
Python實作12種降維演算法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-04-12 22:55:131890瀏覽
大家好,我是Peter~
網路上關於各種降維演算法的資料參差不齊,同時大部分不提供原始碼。這裡有個GitHub 專案整理了使用Python 實作了11 種經典的資料抽取(資料降維)演算法,包括:PCA、LDA、MDS、LLE、TSNE 等,並附有相關資料、展示效果;非常適合機器學習初學者和剛入坑資料探勘的小夥伴。
為什麼要進行資料降維?
所謂降維,即用一組個數為d 的向量Zi 來代表個數為D 的向量Xi 所包含的有用信息,其中d
通常,我們會發現大部分資料集的維度都會高達成百乃至上千,而經典的MNIST,其維度都是64。

MNIST 手寫數字資料集
但在實際應用中,我們所用到的有用資訊卻不需要那麼高的維度,而且每增加一維所需的樣本數量呈指數級增長,這可能會直接帶來極大的「維度災難」;而資料降維就可以實現:
- 使得資料集更容易使用
- 確保變數之間彼此獨立
- 降低演算法計算運算成本
#去除雜訊一旦我們能夠正確處理這些信息,正確有效地進行降維,這將大大有助於減少計算量,進而提高機器運作效率。而資料降維,也常應用於文字處理、臉部辨識、圖片辨識、自然語言處理等領域。
資料降維原理
往往高維度空間的資料會出現分佈稀疏的情況,所以在降維處理的過程中,我們通常會做一些資料刪減,這些資料包括了冗餘的資料、無效資訊、重複表達內容等。
例如:現有一張1024*1024 的圖,除去中心50*50 的區域其它位置均為零值,這些為零的信息就可以歸為無用信息;而對於對稱圖形而言,對稱部分的資訊則可以歸類為重複資訊。
因此,大部分經典降維技術也是基於此內容而展開,其中降維方法又分為線性和非線性降維,非線性降維又分為基於核函數和基於特徵值的方法。
- 線性降維方法:PCA 、ICA LDA、LFA、LPP(LE 的線性表示)
- 非線性降維方法:
基於核函數的非線性降維方法-KPCA 、KICA、KDA
以特徵值為基礎的非線性降維方法(流型學習)-ISOMAP、LLE、LE、LPP、LTSA、MVU
哈爾濱工業大學電腦科技專業的在學碩士生Heucoder 則整理了PCA、KPCA、LDA、MDS、ISOMAP、LLE、TSNE、AutoEncoder、FastICA、SVD、LE、LPP 共12 種經典的降維演算法,並提供了相關資料、程式碼以及展示,以下將主要以PCA 演算法為例介紹降維演算法具體操作。
主成分分析(PCA)降維演算法
PCA 是一種基於從高維空間映射到低維空間的映射方法,也是最基礎的無監督降維演算法,其目標是向資料變化最大的方向投影,或是向重構誤差最小化的方向投影。它由 Karl Pearson 在 1901 年提出,屬於線性降維方法。與 PCA 相關的原理通常被稱為最大方差理論或最小誤差理論。這兩者目標一致,但過程重點則不同。
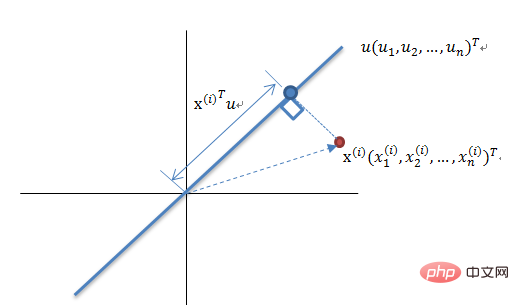
最大方差理論降維原理
將一組N 維向量降為K 維(K 大於0,小於N),其目標是選擇K 個單位正交基,各字段兩兩間COV(X,Y) 為0,而字段的方差則盡可能大。因此,最大方差即使得投影資料的方差被最大化,在這過程中,我們需要找到資料集Xmxn 的最佳的投影空間Wnxk、協方差矩陣等,其演算法流程為:
- 演算法輸入:資料集Xmxn;
- 按列計算資料集X 的平均值Xmean,然後令Xnew=X−Xmean;
- 求解矩陣Xnew 的協方差矩陣,並將其記為Cov;
- 計算協方差矩陣COV 的特徵值和對應的特徵向量;
- 將特徵值按照從大到小的排序,選擇其中最大的k 個,然後將其對應的k 個特徵向量分別作為列向量組成特徵向量矩陣Wnxk;
- 計算XnewW,即將資料集Xnew 投影到選取的特徵向量上,這樣就得到了我們需要的已經降維的數據集XnewW。
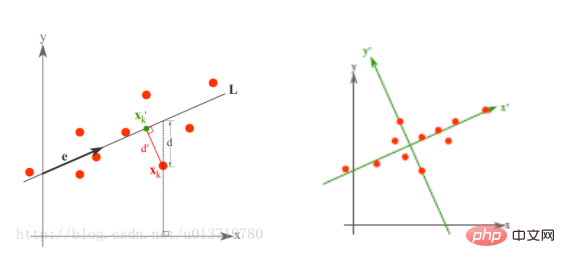
最小誤差理論降維原理
而最小誤差則是使得平均投影代價最小的線性投影,在這一過程中,我們則需要找到的是平方錯誤評價函數 J0(x0) 等參數。
- 主成分分析(PCA)程式碼實作
#關於PCA 演算法的程式碼如下:
from __future__ import print_function
from sklearn import datasets
import matplotlib.pyplot as plt
import matplotlib.cm as cmx
import matplotlib.colors as colors
import numpy as np
%matplotlib inline
def shuffle_data(X, y, seed=None):
if seed:
np.random.seed(seed)
idx = np.arange(X.shape[0])
np.random.shuffle(idx)
return X[idx], y[idx]
# 正规化数据集 X
def normalize(X, axis=-1, p=2):
lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis))
lp_norm[lp_norm == 0] = 1
return X / np.expand_dims(lp_norm, axis)
# 标准化数据集 X
def standardize(X):
X_std = np.zeros(X.shape)
mean = X.mean(axis=0)
std = X.std(axis=0)
# 做除法运算时请永远记住分母不能等于 0 的情形
# X_std = (X - X.mean(axis=0)) / X.std(axis=0)
for col in range(np.shape(X)[1]):
if std[col]:
X_std[:, col] = (X_std[:, col] - mean[col]) / std[col]
return X_std
# 划分数据集为训练集和测试集
def train_test_split(X, y, test_size=0.2, shuffle=True, seed=None):
if shuffle:
X, y = shuffle_data(X, y, seed)
n_train_samples = int(X.shape[0] * (1-test_size))
x_train, x_test = X[:n_train_samples], X[n_train_samples:]
y_train, y_test = y[:n_train_samples], y[n_train_samples:]
return x_train, x_test, y_train, y_test
# 计算矩阵 X 的协方差矩阵
def calculate_covariance_matrix(X, Y=np.empty((0,0))):
if not Y.any():
Y = X
n_samples = np.shape(X)[0]
covariance_matrix = (1 / (n_samples-1)) * (X - X.mean(axis=0)).T.dot(Y - Y.mean(axis=0))
return np.array(covariance_matrix, dtype=float)
# 计算数据集 X 每列的方差
def calculate_variance(X):
n_samples = np.shape(X)[0]
variance = (1 / n_samples) * np.diag((X - X.mean(axis=0)).T.dot(X - X.mean(axis=0)))
return variance
# 计算数据集 X 每列的标准差
def calculate_std_dev(X):
std_dev = np.sqrt(calculate_variance(X))
return std_dev
# 计算相关系数矩阵
def calculate_correlation_matrix(X, Y=np.empty([0])):
# 先计算协方差矩阵
covariance_matrix = calculate_covariance_matrix(X, Y)
# 计算 X, Y 的标准差
std_dev_X = np.expand_dims(calculate_std_dev(X), 1)
std_dev_y = np.expand_dims(calculate_std_dev(Y), 1)
correlation_matrix = np.divide(covariance_matrix, std_dev_X.dot(std_dev_y.T))
return np.array(correlation_matrix, dtype=float)
class PCA():
"""
主成份分析算法 PCA,非监督学习算法.
"""
def __init__(self):
self.eigen_values = None
self.eigen_vectors = None
self.k = 2
def transform(self, X):
"""
将原始数据集 X 通过 PCA 进行降维
"""
covariance = calculate_covariance_matrix(X)
# 求解特征值和特征向量
self.eigen_values, self.eigen_vectors = np.linalg.eig(covariance)
# 将特征值从大到小进行排序,注意特征向量是按列排的,即 self.eigen_vectors 第 k 列是 self.eigen_values 中第 k 个特征值对应的特征向量
idx = self.eigen_values.argsort()[::-1]
eigenvalues = self.eigen_values[idx][:self.k]
eigenvectors = self.eigen_vectors[:, idx][:, :self.k]
# 将原始数据集 X 映射到低维空间
X_transformed = X.dot(eigenvectors)
return X_transformed
def main():
# Load the dataset
data = datasets.load_iris()
X = data.data
y = data.target
# 将数据集 X 映射到低维空间
X_trans = PCA().transform(X)
x1 = X_trans[:, 0]
x2 = X_trans[:, 1]
cmap = plt.get_cmap('viridis')
colors = [cmap(i) for i in np.linspace(0, 1, len(np.unique(y)))]
class_distr = []
# Plot the different class distributions
for i, l in enumerate(np.unique(y)):
_x1 = x1[y == l]
_x2 = x2[y == l]
_y = y[y == l]
class_distr.append(plt.scatter(_x1, _x2, color=colors[i]))
# Add a legend
plt.legend(class_distr, y, loc=1)
# Axis labels
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
if __name__ == "__main__":
main()最終,我們將得到降維結果如下。其中,如果得到當特徵數 (D) 遠大於樣本數 (N) 時,可以使用一點小技巧來實現 PCA 演算法的複雜度轉換。
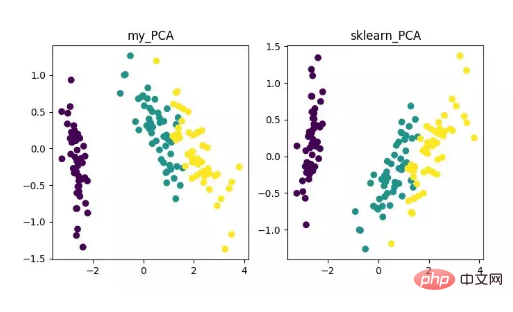
PCA 降維演算法展示
當然,這項演算法雖然經典且較為常用,其缺點也非常明顯。它可以很好的解除線性相關,但是面對高階相關性時,效果則較差;同時,PCA 實現的前提是假設資料各主特徵是分佈在正交方向上,因此對於在非正交方向上存在幾個方差較大的方向,PCA 的效果也會大打折扣。
其它降維演算法及程式碼位址
- KPCA(kernel PCA)
KPCA 是核技術與PCA 結合的產物,它與PCA 主要差異在於計算協方差矩陣時使用了核函數,也就是經過核函數映射之後的協方差矩陣。
引入核函數可以很好的解決非線性資料映射問題。 kPCA 可以將非線性資料映射到高維空間,在高維空間下使用標準 PCA 將其映射到另一個低維空間。
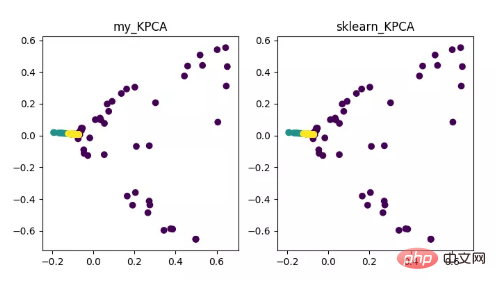
KPCA 降維演算法展示
程式碼位址:
https://github.com/heucoder/dimensionality_reduction_alo_codes/blob/master /codes/PCA/KPCA.py
- LDA(Linear Discriminant Analysis)
LDA 是一種可作為特徵抽取的技術,其目標是向最大化類間差異,最小化類內差異的方向投影,以利於分類等任務即將不同類別的樣本有效的分開。 LDA 可以提高資料分析過程中的運算效率,對於未能正規化的模型,可以降低維度災難帶來的過度擬合。
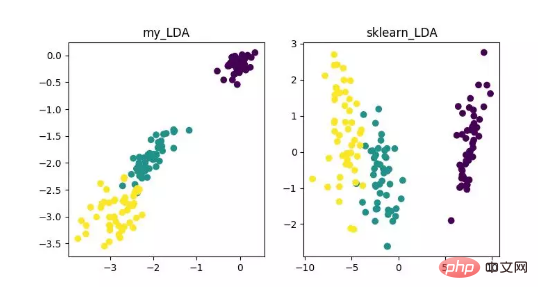
LDA 降維演算法展示
程式碼位址:
https://github.com/heucoder/dimensionality_reduction_alo_codes/tree/master /codes/LDA
- MDS(multidimensional scaling)
MDS 即多維標度分析,它是一種透過直覺空間圖表示研究對象的感知和偏好的傳統降維方法。此方法會計算任兩個樣本點之間的距離,使得投影到低維空間之後能夠保持這種相對距離從而實現投影。
由於 sklearn 中 MDS 是採用迭代優化方式,下面實現了迭代和非迭代的兩種。
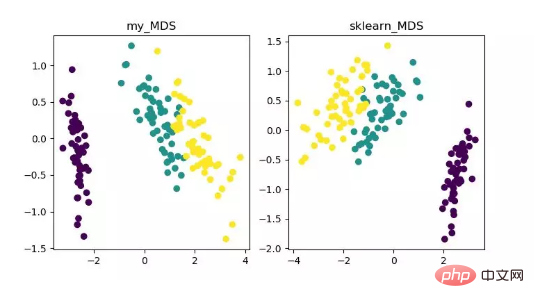
MDS 降維演算法展示
程式碼位址:
https://github.com/heucoder/dimensionality_reduction_alo_codes/tree/master /codes/MDS
- ISOMAP
Isomap 即等度量映射演算法,該演算法可以很好地解決MDS 演算法在非線性結構資料集上的弊端。
MDS 演算法是保持降維後的樣本間距離不變,Isomap 演算法則引進了鄰域圖,樣本只與其相鄰的樣本連接,計算出近鄰點之間的距離,然後在此基礎上進行降維保距。
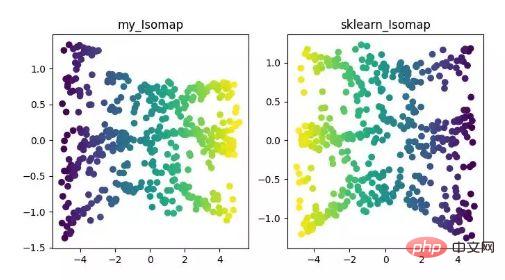
ISOMAP 降維演算法展示
程式碼位址:
https://github.com/heucoder/dimensionality_reduction_alo_codes/tree/master /codes/ISOMAP
LLE(locally linear embedding)LLE 即局部線性嵌入演算法,它是一種非線性降維演算法。這個演算法核心思想為每個點可以由與它相鄰的多個點的線性組合而近似重構,然後將高維資料投影到低維空間中,使其保持資料點之間的局部線性重構關係,即有相同的重構係數。在處理所謂的流形降維的時候,效果比 PCA 好得多。
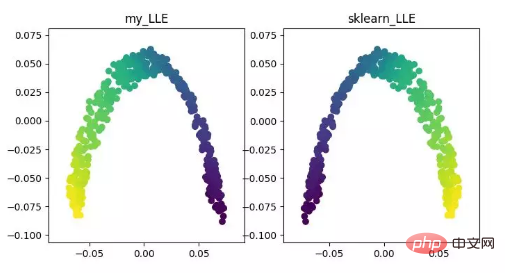
LLE 降維演算法展示
程式碼位址:
https://github.com/heucoder/dimensionality_reduction_alo_codes/tree/master/codes/LLE
- #t-SNE
t-SNE 也是一種非線性降維演算法,非常適用於高維度資料降維到2 維或3 維進行視覺化。它是一種以資料原有的趨勢為基礎,重建其在低緯度(二維或三維)下資料趨勢的無監督機器學習演算法。
下面的結果展示參考了原始程式碼,同時也可用 tensorflow 實作(無需手動更新參數)。
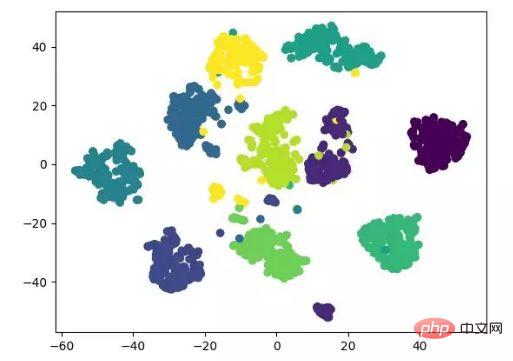
t-SNE 降維演算法展示
程式碼位址:
https://github.com/heucoder/dimensionality_reduction_alo_codes/tree /master/codes/T-SNE
- LE(Laplacian Eigenmaps)
LE 即拉普拉斯特徵映射,它與LLE 演算法有些相似,也是以局部的角度去建構資料之間的關係。它的直覺思想是希望相互間有關係的點(在圖中相連的點)在降維後的空間中盡可能的靠近;以這種方式,可以得到一個能反映流形的幾何結構的解。
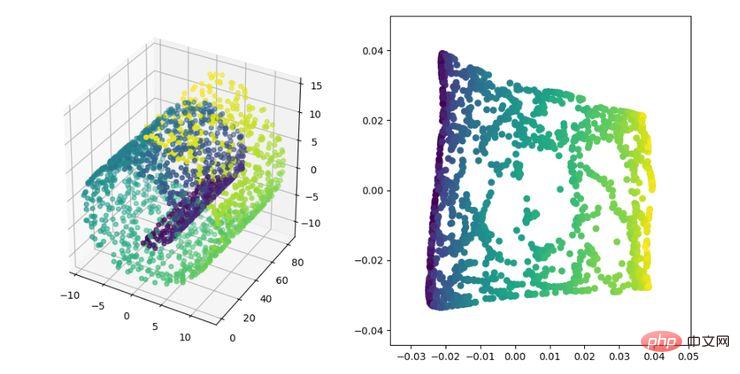
LE 降維演算法展示
程式碼位址:
https://github.com/heucoder/dimensionality_reduction_alo_codes/tree/master /codes/LE
- LPP(Locality Preserving Projections)
LPP 即局部保留投影演算法,其思路和拉普拉斯特徵映射類似,核心思想為通過最好的保持一個資料集的鄰居結構資訊來構造投影映射,但LPP 不同於LE 的直接得到投影結果,它需要解投影矩陣。
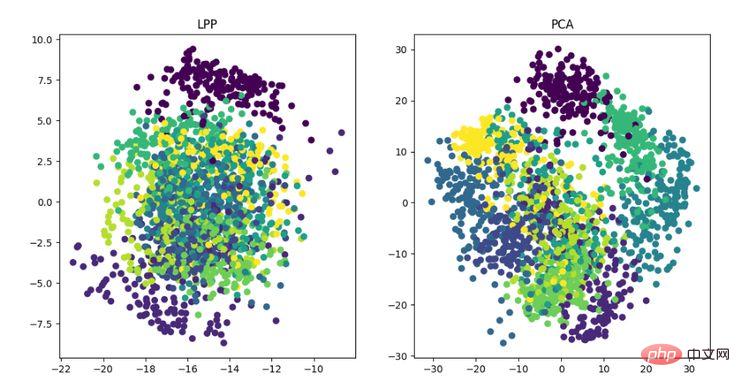
LPP 降維演算法展示
程式碼位址:
https://github.com/heucoder/dimensionality_reduction_alo_codes/tree/master /codes/LPP
- *《dimensionality_reduction_alo_codes》計畫作者簡介
Heucoder,目前是哈爾濱工業大學電腦科技在讀碩士生,主要活躍於網路領域,知乎暱稱為「超愛學習」,其github 主頁網址為:https://github.com/heucoder。
Github 專案位址:
https://github.com/heucoder/dimensionality_reduction_alo_codes
#以上是Python實作12種降維演算法的詳細內容。更多資訊請關注PHP中文網其他相關文章!