自動語音辨識(Automatic Speech Recognition,ASR)技術目前已大規模落地於B站相關業務場景,例如影音內容安全審核,AI字幕(C端,必剪,S12直播等),視訊理解(全文檢索)等。
另外,B站ASR引擎在工業界benchmark SpeechIO (https://github.com/SpeechColab/Leaderboard)2022年11月最近一期全量測評中也取得了第一名(https: //github.com/SpeechColab/Leaderboard#5-ranking)的成績,且在非公開測驗集中優勢更加明顯。
#完整測試集排名 |
排名 |
廠家 |
#字錯誤率 |
1 |
B站 |
2.82% |
2 |
阿里雲 |
2.85% |
|
3 |
依圖 |
3.16% |
4 | 微軟 |
3.28% |
#5 |
|
##3.85% |
##3.85% |
| 6 | #訊息
#4.05% |
|
4.05%
|
| 7
|
思必馳
|
#5.19%
|
8############百度#############8.14%##############
本文將介紹在這一過程中,我們在數據和演算法上所做的累積與探索。
高品質ASR引擎
#一個適合工業化生產的高品質(高性價比)ASR引擎,它應該具有如下的特點:
|
|
|
##說明 |
#高精度 |
在相關的業務場景精確度高,穩健性好 |
高效能 |
#工業化部署延遲低,速度快,運算資源佔用少 |
####高擴展性############能高效支援業務迭代定制,滿足業務快速更新需求########### #####
下面結合B站的業務場景在以上幾個方面介紹我們相關的探索與實務。
資料冷啟動
#語音辨識任務即從一段語音中完整辨識出其中的文字內容(語音轉文字)。
滿足現代工業生產的ASR系統依賴大量且多樣的訓練數據,這裡「多樣」是指說話周圍環境,場景語境(領域)及說話人口音等非同質數據。
針對於B站的業務場景,我們首先需要解決語音訓練資料冷啟動的問題,我們將碰到以下挑戰:
- #冷啟動:開始只有極少量的開源數據,購買的數據和業務場景匹配度很低。
- 業務場景領域廣:B站音視訊業務場景涵蓋數十個領域,可以認為是泛領域,對資料「多樣性」要求很高。
- 中英文混合:B站年輕用戶較多,且有較多中英文混合泛知識類影片。
對於上述問題,我們採用了以下的資料解決方案:
業務資料篩選
#B站存在少量UP主或用戶投稿的字幕(cc字幕),但同時也存在一些問題:
時間戳不準,句子開始和結束時間戳往往在首尾字中間或數個字之後;
語音和文字沒有完全對應,多字,少字,註釋或翻譯,存在按意思理解生成字幕的情況;
數字轉換,例如字幕2002年(實際發音二千零二年,二零零二年等);
#為此,我們基於開源數據,採購的成品數據及少量標註數據訓練一個篩選數據的基礎模型,以投稿字幕文字訓練子語言模型,用來做句子時間對齊及字幕篩選過濾;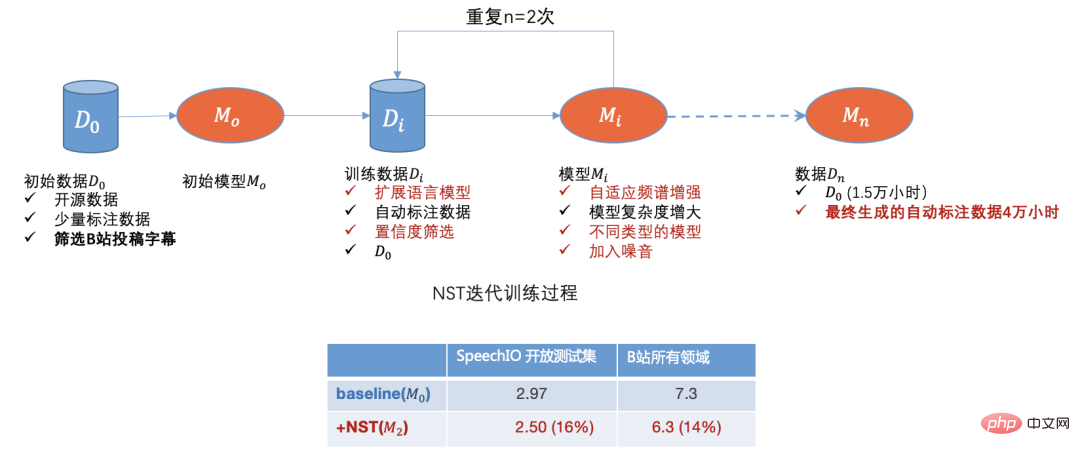
半監督訓練
近年來因數據,GPU運算能力大幅提升及大規模人工標註數據成本過高,業界湧現了大量無監督(wav2vec,HuBERT,data2vec等)[1][2]及半監督訓練方法。
B站存在大量的無標註業務數據,同時我們也從其它網站獲取了大量無標註視頻數據,我們前期採用被稱為NST(Noisy Student Training)[3]的半監督訓練方法,
初期按領域及播放量分佈篩選了近50萬稿件最終生成約4萬小時自動標註數據,加上初始1.5萬小時標註數據訓練後識別精度有相對近15%左右的提升,且模型魯棒性改善明顯。
圖一
透過開源數據,B站投稿數據,人工標註數據及自動標註數據我們初步解決數據冷啟動問題,隨著模型的迭代,我們可以進一步篩選出辨識比較差的領域數據,
這樣形成一個正向循環。初步解決數據問題後,以下我們將重點放在模型演算法相關最佳化。
模型演算法最佳化
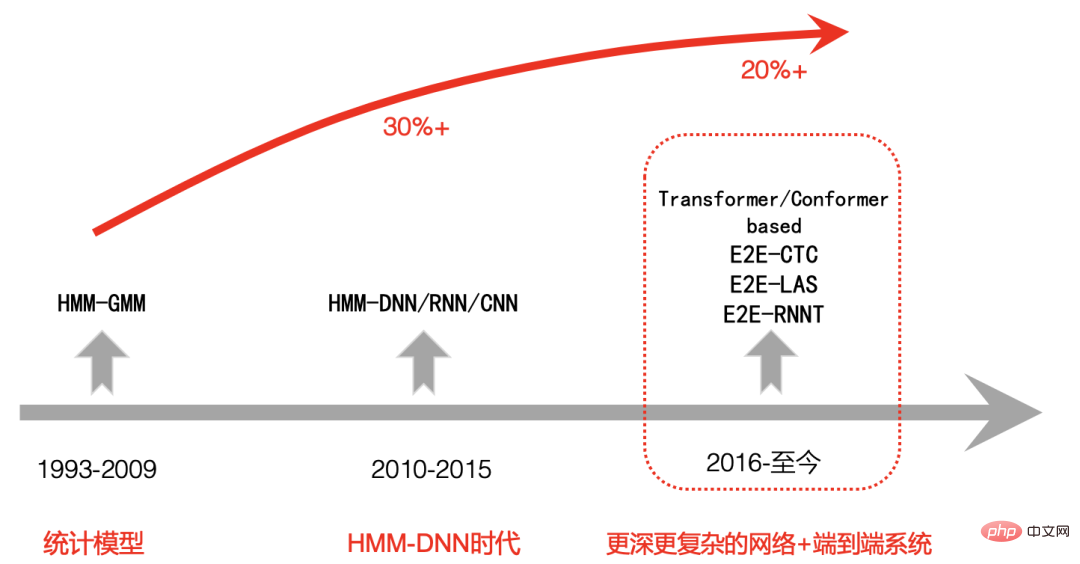
ASR技術發展歷程
我們簡單回顧下現代語音辨識發展歷程,大體可以分為三個階段:
第一階段是從1993年到2009年,語音辨識一直處於HMM-GMM時代,由先前基於標準模板匹配開始轉向統計模型,研究的重點也由小詞彙量、孤立詞轉大詞彙量、非特定人連續語音識別,自90年代以後在很長一段時間內語音辨識的發展比較緩慢,辨識錯誤率沒有明顯的下降。
第二階段是2009年到2015年左右,隨著GPU運算能力的大幅提升,2009年深度學習又開始在語音辨識中興起,語音辨識框架開始轉變為HMM-DNN,開始步入DNN時代,語音辨識準確度得到了顯著的提升。
第三階段是2015年後,由於端對端技術的興起,CV,NLP等其它AI領域的發展相互促進,語音識別開始使用更深,更複雜的網絡,同時採用端到端科技進一步大幅提升了語音辨識的效能,在一些限制的條件下甚至超過了人類等級。
圖二
#B戰ASR技術方案
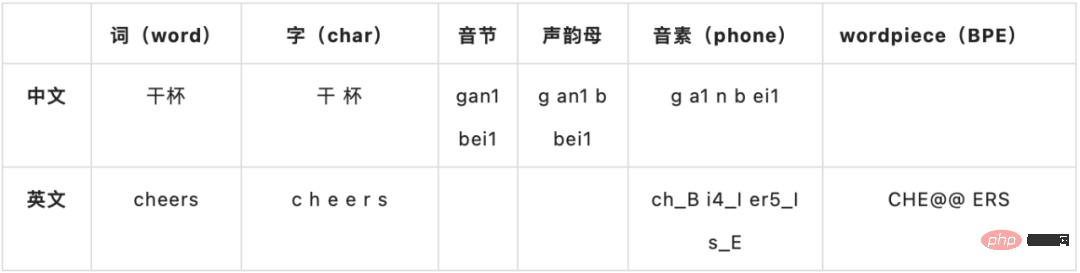
#######重要概念介紹############為方便理解,以下簡單介紹一些重要基礎概念######建模單元######## ##################
Hybrid or E2E
第二階段基於神經網路的混合框架HMM-DNN相比比第一階段HMM-GMM系統語音辨識準確率是有著巨大的提升,這點也得到了大家的共識。
但第三階段端對端(end-to-end,E2E)系統對比第二階段在開始的一段時間業界也有爭議[4],隨著AI技術的發展,特別是transformer相關模型的出現,模型的表徵能力越來越強,
同時隨著GPU運算能力的大幅提升,我們可以加入更多的資料訓練, 端到端方案逐漸展現它的優勢,越來越多的公司選擇端到端的方案。
這裡我們結合B站業務場景比較這兩個方案:
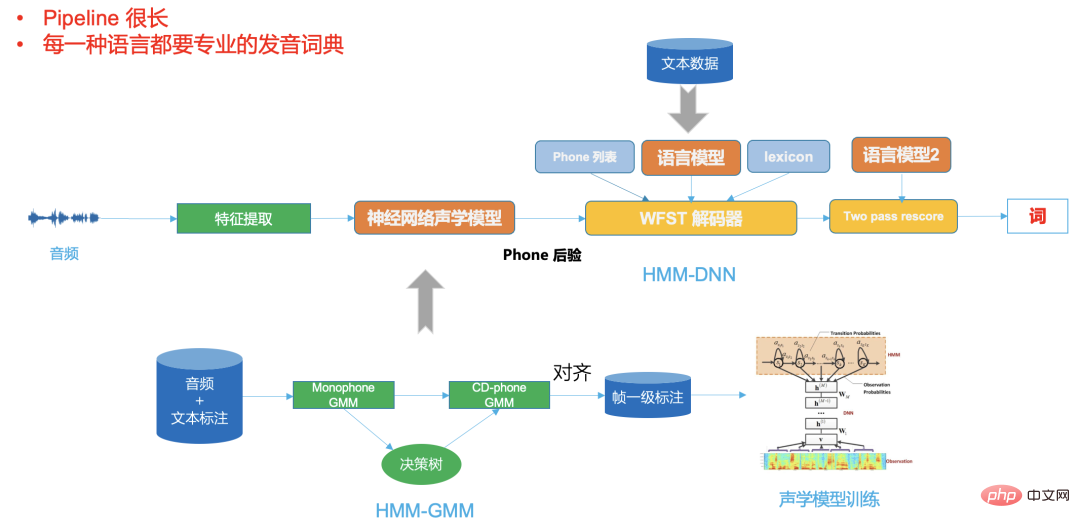
#圖三
圖二是一個典型的DNN- HMM框架,可以看出它的pipeline 很長,不同的語言都需要專業的發音字典,
而圖三端到端系統把所有這些放在一個神經網路模型中,神經網路輸入是音訊(或特徵),輸出即是我們想要的辨識結果。
圖四
隨著技術的發展端對端系統在開發工具,社群及效能上優勢也越來越明顯:
|
#混合框架(hybrid) |
#端對端框架(E2E) |
|
|
##代表性開源工具及社群
|
HTK, Kaldi | Espnet, Wenet, DeepSpeech, K2等 |
程式語言 |
C/C , Shell | Python, Shell |
可擴充性 |
從從頭開始開發
#########TensorFlow/Pytorch## #############
下面表格是典型的資料集基於代表性工具下的最優結果(字錯誤率CER):
|
#混合框架(hybrid) |
端對端框架(E2E) |
#代表工具 |
Kaldi |
Espnet |
#代表技術 |
##tdnn chain rnnlm rescoring
|
conformer-las/ctc/rnnt
|
| #Librispeech
|
3.06
|
1.90
|
| #GigaSpeech
|
14.84
|
10.80
|
| Aishell-1
|
7.43
|
#4.72
|
| ##WenetSpeech
|
#12.83
|
8.80
|
#總之,選擇端對端系統,相較於傳統的混合框架,在資源一定的情況下,我們可以更快、更好的開發出一個高品質的ASR系統。
當然,基於混合框架,如果我們也採用同等先進的模型及高度優化的解碼器也是可以達到和端到端接近的效果,但我們可能需要投入數倍的人力及資源來開發優化這個系統。
端對端方案選擇
#B站每天都有數十萬小時的音訊需要轉寫,對ASR系統吞吐和速度要求都很高,生成AI字幕對精度也有較高的要求,同時B站的場景覆蓋也非常廣泛,選擇一個合理高效的ASR系統對我們來說很重要。
理想的ASR系統
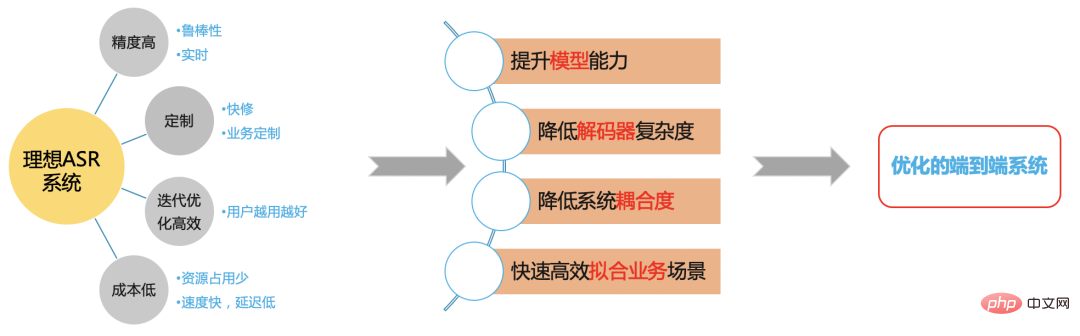
圖五
我們希望基於端對端框架建立一個高效的ASR系統解決在B站場景的問題。
端對端系統比較
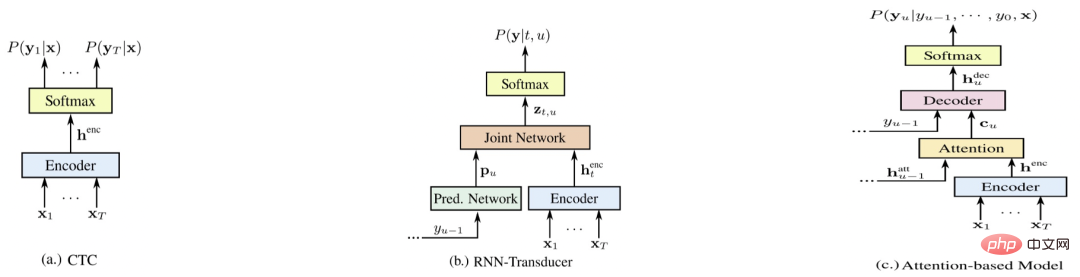
圖六
圖四是現在有代表性的三種端對端系統[5 ],分別是E2E-CTC,E2E-RNNT,E2E-AED,以下從各個面向對比各個系統優缺點(分數越高越好)
|
E2E-AED |
E2E-RNNT |
優化的E2E-CTC |
辨識精確度 |
6 |
5 |
##6
|
| 即時(串流)
|
3
|
#5
|
5
|
| 成本及速度
|
4 |
3 |
#5 |
快修 |
3 |
#3 |
##6 |
| #快速高效迭代
|
6
|
4
| #5
|
|
#2000小時 |
#15000小時 |
#Kaldi Chain model LM |
13.7 |
-- |
|
|
|
|
| # #E2E-AED | 11.8
6.6 |
| E2E- RNNT | 12.4
-- |
##E2E-CTC( greedy) |
13.1 |
#7.1#################優化的E2E- CTC LM############10.2#############5.8###############上面是分別基於2000小時及15000小時視訊訓練資料在B站生活美食場景的結果,其中Chain及E2E-CTC採用了相同語料訓練的擴展語言模型,
E2E-AED及E2E-RNNT並沒有採用擴展的語言模型,端對端系統都是基於Conformer模型。
從第二表格可以看出單一的E2E-CTC系統精度並不明顯弱於其它端對端系統,但同時E2E-CTC 系統存在著以下優點:
- 因為沒有神經網路的自回歸(AED decoder 及RNNT predict)結構,E2E-CTC 系統在流式,解碼速度,部署成本有著天然的優勢;
- 在業務定制上,E2E-CTC 系統也更容易外接各種語言模型(nnlm及ngram),這使得在沒有足夠資料充分涵蓋的通用開放領域其泛化穩定性要明顯優於其它端到端系統。
高品質ASR解決方案
#高精度可擴展ASR框架
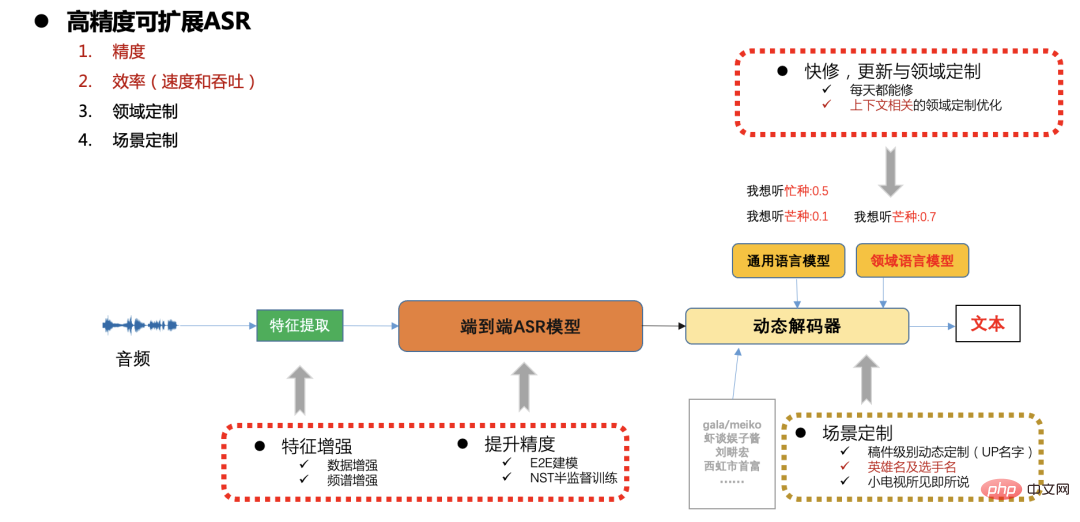
圖七
在B站生產環境中對速度,精度以及資源消耗都有較高的要求,在不同的場景也有快速更新及客製化的需求(如稿件相關的實體詞,熱門遊戲及體育賽事的客製化等),
這裡我們整體採用端對端CTC系統,透過動態解碼器解決可擴展性自訂問題。以下將重點分開闡述模型精度,速度及擴展性優化工作。
端對端CTC區分性訓練
我們系統採用中文字加上英文BPE建模,基於AED及CTC多工訓練完以後,我們只保留CTC部分,後面我們會進行區分性訓練,我們採用端到端的lattice free mmi[6][7]區分性訓練:
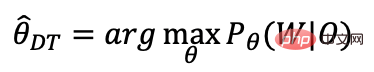

1. 傳統做法
a. 全部訓練語料對應的alignment和解碼lattice;
b . 訓練的時候每個minibatch由預先生成的alignment和lattice 分別計算分子和分母梯度並更新模型;
2. 我們做法
# a. 訓練的時候每個minibatch直接在GPU上計算分子和分母梯度並更新模型;
- 和kaldi基於phone的lattice free mmi區分性訓練差異
## 1. 直接端對字及英文BPE建模,拋棄phone hmm狀態轉移結構; 2. 建模粒度大,訓練輸入沒有近似截斷,context 為整個句子;
下表是在15000小時資料上,CTC訓練完成後,用解碼置信度選取3000小時進行區分性訓練的結果,可以看出採用端到端的lattice free mmi區分性訓練結果好於傳統DT訓練,除了精準度上的提升,整個訓練過程都能在tensorflow/pytorch GPU中完成。
|
B站影片測試集
|
| CTC baseline
|
#6.96
|
# #傳統DT |
6.63 |
E2E LFMMI DT |
##6.13
|
##相對混合系統,端對端系統解碼結果時間戳都不是很準,AED 訓練沒有隨時間單調的對其,CTC 訓練的模型相比AED 時間戳準確很多,但也存在尖峰問題,每個字的持續時長不準;
經過端對端區分性訓練後,模型輸出會變得更加平整,解碼結果的時間戳邊界更加準確;
端到端CTC解碼器
在語音辨識技術發展過程中,無論是基於GMM-HMM的第一階段還是基於DNN-HMM混合框架的第二階段,解碼器都是其中非常重要的組成部分。
解碼器的效能直接決定了最終ASR系統的速度及精度,業務的擴展及客製化也大部分依賴靈活高效的解碼器方案。傳統解碼器不管是動態解碼器還是基於WFST的靜態解碼器都非常複雜,不僅依賴大量的理論知識,還需要專業的軟體工程設計,開發一個性能優越的傳統解碼引擎不僅前期需要投入大量的人力開發,而且後製維護成本也很高。
典型的傳統的WFST 解碼器,需要把hmm,triphone context,字典,語言模型編譯成一個統一的網絡,即HCLG,在一個統一的FST網絡搜索空間,這樣可以提升解碼速度,提高精度。
隨著端對端系統技術的成熟,端對端系統建模單元粒度較大,例如一般為中文的字或英文的wordpiece,因為去除了傳統HMM轉移結構,triphone context及發音字典,這使得後面的解碼搜尋空間變的小很多,這樣我們選擇基於beam search 為基礎的簡單高效動態解碼器,下圖是兩種解碼框架,相比傳統的WFST解碼器,端到端動態解碼器有以下優點:
- 佔用資源少,典型的為WFST解碼資源1/5;
- 其耦合度低,方便業務定制,方便和各種語言模型融合解碼,每次修改不需要重新編譯解碼資源;
- 解碼速度快,採用字同步解碼[8],典型的比WFST解碼速度快5倍;
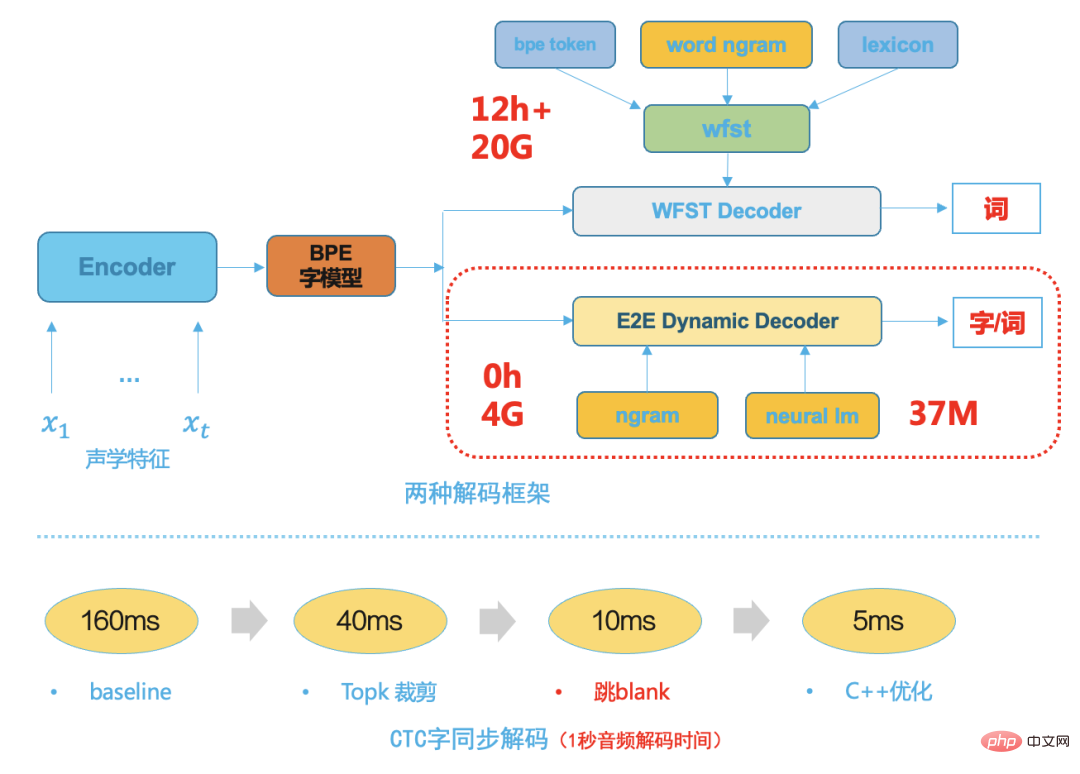
圖八
模型推理部署
在一個合理高效的端對端ASR框架下,計算量最大的部分應該在神經網路模型的推理上,而這塊運算密集的部分可以充分利用GPU的運算能力,我們分別從推理服務,模型結構及模型量化幾部分優化模型推理部署:
- 模型採用F16半精度推理;
- 模型轉FasterTransformer[9],基於nvidia高度優化的transformer;
- 採用triton部署推理模型,自動組batch,充分提升GPU使用效率;
在單塊GPU T4下速度提升30%,吞吐提升2倍,1小時能轉寫3000小時長音訊;
總結
#這篇文章主要介紹了語音辨識技術在B站場景的落地,如何從頭解決訓練資料問題,整體技術方案的選擇,各個子模組的介紹及最佳化,包括模型訓練,解碼器最佳化及服務推理部署等。未來我們將進一步提升相關落地場景使用者體驗,例如採用即時熱詞技術,優化稿件層級相關實體字詞準確率;結合串流ASR相關技術,更有效率的客製化支援遊戲,體育賽事的即時字幕轉寫。
參考資料
[1] A Baevski, H Zhou, et al. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
#[2] A Baevski , W Hsu, et al. data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
[3] Daniel S, Y Zhang, et al. Improved Noisy Student Training for Automatic Speech Recognition
[4] C Lüscher, E Beck, et al. RWTH ASR Systems for LibriSpeech: Hybrid vs Attention -- w/o Data Augmentation
[5] R Prabhavalkar , K Rao, et al , A Comparison of Sequence-to-Sequence Models for Speech Recognition
[6] D Povey, V Peddinti1, et al, Purely sequence-trained neural networks for ASR based on lattice-free MMI
[7] H Xiang, Z Ou, CRF-BASED SINGLE-STAGE ACOUSTIC MODELING WITH CTC TOPOLOGY
[8] Z Chen, W Deng, et al, Phone Synchronous Decoding with CTC Lattice
#[9] https://www.php.cn/link/2ea6241cf767c279cf1e80a790df1885
#本期作者:鄧威
##本期作者:鄧威
#資深演算法工程師######嗶哩嗶哩語音辨識方向負責人#############
以上是語音辨識技術在B站的落地實踐的詳細內容。更多資訊請關注PHP中文網其他相關文章!

