



機器學習可以用來解決廣泛的問題。但是有很多多不同的模型可以選擇,要知道哪一個適合是一件非常麻煩的事情。本文的總結將幫助你選擇最適合需求的機器學習模型。

1、確定想要解決的問題
第一步是確定想要解決的問題:要解決的是一個迴歸、分類或聚類別問題?這可以縮小選擇範圍,並決定選擇哪種類型的模型。
你想解決什麼類型的問題?
分類問題:邏輯迴歸、決策樹分類器、隨機森林分類器、支援向量機(SVM)、樸素貝葉斯分類器或神經網路。
聚類問題: k-means聚類、層次聚類或DBSCAN。
2、考慮資料集的大小和性質
a)資料集的大小
如果你有一個小的資料集,就要選擇一個不那麼複雜的模型,例如線性迴歸。對於更大的資料集,更複雜的模型,如隨機森林或深度學習可能是合適的。
資料集的大小怎麼判斷:
- 大型資料集(數千到數百萬行):梯度提升、神經網路或深度學習模型。
- 小資料集(小於1000行):邏輯迴歸、決策樹或樸素貝葉斯。
b)資料標記
資料有預先決定的結果,而未標記資料則沒有。如果是標記數據,那麼一般都是使用監督學習演算法,如邏輯迴歸或決策樹。而未標記的數據需要無監督學習演算法,如k-means或主成分分析(PCA)。
c)特性的性質
如果你的特徵是分類類型的,你可能需要使用決策樹或樸素貝葉斯。對於數值特徵,線性迴歸或支援向量機(SVM)可能更合適。
- 分類特徵:決策樹,隨機森林,樸素貝葉斯。
- 數值特徵:線性迴歸,邏輯迴歸,支援向量機,神經網絡, k-means聚類。
- 混合特徵:決策樹,隨機森林,支援向量機,神經網路。
d)順序資料
如果處理的是順序數據,例如時間序列或自然語言,則可能需要使用循環神經網路(rnn)或長短期記憶(LSTM) ,transformer等
e) 缺失值
缺失值很多可以使用:決策樹,隨機森林,k-means聚類。缺失值不對的話可以考慮線性迴歸,邏輯迴歸,支援向量機,神經網路。
3、解釋性和準確性哪個更重要
有些機器學習模型比其他模型更容易解釋。如果需要解釋模型的結果,可以選擇決策樹或邏輯迴歸等模型。如果準確性更關鍵,那麼更複雜的模型,如隨機森林或深度學習可能更適合。
4、不平衡的類別
如果你正在處理不平衡類,你可能想要使用隨機森林、支援向量機或神經網路等模型來解決這個問題。
處理資料中缺少的值
如果您的資料集中有缺失值,您可能需要考慮可以處理缺失值的imputation技術或模型,例如K-nearest neighbors (KNN)或決策樹。
5、資料的複雜性
如果變數之間可能存在非線性關係,則需要使用更複雜的模型,如神經網路或支援向量機。
- 低複雜度:線性迴歸,邏輯迴歸。
- 中等複雜度:決策樹、隨機森林、樸素貝葉斯。
- 複雜度高:神經網絡,支援向量機。
6、平衡速度和準確度
如果要考慮速度和準確性之間的權衡,更複雜的模型可能會更慢,但它們也可能提供更高的精度。
- 速度更重要:決策樹、樸素貝葉斯、邏輯迴歸、k-均值聚類。
- 精度更重要:神經網絡,隨機森林,支援向量機。
7、高維度資料和雜訊
如果要處理高維度資料或有雜訊的數據,可能需要使用降維技術(如PCA)或可以處理雜訊的模型(如KNN或決策樹)。
- 低雜訊:線性迴歸,邏輯迴歸。
- 適度雜訊:決策樹,隨機森林,k-平均值聚類。
- 高雜訊:神經網絡,支援向量機。
8、即時預測
如果需要即時預測,則需要選擇決策樹或支援向量機這樣的模型。
9、處理離群值
如果資料有異常值很多,可以選擇像svm或隨機森林這樣的健壯模型。
- 對離群值敏感的模型:線性迴歸、邏輯迴歸。
- 穩健性高的模型:決策樹,隨機森林,支援向量機。
10、部署難度
模型的最終目標就是為了上線部署,所以對於部署難度是最後考慮的因素:
一些簡單的模型,如線性迴歸、邏輯迴歸、決策樹等,可以相對容易地部署在生產環境中,因為它們具有較小的模型大小、低複雜度和低計算開銷。在大規模、高維度、非線性等複雜資料集上,這些模型的效能可能會受到限制,需要更高階的模型,如神經網路、支援向量機等。例如,在影像和語音辨識等領域中,資料集可能需要進行大量的處理和預處理,這會增加模型的部署難度。
總結
選擇正確的機器學習模型可能是一項具有挑戰性的任務,需要根據具體問題、資料、速度可解釋性,部署等都需要做出權衡,並根據需求選擇最合適的演算法。透過遵循這些指導原則,您可以確保您的機器學習模型非常適合您的特定用例,並可以為您提供所需的見解和預測。
以上是選擇優秀機器學習模型的十步驟指南的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 使用Python的Google表自動化|分析VidhyaApr 13, 2025 am 10:01 AM
使用Python的Google表自動化|分析VidhyaApr 13, 2025 am 10:01 AMGoogle表是Excel的最受歡迎和廣泛使用的替代方案之一,它提供了具有實時編輯,版本控制和與Google Suite無縫集成等功能的協作環境,允許U
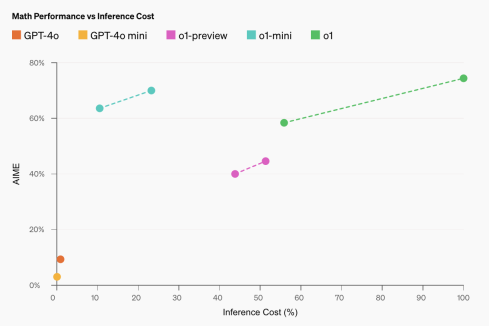 O1-Mini:一種改變遊戲規則的STEM和推理模型Apr 13, 2025 am 09:55 AM
O1-Mini:一種改變遊戲規則的STEM和推理模型Apr 13, 2025 am 09:55 AMOpenAI引入了O1-Mini,這是一種具有成本效益的推理模型,重點是STEM受試者。該模型在數學和編碼中表現出令人印象深刻的性能,與其前身Openai O1非常相似
 用結構化輸出和功能調用增強LLMApr 13, 2025 am 09:45 AM
用結構化輸出和功能調用增強LLMApr 13, 2025 am 09:45 AM介紹 假設您正在與知識淵博但有時缺乏具體/知情的回答或他/她/她/她在面對複雜問題時不會流利的回應時互動。我們在這裡做什麼
 關於LLM代理商的15個最常見的問題Apr 13, 2025 am 09:41 AM
關於LLM代理商的15個最常見的問題Apr 13, 2025 am 09:41 AM介紹 大型語言模型(LLM)代理是使用LLM作為中央計算引擎的高級AI系統。他們有能力執行特定的行動,做出決策並與外部工具或
 11 YouTube頻道免費學習生成AI -Analytics VidhyaApr 13, 2025 am 09:38 AM
11 YouTube頻道免費學習生成AI -Analytics VidhyaApr 13, 2025 am 09:38 AM介紹 As Generative AI continues to reshape industries from content creation to automation, learning this technology has become essential for aspiring AI professionals and enthusiasts alike.憑藉其巨大的教育
 LLM代理商的10種申請Apr 13, 2025 am 09:34 AM
LLM代理商的10種申請Apr 13, 2025 am 09:34 AM介紹 大型語言模型或LLM是改變遊戲規則的人,尤其是在使用內容時。從支持摘要,翻譯和一代,諸如GPT-4,Gemini和Llama之類的LLM使它變得簡單
 LLM代理如何重塑工作場所?Apr 13, 2025 am 09:33 AM
LLM代理如何重塑工作場所?Apr 13, 2025 am 09:33 AM介紹 大型語言模型(LLM)代理是提高工作場所業務效率的最新創新。他們自動進行重複的活動,促進協作並在各個部門提供有用的見解。與眾不同
 設置法師AI與PostgresApr 13, 2025 am 09:31 AM
設置法師AI與PostgresApr 13, 2025 am 09:31 AM想像一下自己是一個數據專業人士,負責創建有效的數據管道來簡化流程並生成實時信息。聽起來很具有挑戰性,對嗎?那就是法師AI的來源以確保貸款


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

