




隨著微信的普及,越來越多的人開始使用微信。微信漸漸從一款單純的社群軟體轉變成了一種生活方式,人們的日常溝通需要微信,工作交流也需要微信。微信裡的每一個好友,都代表著人們在社會裡扮演的不同角色。

今天這篇文章會基於Python對微信好友進行資料分析,這裡選擇的維度主要有:性別、頭像、簽名、位置,主要採用圖表和詞雲兩種形式來呈現結果,其中,對文本類資訊會採用詞頻分析和情感分析兩種方法。常言:工欲善其事,必先利其器也。在正式開始這篇文章前,簡單介紹下本文中使用到的第三方模組:
itchat:微信網頁版介面封裝Python版本,在本文中用以取得微信好友資訊。
jieba:結巴分詞的 Python 版本,在本文中用以對文字訊息進行分詞處理。
matplotlib:Python 中圖表繪製模組,在本文中用以繪製柱形圖和餅圖
snownlp:一個Python 中的中文分詞模組,在本文中用以對文本訊息進行情感判斷。
PIL:Python 中的影像處理模組,在本文中使用以對圖片進行處理。
numpy:Python中 的數值計算模組,在本文中搭配 wordcloud 模組使用。
wordcloud:Python 中的詞雲模組,在本文中用以繪製詞雲圖片。
TencentYoutuyun:騰訊優圖提供的 Python 版本 SDK ,在本文中用以識別人臉及提取圖片標籤資訊。
以上模組皆可透過 pip 安裝,關於各個模組使用的詳細說明,請自行查閱各自文件。
1. 資料分析
分析微信好友資料的前提是獲得好友訊息,透過使用itchat 這個模組,這一切會變得非常簡單,我們透過下面兩行程式碼就可以實現:
itchat.auto_login(hotReload = True) friends = itchat.get_friends(update = True)
同平時登入網頁版微信一樣,我們使用手機掃描二維碼就可以登錄,這裡回傳的friends物件是一個集合,第一個元素是目前使用者。所以,在下面的數據分析流程中,我們總是取friends[1:]作為原始輸入數據,集合中的每一個元素都是一個字典結構,以我本人為例,可以注意到這裡有Sex、City、 Province、HeadImgUrl、Signature這四個字段,我們下面的分析就從這四個字段入手:

def analyseSex(firends): sexs = list(map(lambda x:x['Sex'],friends[1:])) counts = list(map(lambda x:x[1],Counter(sexs).items())) labels = ['Unknow','Male','Female'] colors = ['red','yellowgreen','lightskyblue'] plt.figure(figsize=(8,5), dpi=80) plt.axes(aspect=1) plt.pie(counts, #性别统计结果 labels=labels, #性别展示标签 colors=colors, #饼图区域配色 labeldistance = 1.1, #标签距离圆点距离 autopct = '%3.1f%%', #饼图区域文本格式 shadow = False, #饼图是否显示阴影 startangle = 90, #饼图起始角度 pctdistance = 0.6 #饼图区域文本距离圆点距离 ) plt.legend(loc='upper right',) plt.title(u'%s的微信好友性别组成' % friends[0]['NickName']) plt.show()這裡簡單解釋下這段程式碼,微信中性別欄位的取值有Unkonw、Male和Female三種,其對應的數值分別為0、1、2。透過Collection模組中的Counter()對這三種不同的取值進行統計,其items()方法傳回的是一個元組的集合。 該元組的第一維元素表示鍵,即0、1、2,該元組的第二維元素表示數目,且該元組的集合是排序過的,即其鍵按照0、1、2 的順序排列,所以透過map()方法就可以得到這三種不同取值的數目,我們將其傳遞給matplotlib繪製即可,這三種不同取值各自所佔的百分比由matplotlib計算得出。下圖是matplotlib繪製的好友性別分佈圖:

def analyseHeadImage(frineds):
# Init Path
basePath = os.path.abspath('.')
baseFolder = basePath + '\HeadImages\'
if(os.path.exists(baseFolder) == False):
os.makedirs(baseFolder)
# Analyse Images
faceApi = FaceAPI()
use_face = 0
not_use_face = 0
image_tags = ''
for index in range(1,len(friends)):
friend = friends[index]
# Save HeadImages
imgFile = baseFolder + '\Image%s.jpg' % str(index)
imgData = itchat.get_head_img(userName = friend['UserName'])
if(os.path.exists(imgFile) == False):
with open(imgFile,'wb') as file:
file.write(imgData)
# Detect Faces
time.sleep(1)
result = faceApi.detectFace(imgFile)
if result == True:
use_face += 1
else:
not_use_face += 1
# Extract Tags
result = faceApi.extractTags(imgFile)
image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))
labels = [u'使用人脸头像',u'不使用人脸头像']
counts = [use_face,not_use_face]
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友使用人脸头像情况' % friends[0]['NickName'])
plt.show()
image_tags = image_tags.encode('iso8859-1').decode('utf-8')
back_coloring = np.array(Image.open('face.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=800,
height=480,
margin=15
)
wordcloud.generate(image_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
这里我们会在当前目录新建一个HeadImages目录,用于存储所有好友的头像,然后我们这里会用到一个名为FaceApi类,这个类由腾讯优图的SDK封装而来,这里分别调用了人脸检测和图像标签识别两个API接口,前者会统计”使用人脸头像”和”不使用人脸头像”的好友各自的数目,后者会累加每个头像中提取出来的标签。其分析结果如下图所示:
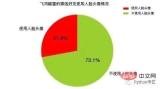
可以注意到,在所有微信好友中,约有接近1/4的微信好友使用了人脸头像, 而有接近3/4的微信好友没有人脸头像,这说明在所有微信好友中对”颜值 “有自信的人,仅仅占到好友总数的25%,或者说75%的微信好友行事风格偏低调为主,不喜欢用人脸头像做微信头像。
其次,考虑到腾讯优图并不能真正的识别”人脸”,我们这里对好友头像中的标签再次进行提取,来帮助我们了解微信好友的头像中有哪些关键词,其分析结果如图所示:

通过词云,我们可以发现:在微信好友中的签名词云中,出现频率相对较高的关键字有:女孩、树木、房屋、文本、截图、卡通、合影、天空、大海。这说明在我的微信好友中,好友选择的微信头像主要有日常、旅游、风景、截图四个来源。
好友选择的微信头像中风格以卡通为主,好友选择的微信头像中常见的要素有天空、大海、房屋、树木。通过观察所有好友头像,我发现在我的微信好友中,使用个人照片作为微信头像的有15人,使用网络图片作为微信头像的有53人,使用动漫图片作为微信头像的有25人,使用合照图片作为微信头像的有3人,使用孩童照片作为微信头像的有5人,使用风景图片作为微信头像的有13人,使用女孩照片作为微信头像的有18人,基本符合图像标签提取的分析结果。
4. 好友签名
分析好友签名,签名是好友信息中最为丰富的文本信息,按照人类惯用的”贴标签”的方法论,签名可以分析出某一个人在某一段时间里状态,就像人开心了会笑、哀伤了会哭,哭和笑两种标签,分别表明了人开心和哀伤的状态。
这里我们对签名做两种处理,第一种是使用结巴分词进行分词后生成词云,目的是了解好友签名中的关键字有哪些,哪一个关键字出现的频率相对较高;第二种是使用SnowNLP分析好友签名中的感情倾向,即好友签名整体上是表现为正面的、负面的还是中立的,各自的比重是多少。这里提取Signature字段即可,其核心代码如下:
def analyseSignature(friends):
signatures = ''
emotions = []
pattern = re.compile("1fd.+")
for friend in friends:
signature = friend['Signature']
if(signature != None):
signature = signature.strip().replace('span', '').replace('class', '').replace('emoji', '')
signature = re.sub(r'1f(d.+)','',signature)
if(len(signature)>0):
nlp = SnowNLP(signature)
emotions.append(nlp.sentiments)
signatures += ' '.join(jieba.analyse.extract_tags(signature,5))
with open('signatures.txt','wt',encoding='utf-8') as file:
file.write(signatures)
# Sinature WordCloud
back_coloring = np.array(Image.open('flower.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=960,
height=720,
margin=15
)
wordcloud.generate(signatures)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('signatures.jpg')
# Signature Emotional Judgment
count_good = len(list(filter(lambda x:x>0.66,emotions)))
count_normal = len(list(filter(lambda x:x>=0.33 and x<=0.66,emotions)))
count_bad = len(list(filter(lambda x:x<0.33,emotions)))
labels = [u'负面消极',u'中性',u'正面积极']
values = (count_bad,count_normal,count_good)
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel(u'情感判断')
plt.ylabel(u'频数')
plt.xticks(range(3),labels)
plt.legend(loc='upper right',)
plt.bar(range(3), values, color = 'rgb')
plt.title(u'%s的微信好友签名信息情感分析' % friends[0]['NickName'])
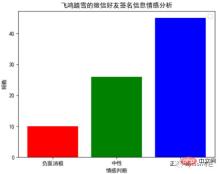
plt.show()通过词云,我们可以发现:在微信好友的签名信息中,出现频率相对较高的关键词有:努力、长大、美好、快乐、生活、幸福、人生、远方、时光、散步。

通过以下柱状图,我们可以发现:在微信好友的签名信息中,正面积极的情感判断约占到55.56%,中立的情感判断约占到32.10%,负面消极的情感判断约占到12.35%。这个结果和我们通过词云展示的结果基本吻合,这说明在微信好友的签名信息中,约有87.66%的签名信息,传达出来都是一种积极向上的态度。
5. 好友位置
分析好友位置,主要通过提取Province和City这两个字段。Python中的地图可视化主要通过Basemap模块,这个模块需要从国外网站下载地图信息,使用起来非常的不便。
百度的ECharts在前端使用的比较多,虽然社区里提供了pyecharts项目,可我注意到因为政策的改变,目前Echarts不再支持导出地图的功能,所以地图的定制方面目前依然是一个问题,主流的技术方案是配置全国各省市的JSON数据。
这里我使用的是BDP个人版,这是一个零编程的方案,我们通过Python导出一个CSV文件,然后将其上传到BDP中,通过简单拖拽就可以制作可视化地图,简直不能再简单,这里我们仅仅展示生成CSV部分的代码:
def analyseLocation(friends):
headers = ['NickName','Province','City']
with open('location.csv','w',encoding='utf-8',newline='',) as csvFile:
writer = csv.DictWriter(csvFile, headers)
writer.writeheader()
for friend in friends[1:]:
row = {}
row['NickName'] = friend['NickName']
row['Province'] = friend['Province']
row['City'] = friend['City']
writer.writerow(row)下图是BDP中生成的微信好友地理分布图,可以发现:我的微信好友主要集中在宁夏和陕西两个省份。
6. 总结
这篇文章是我对数据分析的又一次尝试,主要从性别、头像、签名、位置四个维度,对微信好友进行了一次简单的数据分析,主要采用图表和词云两种形式来呈现结果。总而言之一句话,”数据可视化是手段而并非目的”,重要的不是我们在这里做了这些图出来,而是从这些图里反映出来的现象,我们能够得到什么本质上的启示,希望这篇文章能让大家有所启发。
以上是用Python爬了我的微信好友,他們是這樣的...的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Python:自動化,腳本和任務管理Apr 16, 2025 am 12:14 AM
Python:自動化,腳本和任務管理Apr 16, 2025 am 12:14 AMPython在自動化、腳本編寫和任務管理中表現出色。 1)自動化:通過標準庫如os、shutil實現文件備份。 2)腳本編寫:使用psutil庫監控系統資源。 3)任務管理:利用schedule庫調度任務。 Python的易用性和豐富庫支持使其在這些領域中成為首選工具。
 Python和時間:充分利用您的學習時間Apr 14, 2025 am 12:02 AM
Python和時間:充分利用您的學習時間Apr 14, 2025 am 12:02 AM要在有限的時間內最大化學習Python的效率,可以使用Python的datetime、time和schedule模塊。 1.datetime模塊用於記錄和規劃學習時間。 2.time模塊幫助設置學習和休息時間。 3.schedule模塊自動化安排每週學習任務。
 Python:遊戲,Guis等Apr 13, 2025 am 12:14 AM
Python:遊戲,Guis等Apr 13, 2025 am 12:14 AMPython在遊戲和GUI開發中表現出色。 1)遊戲開發使用Pygame,提供繪圖、音頻等功能,適合創建2D遊戲。 2)GUI開發可選擇Tkinter或PyQt,Tkinter簡單易用,PyQt功能豐富,適合專業開發。
 Python vs.C:申請和用例Apr 12, 2025 am 12:01 AM
Python vs.C:申請和用例Apr 12, 2025 am 12:01 AMPython适合数据科学、Web开发和自动化任务,而C 适用于系统编程、游戏开发和嵌入式系统。Python以简洁和强大的生态系统著称,C 则以高性能和底层控制能力闻名。
 2小時的Python計劃:一種現實的方法Apr 11, 2025 am 12:04 AM
2小時的Python計劃:一種現實的方法Apr 11, 2025 am 12:04 AM2小時內可以學會Python的基本編程概念和技能。 1.學習變量和數據類型,2.掌握控制流(條件語句和循環),3.理解函數的定義和使用,4.通過簡單示例和代碼片段快速上手Python編程。
 Python:探索其主要應用程序Apr 10, 2025 am 09:41 AM
Python:探索其主要應用程序Apr 10, 2025 am 09:41 AMPython在web開發、數據科學、機器學習、自動化和腳本編寫等領域有廣泛應用。 1)在web開發中,Django和Flask框架簡化了開發過程。 2)數據科學和機器學習領域,NumPy、Pandas、Scikit-learn和TensorFlow庫提供了強大支持。 3)自動化和腳本編寫方面,Python適用於自動化測試和系統管理等任務。
 您可以在2小時內學到多少python?Apr 09, 2025 pm 04:33 PM
您可以在2小時內學到多少python?Apr 09, 2025 pm 04:33 PM兩小時內可以學到Python的基礎知識。 1.學習變量和數據類型,2.掌握控制結構如if語句和循環,3.了解函數的定義和使用。這些將幫助你開始編寫簡單的Python程序。
 如何在10小時內通過項目和問題驅動的方式教計算機小白編程基礎?Apr 02, 2025 am 07:18 AM
如何在10小時內通過項目和問題驅動的方式教計算機小白編程基礎?Apr 02, 2025 am 07:18 AM如何在10小時內教計算機小白編程基礎?如果你只有10個小時來教計算機小白一些編程知識,你會選擇教些什麼�...


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3漢化版
中文版,非常好用

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

