zarr 格式資料集的讀寫效能,讀取和寫入效能與運算任務的數量幾乎成線性成長。
TensorStore 也提供了可設定的記憶體快取和非同步 API,以允許讀寫操作在程式完成其他工作時在後台繼續執行。為了讓 TensorStore 的分散式運算與資料處理工作流程相容,Google還將 TensorStore 與 Apache Beam 等平行運算庫整合。
範例展示
範例 1 語言模型:最近一段時間,機器學習領域出現了一些 PaLM 等高階語言模型。這些模型包含數千億個參數,在自然語言理解和生成方面表現出驚人的能力。不過這些模型對運算設施提出了挑戰,特別是,訓練一個像 PaLM 這樣的語言模型需要數千個 TPU 並行工作。
其中有效地讀取和寫入模型參數是訓練過程面臨的問題:例如訓練分佈在不同的機器上,但參數又必須定時的保存到checkpoint 中;又例如單一訓練必須只讀取特定參數集,以避免載入整個模型參數集(可能是數百GB)所需的開銷。
TensorStore 可以解決上述問題。它已用於管理大型(multipod)模型相關的 checkpoint,並已與 T5X 和 Pathways 等框架整合。 TensorStore 將 Checkpoint 轉換為 zarr 格式存儲,並選擇區塊結構以允許每個 TPU 的分區並行獨立地讀取和寫入。

#當儲存checkpoint 時,參數以zarr 格式寫入,區塊網格被進一步劃分,以便在TPU 上劃分參數網格。主機為分配給該主機的 TPU 的每個分區並行寫入 zarr 區塊。使用 TensorStore 的非同步 API,即使資料仍被寫入持久存儲,訓練也會繼續進行。當從 checkpoint 恢復時,每個主機只讀取分配給該主機的分區塊。
範例 2 大腦 3D 映射:突觸分辨連接組學的目標是在單一突觸連接層級繪製動物和人類大腦的連線。完成這一目標需要在毫米或更大的視野範圍內以極高的分辨率 (奈米級) 對大腦進行成像,由此產生的數據大小達到 PB 級。然而,即使是現在,資料集也面臨著儲存、處理等方面的問題,即使是單一大腦樣本也可能需要數百萬 GB 的空間。
Google已經使用 TensorStore 來解決與大規模連接組學資料集相關的計算挑戰。具體而言,TensorStore 已經開始管理一些連接組學資料集,並將Google雲端儲存作為底層物件儲存系統。
目前,TensorStore 已被用於人類大腦皮質資料集 H01,原始影像資料為 1.4 PB(約 500000 * 350000 * 5000 像素)。之後原始資料被細分為 128x128x16 像素的獨立區塊,以“Neuroglancer precomputed”格式存儲,TensorStore 可以輕鬆的對其進行操作。

利用TensorStore 可以輕鬆存取和操作底層資料(蒼蠅腦重建)
想要上手一試的小夥伴,可以使用以下方法安裝TensorStore PyPI 套件:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tensorstore</span>
以上是儲存操作n維資料的難題,Google用一個開源軟體庫解決了的詳細內容。更多資訊請關注PHP中文網其他相關文章!