



文件解析涉及檢查文件中的資料並提取有用的信息。它可以透過自動化減少了大量的手動工作。一種流行的解析策略是將文件轉換為圖像並使用電腦視覺進行識別。而文件影像分析(Document Image Analysis)是指從文件的影像的像素資料中獲取資訊的技術,在某些情況下,預期結果應該是什麼樣的沒有明確的答案(文字、影像、圖表、數字、表格、公式…)。

OCR (Optical Character Recognition,光學字元辨識)是透過電腦視覺對影像中的文字進行偵測和擷取的過程。它是在第一次世界大戰期間發明的,當時以色列科學家伊曼紐爾·戈德堡(Emanuel Goldberg)發明了一台可以讀取字元並將其轉換為電報代碼的機器。到了現在該領域已經達到了一個非常複雜的水平,混合圖像處理、文字定位、字元分割和字元辨識。基本上是一種針對文字的物件偵測技術。
在本文中我將展示如何使用OCR進行文件解析。我將展示一些有用的Python程式碼,這些程式碼可以很容易地用於其他類似的情況(只需複製、貼上、運行),並提供完整的原始碼下載。
這裡將以一家上市公司的PDF格式的財務報表為例(連結如下)。
https://s2.q4cdn.com/470004039/files/doc_financials/2021/q4/_10-K-2021-(As-Filed).pdf

##偵測並擷取該PDF中的文字、圖形和表格
環境設定
文件解析令人煩惱的部分是,有太多的工具用於不同類型的資料(文字、圖形、表格),但沒有一個能夠完美地工作。以下是一些最受歡迎方法和軟體包:
- 以文本方式處理文件:用PyPDF2提取文本,用Camelot或TabulaPy提取表,用PyMuPDF提取圖形。
- 將文件轉換為圖像(OCR):使用pdf2image進行轉換,使用PyTesseract以及許多其他的庫提取數據,或只使用LayoutParser。
也許你會問:「為什麼不直接處理PDF文件,而要把頁面轉換成圖像呢?」你可以這麼做。這種策略的主要缺點是編碼問題:文件可以採用多種編碼(即UTF-8、ASCII、Unicode),因此轉換為文字可能會導致資料遺失。因此為了避免產生該問題,我將使用OCR,並用pdf2image將頁面轉換為圖像,需要注意的是PDF渲染庫Poppler是必要的。
# with pip pip install python-poppler # with conda conda install -c conda-forge poppler
你可以很容易地讀取檔案:
# READ AS IMAGE
import pdf2imagedoc = pdf2image.convert_from_path("doc_apple.pdf")
len(doc) #<-- check num pages
doc[0] #<-- visualize a page跟我們的截圖一模一樣,如果想將頁面圖像保存在本地,可以使用以下程式碼:
# Save imgs import osfolder = "doc" if folder not in os.listdir(): os.makedirs(folder)p = 1 for page in doc: image_name = "page_"+str(p)+".jpg" page.save(os.path.join(folder, image_name), "JPEG") p = p+1
最後,我們需要設定將要使用的CV引擎。 LayoutParser似乎是第一個基於深度學習的OCR通用包。它使用了兩個著名的模型來完成任務:
Detection: Facebook最先進的目標檢測庫(這裡將使用第二個版本Detectron2)。
pip install layoutparser torchvision && pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"
Tesseract:最著名的OCR系統,由惠普公司在1985年創建,目前由Google開發。
pip install "layoutparser[ocr]"
現在已經準備好開始OCR程式進行資訊偵測和擷取了。
import layoutparser as lp import cv2 import numpy as np import io import pandas as pd import matplotlib.pyplot as plt
偵測
(目標)偵測是在圖片中找到資訊片段,然後用矩形邊框將其包圍的過程。對於文件解析,這些資訊是標題、文字、圖形、表格…
讓我們來看一個複雜的頁面,它包含了一些東西:
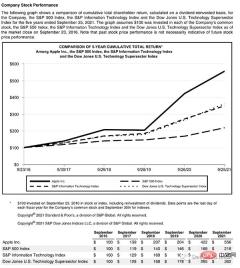
這個頁面以一個標題開始,有一個文字區塊,然後是一個圖表和一個表,因此我們需要一個經過訓練的模型來識別這些物件。幸運的是,Detectron能夠完成這項任務,我們只需從這裡選擇一個模型,並在程式碼中指定它的路徑。
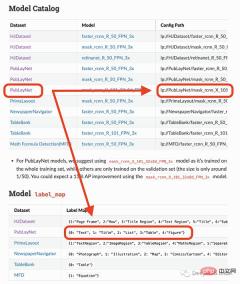
我將要使用的模型只能偵測4個物件(文字、標題、清單、表格、圖形)。因此,如果你需要辨識其他東西(如方程式),你就必須使用其他模型。
## load pre-trained model
model = lp.Detectron2LayoutModel(
"lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config",
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0:"Text", 1:"Title", 2:"List", 3:"Table", 4:"Figure"})
## turn img into array
i = 21
img = np.asarray(doc[i])
## predict
detected = model.detect(img)
## plot
lp.draw_box(img, detected, box_width=5, box_alpha=0.2,
show_element_type=True)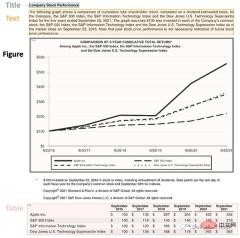
结果包含每个检测到的布局的细节,例如边界框的坐标。根据页面上显示的顺序对输出进行排序是很有用的:
## sort
new_detected = detected.sort(key=lambda x: x.coordinates[1])
## assign ids
detected = lp.Layout([block.set(id=idx) for idx,block in
enumerate(new_detected)])## check
for block in detected:
print("---", str(block.id)+":", block.type, "---")
print(block, end='nn')
完成OCR的下一步是正确提取检测到内容中的有用信息。
提取
我们已经对图像完成了分割,然后就需要使用另外一个模型处理分段的图像,并将提取的输出保存到字典中。
由于有不同类型的输出(文本,标题,图形,表格),所以这里准备了一个函数用来显示结果。
'''
{'0-Title': '...',
'1-Text': '...',
'2-Figure': array([[ [0,0,0], ...]]),
'3-Table': pd.DataFrame,
}
'''
def parse_doc(dic):
for k,v in dic.items():
if "Title" in k:
print('x1b[1;31m'+ v +'x1b[0m')
elif "Figure" in k:
plt.figure(figsize=(10,5))
plt.imshow(v)
plt.show()
else:
print(v)
print(" ")首先看看文字:
# load model
model = lp.TesseractAgent(languages='eng')
dic_predicted = {}
for block in [block for block in detected if block.type in ["Title","Text"]]:
## segmentation
segmented = block.pad(left=15, right=15, top=5,
bottom=5).crop_image(img)
## extraction
extracted = model.detect(segmented)
## save
dic_predicted[str(block.id)+"-"+block.type] =
extracted.replace('n',' ').strip()
# check
parse_doc(dic_predicted)
再看看图形报表
for block in [block for block in detected if block.type == "Figure"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## save dic_predicted[str(block.id)+"-"+block.type] = segmented # check parse_doc(dic_predicted)
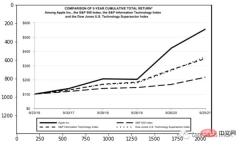
上面两个看着很不错,那是因为这两种类型相对简单,但是表格就要复杂得多。尤其是我们上看看到的的这个,因为它的行和列都是进行了合并后产生的。
for block in [block for block in detected if block.type == "Table"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## extraction extracted = model.detect(segmented) ## save dic_predicted[str(block.id)+"-"+block.type] = pd.read_csv( io.StringIO(extracted) ) # check parse_doc(dic_predicted)

正如我们的预料提取的表格不是很好。好在Python有专门处理表格的包,我们可以直接处理而不将其转换为图像。这里使用TabulaPy 包:
import tabula
tables = tabula.read_pdf("doc_apple.pdf", pages=i+1)
tables[0]
结果要好一些,但是名称仍然错了,但是效果要比直接OCR好的多。
总结
本文是一个简单教程,演示了如何使用OCR进行文档解析。使用Layoutpars软件包进行了整个检测和提取过程。并展示了如何处理PDF文档中的文本,数字和表格。
以上是使用Python和OCR進行文件解析的完整程式碼演示(附程式碼)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Python中的合併列表:選擇正確的方法May 14, 2025 am 12:11 AM
Python中的合併列表:選擇正確的方法May 14, 2025 am 12:11 AMTomergelistsinpython,YouCanusethe操作員,estextMethod,ListComprehension,Oritertools
 如何在Python 3中加入兩個列表?May 14, 2025 am 12:09 AM
如何在Python 3中加入兩個列表?May 14, 2025 am 12:09 AM在Python3中,可以通過多種方法連接兩個列表:1)使用 運算符,適用於小列表,但對大列表效率低;2)使用extend方法,適用於大列表,內存效率高,但會修改原列表;3)使用*運算符,適用於合併多個列表,不修改原列表;4)使用itertools.chain,適用於大數據集,內存效率高。
 Python串聯列表字符串May 14, 2025 am 12:08 AM
Python串聯列表字符串May 14, 2025 am 12:08 AM使用join()方法是Python中從列表連接字符串最有效的方法。 1)使用join()方法高效且易讀。 2)循環使用 運算符對大列表效率低。 3)列表推導式與join()結合適用於需要轉換的場景。 4)reduce()方法適用於其他類型歸約,但對字符串連接效率低。完整句子結束。
 Python執行,那是什麼?May 14, 2025 am 12:06 AM
Python執行,那是什麼?May 14, 2025 am 12:06 AMpythonexecutionistheprocessoftransformingpypythoncodeintoExecutablestructions.1)InternterPreterReadSthecode,ConvertingTingitIntObyTecode,whepythonvirtualmachine(pvm)theglobalinterpreterpreterpreterpreterlock(gil)the thepythonvirtualmachine(pvm)
 Python:關鍵功能是什麼May 14, 2025 am 12:02 AM
Python:關鍵功能是什麼May 14, 2025 am 12:02 AMPython的關鍵特性包括:1.語法簡潔易懂,適合初學者;2.動態類型系統,提高開發速度;3.豐富的標準庫,支持多種任務;4.強大的社區和生態系統,提供廣泛支持;5.解釋性,適合腳本和快速原型開發;6.多範式支持,適用於各種編程風格。
 Python:編譯器還是解釋器?May 13, 2025 am 12:10 AM
Python:編譯器還是解釋器?May 13, 2025 am 12:10 AMPython是解釋型語言,但也包含編譯過程。 1)Python代碼先編譯成字節碼。 2)字節碼由Python虛擬機解釋執行。 3)這種混合機制使Python既靈活又高效,但執行速度不如完全編譯型語言。
 python用於循環與循環時:何時使用哪個?May 13, 2025 am 12:07 AM
python用於循環與循環時:何時使用哪個?May 13, 2025 am 12:07 AMUseeAforloopWheniteratingOveraseQuenceOrforAspecificnumberoftimes; useAwhiLeLoopWhenconTinuingUntilAcIntiment.forloopsareIdealForkNownsences,而WhileLeleLeleLeleLeleLoopSituationSituationsItuationsItuationSuationSituationswithUndEtermentersitations。
 Python循環:最常見的錯誤May 13, 2025 am 12:07 AM
Python循環:最常見的錯誤May 13, 2025 am 12:07 AMpythonloopscanleadtoerrorslikeinfiniteloops,modifyingListsDuringteritation,逐個偏置,零indexingissues,andnestedloopineflinefficiencies


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

