
sklearn 中的兩個半監督標籤傳播演算法 LabelPropagation和LabelSpreading

- 王林轉載
- 2023-04-12 19:28:041169瀏覽
標籤傳播演算法是一種半監督機器學習演算法,它將標籤分配給先前未標記的資料點。要在機器學習中使用這種演算法,只有一小部分範例具有標籤或分類。在演算法的建模、擬合和預測過程中,這些標籤被傳播到未標記的資料點。

LabelPropagation
LabelPropagation是一種在圖中尋找社群的快速演算法。它只使用網路結構作為指導來檢測這些連接,不需要預先定義的目標函數或關於群體的先驗資訊。標籤傳播透過在網路中傳播標籤並基於標籤傳播過程形成連結來實現。
接近的標籤通常會被賦予相同的標籤。單一標籤可以在密集連接的節點組中占主導地位,但在稀疏連接的區域中會遇到麻煩。標籤將被限制在一個緊密連接的節點組中,當演算法完成時,那些最終具有相同標籤的節點可以被視為相同連接的一部分。演算法使用了圖論,具體如下:-
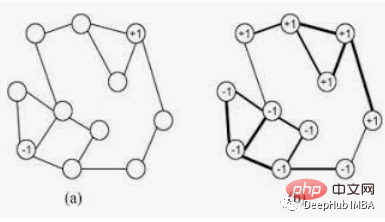
LabelPropagation演算法以下列方式運作:-
- ##每個節點都使用唯一的標籤進行初始化。
- 這些標籤透過網路傳播。
- 在每次傳播迭代中,每個節點都會將其標籤更新為最大鄰居數所屬的標籤。
- 當每個節點具有其鄰居的多數標籤時,標籤傳播演算法達到收斂。
- 如果達到收斂或使用者定義的最大迭代次數,則標籤傳播演算法停止。


 ##使用隨機數產生器隨機化資料集中70%的標籤。然後隨機標籤被分配-1:-
##使用隨機數產生器隨機化資料集中70%的標籤。然後隨機標籤被分配-1:-
 在對資料進行預處理之後,定義因變數和自變量,分別為y和X。 y變數是最後一列,X變數是剩下的所有部分:-
在對資料進行預處理之後,定義因變數和自變量,分別為y和X。 y變數是最後一列,X變數是剩下的所有部分:-
 #使用sklearn的LabelPropagation數來標記所有未標記的資料點:-
#使用sklearn的LabelPropagation數來標記所有未標記的資料點:-
 #準確率為發現它是76.9%。
#準確率為發現它是76.9%。
 #下面我們來看看另外一個演算法LabelSpreading。
#下面我們來看看另外一個演算法LabelSpreading。
LabelSpreading
LabelSpreading也是一種流行的半監督學習方法。建立一個連接訓練資料集中樣本的圖,並透過圖的邊緣傳播已知的標籤來標記未標記的範例。
LabelSpreading是由 Dengyong Zhou 等人在他們 2003 年題為「Learning with Local and Global Consistency」的論文中提出的。半監督學習的關鍵是一致性的先驗假設,這意味著:附近的點可能具有相同的標籤,並且同一結構上的點(通常稱為簇流形)很可能具有相同的標籤。
LabelSpreading可以認為是LabelPropagation的正規化形式。在圖論中,拉普拉斯矩陣是圖的矩陣表示,拉普拉斯矩陣的公式為:
L是拉普拉斯矩陣,D是度矩陣,A是鄰接矩陣。
下面是一個簡單的無向圖標記的例子和它拉普拉斯矩陣的結果

#本文將使用sonar資料集示範如何使用sklearn的LabelSpreading函數。
這裡的函式庫比上面的多,所以簡單解釋一下:
- Numpy執行數值計算並建立Numpy陣列
- Pandas處理資料
- #Sklearn執行機器學習操作
- Matplotlib和seaborn來視覺化數據,為視覺化資料提供統計資料
- Warning,用於忽略程式執行期間出現的警告
#導入完成後使用pandas將讀入資料集:

我使用seaborn創建了熱圖:-

先做一個就簡單的預處理,刪除具有高度相關性的列,這樣將列數從61 減少到58:






以上是sklearn 中的兩個半監督標籤傳播演算法 LabelPropagation和LabelSpreading的詳細內容。更多資訊請關注PHP中文網其他相關文章!