



梯度提升演算法是最常用的整合機器學習技術之一,該模型使用弱決策樹序列來建構強學習器。這也是XGBoost和LightGBM模型的理論基礎,所以在這篇文章中,我們將從頭開始建立一個梯度增強模型並將其視覺化。
梯度提升演算法介紹
梯度提升演算法(Gradient Boosting)是一種集成學習演算法,它透過建立多個弱分類器,然後將它們組合成一個強分類器來提高模型的預測準確率。
梯度提升演算法的原理可以分為以下幾個步驟:
- 初始化模型:一般來說,我們可以使用一個簡單的模型(比如說決策樹)作為初始的分類器。
- 計算損失函數的負梯度:計算出每個樣本點在目前模型下的損失函數的負梯度。這相當於是讓新的分類器去擬合目前模型下的誤差。
- 訓練新的分類器:用這些負梯度作為目標變量,訓練一個新的弱分類器。這個弱分類器可以是任意的分類器,比如說決策樹、線性模型等。
- 更新模型:將新的分類器加入原來的模型中,可以用加權平均或其他方法將它們組合起來。
- 重複迭代:重複上述步驟,直到達到預設的迭代次數或達到預設的準確率。
由於梯度提升演算法是一種串列演算法,所以它的訓練速度可能會比較慢,我們以一個實際的例子來介紹:
假設我們有一個特徵集Xi和值Yi,要計算y的最佳估計值

#我們從y的平均值開始

#每一步我們都想讓F_m(x)更接近y|x。

在每一步中,我們都想要F_m(x)一個更好的y給定x的近似值。
首先,我們定義一個損失函數

然後,我們向損失函數相對於學習者Fm下降最快的方向前進:
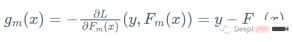
因為我們不能為每個x計算y,所以不知道這個梯度的確切值,但是對於訓練資料中的每一個x_i,梯度完全等於步驟m的殘差:r_i!
所以我們可以用弱迴歸樹h_m來近似梯度函數g_m,對殘差進行訓練:
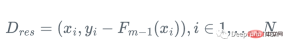
然後,我們更新學習器
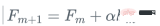
這就是梯度提升,我們不是使用損失函數相對於當前學習器的真實梯度g_m來更新目前學習器F_{m},而是使用弱回歸樹h_m來更新它。

也就是重複下面的步驟
1、計算殘差:

2、將迴歸樹h_m擬合到訓練樣本及其殘差(x_i, r_i)上
3、用步長alpha更新模型

import numpy as np import sklearn.datasets as ds import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl from sklearn import tree from itertools import product,islice import seaborn as snsmoonDS = ds.make_moons(200, noise = 0.15, random_state=16) moon = moonDS[0] color = -1*(moonDS[1]*2-1) df =pd.DataFrame(moon, columns = ['x','y']) df['z'] = color df['f0'] =df.y.mean() df['r0'] = df['z'] - df['f0'] df.head(10)讓我們視覺化資料:
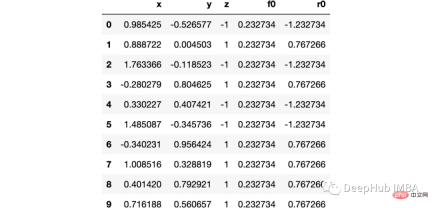
下图可以看到,该数据集是可以明显的区分出分类的边界的,但是因为他是非线性的,所以使用线性算法进行分类时会遇到很大的困难。

那么我们先编写一个简单的梯度增强模型:
def makeiteration(i:int):
"""Takes the dataframe ith f_i and r_i and approximated r_i from the features, then computes f_i+1 and r_i+1"""
clf = tree.DecisionTreeRegressor(max_depth=1)
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)
eta = 0.9
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']
df[f'r{i}'] = df['z'] - df[f'f{i}']
rmse = (df[f'r{i}']**2).sum()
clfs.append(clf)
rmses.append(rmse)上面代码执行3个简单步骤:
将决策树与残差进行拟合:
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)然后,我们将这个近似的梯度与之前的学习器相加:
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']最后重新计算残差:
df[f'r{i}'] = df['z'] - df[f'f{i}']步骤就是这样简单,下面我们来一步一步执行这个过程。
第1次决策

Tree Split for 0 and level 1.563690960407257

第2次决策

Tree Split for 1 and level 0.5143677890300751

第3次决策

Tree Split for 0 and level -0.6523728966712952

第4次决策

Tree Split for 0 and level 0.3370491564273834

第5次决策

Tree Split for 0 and level 0.3370491564273834

第6次决策

Tree Split for 1 and level 0.022058885544538498

第7次决策

Tree Split for 0 and level -0.3030575215816498

第8次决策

Tree Split for 0 and level 0.6119407713413239

第9次决策

可以看到通过9次的计算,基本上已经把上面的分类进行了区分

我们这里的学习器都是非常简单的决策树,只沿着一个特征分裂!但整体模型在每次决策后边的越来越复杂,并且整体误差逐渐减小。
plt.plot(rmses)

这也就是上图中我们看到的能够正确区分出了大部分的分类
如果你感兴趣可以使用下面代码自行实验:
https://www.php.cn/link/bfc89c3ee67d881255f8b097c4ed2d67
以上是梯度提升演算法決策過程的逐步視覺化的詳細內容。更多資訊請關注PHP中文網其他相關文章!

![[免費]什麼是Openai O3-Mini(Chatgpt O3Mini High)?解釋主要功能和用法!](https://img.php.cn/upload/article/001/242/473/174704017489264.jpg?x-oss-process=image/resize,p_40) [免費]什麼是Openai O3-Mini(Chatgpt O3Mini High)?解釋主要功能和用法!May 12, 2025 pm 04:56 PM
[免費]什麼是Openai O3-Mini(Chatgpt O3Mini High)?解釋主要功能和用法!May 12, 2025 pm 04:56 PMOpenai O3-Mini:一種經濟高效的高性能推斷模型 近年來,OpenAI一直在發布包括GPT系列在內的創新模型,尤其是其大規模語言模型(LLM)。 Openai發布了最新且具有成本效益的模型,Openai O3-Mini,專門從事推斷。這種快速有力的模型在科學,數學和編碼等領域提供了高性能,從而大大擴展了小規模模型的可能性。 在本文中,我們將介紹Openai O3-Mini的
 chatgpt中的ng詞是什麼?列表的詳盡解釋和禁止的單詞May 12, 2025 pm 04:54 PM
chatgpt中的ng詞是什麼?列表的詳盡解釋和禁止的單詞May 12, 2025 pm 04:54 PMChatGPT的禁忌詞語:全面解析及其影響 隨著AI技術的飛速發展,基於自然語言處理的聊天機器人ChatGPT備受矚目。然而,ChatGPT的使用中存在需要注意的“禁忌詞語”,這些詞語會限制其生成內容。 本文將深入探討哪些詞語屬於禁忌詞語,為何設置禁忌詞語,以及這些詞語對ChatGPT使用有何影響。此外,我們將探討如何規避禁忌詞語,更有效地利用ChatGPT。希望本文能幫助您在充分發揮ChatGPT潛能的同時,有效管理倫理和法律風險。 OpenAI發布的最新AI代理“OpenAI Deep Re
 易於理解的解釋如何登錄到chatgpt以及如何用日語開始!May 12, 2025 pm 04:45 PM
易於理解的解釋如何登錄到chatgpt以及如何用日語開始!May 12, 2025 pm 04:45 PMCHATGPT:從註冊到登錄和使用應用程序的詳盡指南! 近年來,包括Chatgpt在內的AI對我們的生活產生了重大影響。 Chatgpt將注意力吸引為允許自然對話的AI,但是您需要註冊一個帳戶並登錄以使用它。在本文中,我們將以一種易於理解的方式解釋初學者,如何註冊和登錄到chatgpt,如何啟動應用程序版本以及故障排除。如果您正在考慮開始使用chatgpt或在註冊困難時,請參閱此信息。 目錄 登錄到chatgpt
![[Openai]什麼是O4-Mini?解釋主要功能,用法和費用結構](https://img.php.cn/upload/article/001/242/473/174703939398912.jpg?x-oss-process=image/resize,p_40) [Openai]什麼是O4-Mini?解釋主要功能,用法和費用結構May 12, 2025 pm 04:43 PM
[Openai]什麼是O4-Mini?解釋主要功能,用法和費用結構May 12, 2025 pm 04:43 PM最新的小型AI型號O4-Mini:高速,低價,高性能! Openai發布了新的小型AI型號O4-Mini。與旗艦型號“ O3”不同,其吸引力是其高速和低價。在本文中,我們將詳細解釋O4-Mini的特徵,其與O3的差異,其使用情況,安全性以及如何使用它。 目錄 O4-Mini的概述 關鍵功能 大約O4米尼高 如何使用和費用結構 API使用和費用 與Azure和GitHub Copilot一起使用
 免費版本和付費版本Chatgpt之間的區別!我們解釋了這些功能和使用的示例中的每一個!May 12, 2025 pm 04:41 PM
免費版本和付費版本Chatgpt之間的區別!我們解釋了這些功能和使用的示例中的每一個!May 12, 2025 pm 04:41 PMChatGPT:免費版與付費版(ChatGPT Plus)深度對比,助您選出最佳方案! 許多人對ChatGPT強大的對話能力充滿興趣,並開始探索其在日常生活和商業中的應用。然而,即使被ChatGPT吸引,很多人仍然對免費版和付費版(ChatGPT Plus)的區別缺乏充分的了解。 本文將對ChatGPT的免費版和付費版(ChatGPT Plus)進行特性比較,詳細解釋各自的優勢以及根據用途進行選擇的最佳方法。付費版提供諸多額外福利,例如更快的響應速度、高峰時段的優先訪問權以及新功能的搶先體驗。
 我們解釋了ChatGPT4和GPT4-O的費用,付款方式,以及如何免費使用它!May 12, 2025 pm 04:40 PM
我們解釋了ChatGPT4和GPT4-O的費用,付款方式,以及如何免費使用它!May 12, 2025 pm 04:40 PM對Chatgpt-4的定價計劃以及如何免費使用它的詳盡說明!選擇最佳計劃並使用它 我們將以易於理解的方式解釋OpenAI的ChatGpt-4(以及GPT-4O/GPT-4 OMNI)的定價結構。我們將全面概述免費計劃和付費計劃之間的差異,每月20美元計劃的功能以及如何免費使用ChatGpt-4。 從選擇定價計劃到免費使用它,到下載官方應用程序,我們提供了有關如何有效利用ChatGpt-4的信息。 Chatgpt-4O(OMNI)價格 chatgpt-
 在公司中使用ChatGPT的示例!我們還解釋了要注意的好處和點May 12, 2025 pm 04:37 PM
在公司中使用ChatGPT的示例!我們還解釋了要注意的好處和點May 12, 2025 pm 04:37 PMCHATGPT:公司使用和實施指南的示例 近年來,AI技術的發展非常出色,Chatgpt在聊天機器人和自然語言處理領域引起了很多關注。本文介紹了在公司中使用Chatgpt的具體示例,並解釋了實施,風險和有效開發準則的好處。 通過在包括製造,食品,金融,零售和教育在內的各種行業中的例子中探索Chatgpt的可能性。 有關Openai最新AI代理“ OpenAi Deep Research”的更多信息,請單擊此處。
 什麼是chatgpt 4.5(GPT-4.5)?我們解釋瞭如何使用它,費用和與4O的比較!呢May 12, 2025 pm 04:35 PM
什麼是chatgpt 4.5(GPT-4.5)?我們解釋瞭如何使用它,費用和與4O的比較!呢May 12, 2025 pm 04:35 PMOpenAI發布的最新AI模型ChatGPT 4.5 (GPT-4.5) 性能全面提升,具備更自然流暢的對話能力、更強大的推理能力和更高的情商(EQ)。本文將深入探討GPT-4.5,全面解析其特性。我們將涵蓋其主要特點、與GPT-4和GPT-4o的對比、具體功能、定價策略、安全措施以及各種應用案例。 目錄 ChatGPT 4.5 (GPT-4.5) 簡介 ChatGPT 4.5 (GPT-4.5) 性能詳解 無監督學習的擴展 更自然的對話 更高的EQ(同理心) 事實性提升(減少幻覺) 知識庫 推


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

禪工作室 13.0.1
強大的PHP整合開發環境

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

記事本++7.3.1
好用且免費的程式碼編輯器

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

Atom編輯器mac版下載
最受歡迎的的開源編輯器

