



基於Meta模型打造的輕量版ChatGPT,這就來啦?
Meta宣布推出LLaMA才三天,業界就出現了把它打造成ChatGPT的開源訓練方法,號稱比ChatGPT訓練速度最高快15倍。
LLaMA是Meta推出的超快超小型GPT-3,參數量只有後者的10%,只需要單張GPU就能運作。
把它變成ChatGPT的方法叫做ChatLLaMA,基於RLHF(基於人類回饋的強化學習)進行訓練,在網路上很快就掀起了一陣熱度。

所以,Meta的開源版ChatGPT真的要來了?
先等等,事情倒也沒那麼簡單。
把LLaMA訓練成ChatGPT的「開源方法」
點進ChatLLaMA專案首頁來看,會發現它實際上整合了四個部分-
DeepSpeed、 RLHF方法、LLaMA和基於LangChain agent產生的資料集。
其中,DeepSpeed是一個開源深度學習訓練最佳化庫,包含名叫Zero的現存最佳化技術,用於提升大模型訓練能力,具體指幫模型提升訓練速度、降低成本、提升模型可用性等。
RLHF則會採用獎勵模型來微調預訓練模型。獎勵模型即先用多個模型產生問題問答,再依靠人工對問答進行排序,讓它學會打分;隨後,基於獎勵學習給模型生成的回答進行打分,透過強化學習的方式增強模型能力。
LangChain是一個大語言模型應用程式開發庫,希望將各種大語言模型整合起來,結合其他知識來源或運算能力來創建一個實用的應用程式。 LangChain agent則會像思維鏈一樣放出GPT-3思考的整個過程,將操作記錄下來。
這時候你會發現,最關鍵的依舊是LLaMA的模型權重。它從哪裡來?
嘿嘿,自己去找Meta申請吧,ChatLLaMA並不提供。 (雖然Meta聲稱開源LLaMA,但依舊需要申請)

所以本質上來說,ChatLLaMA並不是一個開源ChatGPT項目,而只是一種基於LLaMA的訓練方法,其庫內整合的幾個專案原本也都是開源的。
實際上,ChatLLaMA也並非由Meta打造,而是來自一個叫做Nebuly AI的新創AI企業。
Nebuly AI做了一個叫做Nebullvm的開源函式庫,裡面整合了一系列即插即用的最佳化模組,用來提升AI系統效能。
例如這是Nebullvm目前包含的一些模組,包括基於DeepMind開源的AlphaTensor演算法打造的OpenAlphaTensor、自動感知硬體並對其進行加速的最佳化模組…

#ChatLLaMA也在這一系列模組中,但要注意的是它的開源license也是不可商用的。
所以「國產自研ChatGPT」想要直接拿去用,可能還沒那麼簡單(doge)。
看完這個專案後,有網友表示,要是有人真搞到LLaMA的模型權重(程式碼)就好了…

但也有網友指出,「比ChatGPT訓練方法快15倍」這種說法是純粹的誤導:
所謂的快15倍只是因為LLaMA模型本身很小,甚至能在單一GPU上運行,但應該不是因為這個專案所做的任何事情吧?

這位網友也推薦了一個比庫中效果更好的RLHF訓練方法,名叫trlx,訓練速度要比通常的RLHF方法快上3~4倍:

你拿到LLaMA的程式碼了嗎?覺得這個訓練方法如何?
ChatLLaMA網址:https://www.php.cn/link/fed537780f3f29cc5d5f313bbda423c4
參考連結:https://www.php.cn/link/fe27f92b1e3f4997567807f38d567a35
##以上是輕量版ChatGPT訓練方法開源!僅用3天圍繞LLaMA打造,號稱訓練速度比OpenAI快15倍的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 RF-DER:橋接速度和對象檢測的準確性Apr 24, 2025 am 10:40 AM
RF-DER:橋接速度和對象檢測的準確性Apr 24, 2025 am 10:40 AM歡迎讀者,簡歷課程重新參加了會議!迄今為止,我們以前已經在我以前的博客中研究了30種不同的計算機視覺模型,每個博客都從快速檢測技巧中帶來了自己的獨特優勢
 Agent SDK vs Crewai vs Langchain:哪個何時使用?Apr 24, 2025 am 10:39 AM
Agent SDK vs Crewai vs Langchain:哪個何時使用?Apr 24, 2025 am 10:39 AM本文比較了建立AI代理的三個流行框架:OpenAI的Agent SDK,Langchain和Crewai。 每個都為自動化任務和增強決策提供了獨特的優勢。 這篇文章指導您選擇最佳幀
 使用Pydantic構建結構化研究自動化系統Apr 24, 2025 am 10:32 AM
使用Pydantic構建結構化研究自動化系統Apr 24, 2025 am 10:32 AM在學術研究的動態領域,有效的信息收集,綜合和演示至關重要。 文獻綜述的手動過程是耗時的,阻礙了更深入的分析。 多代理研究助理系統BUI
 10 GPT-4O圖像生成會提示今天嘗試!Apr 24, 2025 am 10:26 AM
10 GPT-4O圖像生成會提示今天嘗試!Apr 24, 2025 am 10:26 AMAI世界中發生了絕對野生的事情。 Openai的本地形像生成現在很瘋狂。我們正在談論令人jaw目結舌的視覺效果,可怕的細節和拋光的輸出
 用帆板編碼的氛圍指南Apr 24, 2025 am 10:25 AM
用帆板編碼的氛圍指南Apr 24, 2025 am 10:25 AM毫不費力地將您的編碼願景帶入Codeium's Windsurf,這是您的AI驅動的編碼伴侶。 Windsurf簡化了整個軟件開發生命週期,從編碼和調試到優化,將過程轉換為INTU
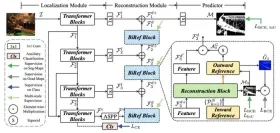 使用RMGB v2.0探索圖像背景刪除Apr 24, 2025 am 10:20 AM
使用RMGB v2.0探索圖像背景刪除Apr 24, 2025 am 10:20 AMBraiai的RMGB v2.0:強大的開源背景拆卸模型 圖像分割模型正在徹底改變各個領域,而背景刪除是進步的關鍵領域。 Braiai的RMGB v2.0是最先進的開源M
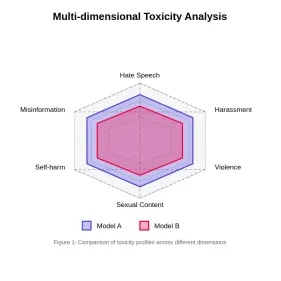 評估大語模型中的毒性Apr 24, 2025 am 10:14 AM
評估大語模型中的毒性Apr 24, 2025 am 10:14 AM本文探討了大語言模型(LLM)中的毒性至關重要問題以及用於評估和減輕它的方法。 LLM,為從聊天機器人到內容生成的各種應用程序提供動力,需要強大的評估指標,機智
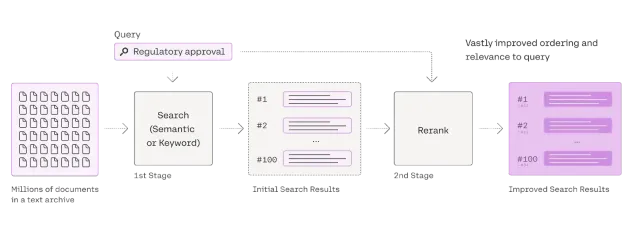 Rag Reranker的綜合指南Apr 24, 2025 am 10:10 AM
Rag Reranker的綜合指南Apr 24, 2025 am 10:10 AM檢索增強發電(RAG)系統正在轉換信息訪問,但其有效性取決於檢索到的數據的質量。 這是重讀者變得至關重要的地方 - 充當搜索結果的質量過濾器,以確保僅確保


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SublimeText3漢化版
中文版,非常好用

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript開發工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

