
Jeff Dean等人新作:換個角度檢視語言模型,規模不夠發現不了

- 王林轉載
- 2023-04-14 12:52:031487瀏覽
近年來,語言模型對自然語言處理 (NLP) 產生了革命性影響。眾所周知,擴展語言模型,例如參數等,可以在一系列下游 NLP 任務上帶來更好的效能和樣本效率。在許多情況下,擴展對效能的影響通常可以透過擴展定律來預測,一直以來,絕大多數研究者都在研究可預測現象。
相反,包括Jeff Dean 、 Percy Liang 等在內的16 位研究者合作的論文《 Emergent Abilities of Large Language Models 》,他們討論了大模型不可預測現象,並稱為大型語言模型的突現能力( emergent abilities)。所謂的突現,即有些現像不存在於較小的模型中但存在於較大的模型中,他們認為模型的這種能力是突現的。
突現作為一種想法已經在物理學、生物學和計算機科學等領域討論了很長時間,本論文從突現的一般定義開始,該定義改編自Steinhardt 的研究,並植根於1972 年諾貝爾獎得主、物理學家Philip Anderson 的一篇名為More Is Different 的文章。
本文探討了模型規模的突現,透過訓練計算和模型參數來衡量。具體而言,本文將大型語言模型的突現能力定義為在小規模模型中不存在、但在大規模模型中存在的能力;因此,大型模型不能透過簡單地推斷小規模模型的效能改進來進行預測。該研究調查了在一系列先前工作中觀察到的模型突現能力,並將它們進行分類:小樣本提示和增強提示等設定。
模型的這種突現能力激發了未來的研究,即為什麼會獲得這些能力,以及更大的規模是否會獲得更多的突現能力,並強調了這項研究的重要性。

論文網址:https://arxiv.org/pdf/2206.07682.pdf
#小樣本提示任務
本文首先討論了提示範式中的突現能力。例如在 GPT-3 提示中,給予預訓練語言模型任務提示,模型無需進一步訓練或對參數進行梯度更新即可完成反應。此外,Brown 等人提出了小樣本提示,他們將模型上下文(輸入)中的一些輸入輸出範例作為提示(preamble),然後要求模型執行未見過的推理任務。圖 1 為一個提示範例。
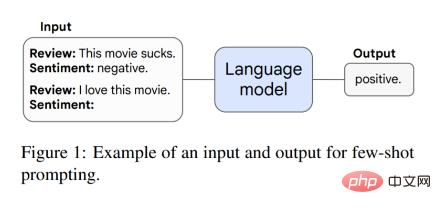

當模型具有隨機效能且具有一定規模時,透過小樣本提示就可以執行任務,這時突現能力就會出現,之後模型表現遠高於隨機表現。下圖展示了 5 個語言模型系列(LaMDA、GPT-3、Gopher、Chinchilla 以及 PaLM )的 8 種突發能力。

BIG-Bench:圖2A-D 描述了四個來自BIG-Bench 的突現小樣本提示任務, BIG-Bench 是一個由200 多個語言模型評估基準的套件。圖 2A 顯示了一個算術基準,它測試了 3 位數字的加減法,以及 2 位數字的乘法。表 1 給出了 BIG-Bench 更多突現能力。

增強提示策略
目前來看,儘管小樣本提示是與大型語言模型互動的最常見方式,但最近的工作已經提出了其他幾種提示和微調策略,以進一步增強語言模型的能力。如果一項技術在應用到足夠大的模型之前沒有顯示出改進或有害的,本文也認為該技術也是一種突現能力。
多步驟推理(Multi-step reasoning):對於語言模型和NLP 模型來說,推理任務,尤其是那些涉及多步驟推理的任務一直是一個很大的挑戰。最近有一種名為思維鏈(chain-of-thought)提示策略,透過引導語言模型在給出最終答案之前產生一系列中間步驟,使它們能夠解決這類問題。如圖 3A 所示,當擴展到 1023 次訓練 FLOP(~ 100B 參數)時,思維鏈提示只超過了沒有中間步驟的標準提示。
指令( Instruction following ):如圖3B 所示,Wei 等人發現,當訓練FLOP 為7 · 10^21 (8B 參數)或更小時,指令微調(instruction -finetuning)技術會損害模型效能,在將訓練FLOP 擴展到10^23 (~100B 參數)時才能提高效能。
程式執行( Program execution ):如圖3C 所示,在8 位元加法的域內評估中,使用暫存器僅有助於∼9 · 10^19 個訓練FLOP(40M 參數)或更大的模型。圖 3D 顯示這些模型也可以泛化到域外 9 位元加法,它出現在 ∼1.3 · 10^20 個訓練 FLOPs(100M 參數)。

本文討論了語言模型的突現能力,到目前為止,僅在一定的計算規模上才能觀察到有意義的性能。模型的這種突現能力可以跨越各種語言模型、任務類型和實驗場景。這種突現的存在意味著額外的規模擴展可以進一步擴大語言模型的能力範圍。這種能力是最近發現的語言模型擴展的結果,關於它們是如何出現的,以及更多的擴展是否會帶來更多的突現能力,可能是NLP領域未來重要的研究方向。
更多內容,請參考原文。
以上是Jeff Dean等人新作:換個角度檢視語言模型,規模不夠發現不了的詳細內容。更多資訊請關注PHP中文網其他相關文章!